
Как разбить числовой ряд на интервалы в excel
При изучении величины, принимающей случайные значения (результатов физических измерений в серии экспериментов, экономических показателей, параметров технологических процессов и т.п.), мы имеем дело с выборками. Выборочное наблюдение – это способ наблюдения, при котором обследуется не вся совокупность значений изучаемой величины, а лишь часть ее, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При выборочном наблюдении обследованию подвергается определенная, заранее обусловленная часть совокупности, а результаты обследования распространяются на всю совокупность.
Ту часть единиц, которая отобрана для наблюдения, принято называть выборочной совокупностью или выборкой, а всю совокупность единиц, из которых производится отбор, – генеральной совокупностью.
Число единиц (элементов) статистической совокупности называется ее объемом. Объем генеральной совокупности обозначается N, а объем выборочной совокупности п.
Качество результатов выборочного наблюдения зависит от того, насколько состав выборки представляет генеральную совокупность, иначе говоря, от того, насколько выборка репрезентативна (представительна).
Элементами выборки (x1 х2, . хп) являются числовые значения, называемые вариантами, которые могут быть дискретными, т.е. изолированными (например, целыми числами), или могут принимать значения из некоторого интервала (а, b).
Вариационный ряд получается из выборки упорядочением по возрастанию (или убыванию) и подсчетом частоты каждого значения. Если вариационный ряд содержит значения признака и соответствующие ему частоты,то такой ряд носит название дискретный вариационный ряд. Если нам известно, что исследуемый показатель может принимать любые значения из некоторого интервала, то строим интервальный вариационный.
Удобнее всего ряды распределения анализировать с помощью их графического изображения, позволяющего судить о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Пример 2.1.
Известны следующие данные о результатах сдачи студентами экзамена (в баллах):
| 18 | 16 | 20 | 17 | 19 | 20 | 17 |
| 17 | 12 | 15 | 20 | 18 | 19 | 18 |
| 18 | 16 | 18 | 14 | 14 | 17 | 19 |
| 16 | 14 | 19 | 12 | 15 | 16 | 20 |
Необходимо построить ряд распределения числа студентов по баллу, представить графически результаты.
Введем данные в диапазоне A1: A29, в ячейку A1 введем текст «Балл» (рис.2.6).
Рисунок 2.6. Баллы успеваемости студентов
Определим наименьший и наибольший балл по выборке. Для этого введем в ячейках С1 и С2 соответственно введем формулы =МИН(A2:A29) и =МАКС(A2:A29). Получим значения 12 и 20 соответственно (рис.2.7).
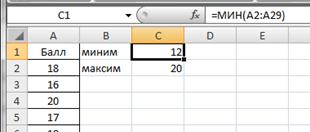
Рисунок 2.7. Минимальный и максимальный балл
Построим вариационный ряд. Для каждого значения необходимо подсчитать частоту. Так как значения признака (балл) отличаются на единицу, то можно воспользоваться следующим способом. В ячейку С4 введем формулу =С1, в С5 соответственно С4+1. Ячейку С5 протянем маркером заполнения (правый нижний угол ячейки) вниз до С12. Результаты представлены на рисунке 2.8.
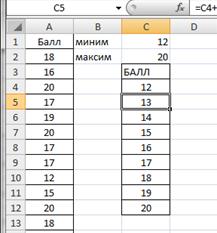
Рисунок 2.8. Значения признака
Вычислим частоту для каждого значения признака. В ячейку D4 введем формулу =СЧЕТЕСЛИ(A$2:A$29;C4) и протянем D4 маркером вниз до заполнения D12. В ячейке D13 просуммируем частоты с помощью формулы =СУММ(D4:D12).
Получим вариационный ряд (значения признака и соответствующие им частоты) на рисунке 2.9.
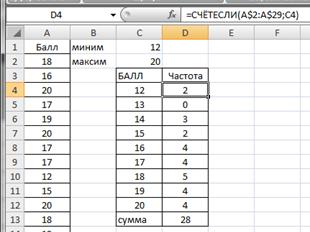
Рис.2.9. Частоты вариационного ряда
Вычислим частость (относительную частоту) для каждого значения признака. В ячейку Е4 введем формулу = D4/D$13. Протянем Е4 маркером заполнения вниз до Е12 (рис.2.10).
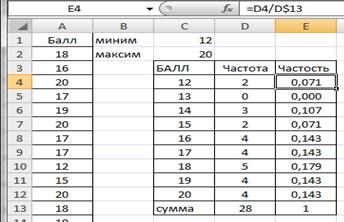
Рисунок 2.10. Частости ряда распределения
Вычислим накопленные частоты. В ячейку F4 введем формулу =D4, а в ячейку F5 – формулу = D5+F4. Протянем F5 маркером заполнения вниз до F12 (рис.2.11).
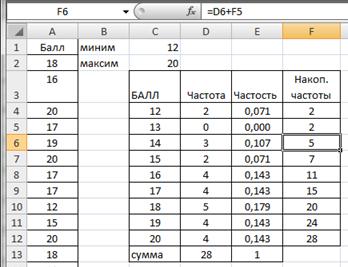
Рисунок 2.11. Накопленные частоты ряда
Построим эмпирическую функцию распределения, т.е. найдем наколенные частости. Выделим F4:F12 и маркером заполнения протянем вправо на соседний столбец (рис.2.12). В G4 получим формулу = Е4, в ячейке G5 формулу =Е5+ G4 и т.д.
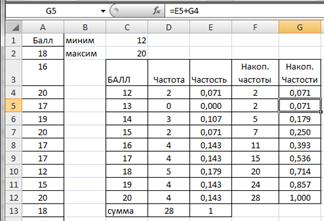
Рисунок 2.12. Накопленные частости ряда
Построим полигон распределения частот и частостей. Выделим диапазон ячеек С4:D12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частот представлен на рисунке 2.13.
Рисунок 2.13. Полигон распределения частот
Выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон Е4:Е12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частостей представлен на рисунке 2.14.
Рисунок 2.14. Полигон распределения частостей
Построим гистограмму распределения частостей, для чего выделим диапазон Е4:Е12, выберем тип диаграммы «Гистограмма». Щелкнем правой кнопкой в области диаграммы, выберем «Выбрать данные», выберете «Ряд» – «Изменить», левой кнопкой щелкнем в строке «Подписи оси Х» и выделим диапазон С4:С12 (рис.2.15).
Рисунок 2.15. Гистограмма распределения частостей
Построим кумуляту частостей, для чего выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон G4:G12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками». Кумулята представлена на рис.2.16.
Рисунок 2.16. Кумулята
Пример 2.2.
В таблице 2.7 представлены значения процентных ставок по кредитам по 30 коммерческим банкам.
Банковские процентные ставки
| № Банка | Процентная ставка, % |
| 1 | 20,3 |
| 2 | 17,1 |
| 3 | 14,2 |
| 4 | 11,0 |
| 5 | 17,3 |
| 6 | 19,6 |
| 7 | 20,5 |
| 8 | 23,6 |
| 9 | 14,6 |
| 10 | 17,5 |
| 11 | 20,8 |
| 12 | 13,6 |
| 13 | 24,0 |
| 14 | 17,5 |
| 15 | 15,0 |
| 16 | 21,1 |
| 17 | 17,6 |
| 18 | 15,8 |
| 19 | 18,8 |
| 20 | 22,4 |
| 21 | 16,1 |
| 22 | 17,9 |
| 23 | 21,7 |
| 24 | 18,0 |
| 25 | 16,4 |
| 26 | 26,0 |
| 27 | 18,4 |
| 28 | 16,7 |
| 29 | 12,2 |
| 30 | 13,9 |
Построим интервальный вариационный ряд. Для этого вычислим границы интервалов (карманов) с использованием формулы Стэрджесса.
Введем данные в диапазоне A1:A31 (рис.2.17). Определим максимальное и минимальное значения (ячейки С2 и С3 соответственно) так же как и в примере 2.1. Определим число интервалов по формуле Стэрджесса, для чего в ячейку С6 введем формулу =ЦЕЛОЕ(1+3,322*LOG10(30)) (рис.2.18).
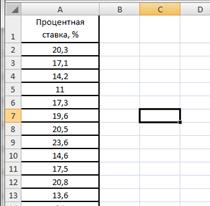
Рисунок 2.17. Процентные ставки банков

Рисунок 2.18. Число интервалов
Вычислим длину интервалов, для чего в ячейке С8 введем формулу =ОКРУГЛ((C3-C2)/C6;2) (рис.2.19).
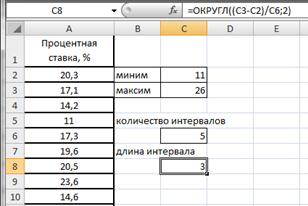
Рисунок 2.19. Длина интервала
Определим нижние и верхние границы интервалов (карманы), для чего в ячейке Е2 запишем формулу =С2, в ячейке Е3 запишем ==E2+$C$8. Протянем Е3 маркером заполнения вниз до Е7 (рис.2.20).
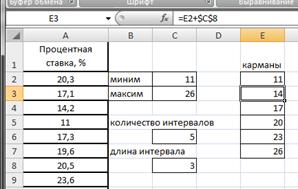
Рисунок 2.20. Границы интервалов
Подсчитаем частоты – в интервал считаем те значения, которые больше нижней границы интервала или равны ей и меньше верхней границы.
Воспользуемся функцией ЧАСТОТА. Для этого в ячейке F2 введем формулу =ЧАСТОТА(A2:A31;E2:E7). Протянем F2 маркером заполнения вниз до F8.
Формулу в этом примере необходимо ввести как формулу массива. Выделим диапазон F2:F8, нажмем клавишу F2, а затем нажмем клавиши CTRL+SHIFT+ВВОД (рис.2.21).
Если формула не будет введена как формула массива, отобразится только одно ее значение в ячейке F2.
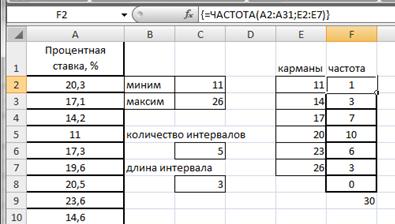
Рисунок 2.21. Частоты значений признака
Также можно воспользоваться средством Пакета анализа (Анализ данных в Office 2007) ГИСТОГРАММА (рис.2.22). Выберем входной интервал, интервал карманов, метки, интегральный процент, поместим результаты на этом же листе (укажем ячейку $H$2).
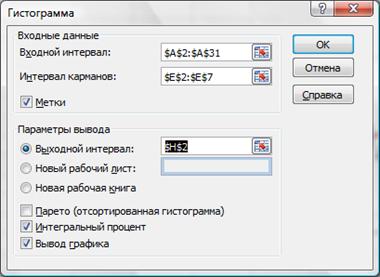
Рисунок 2.22. Построение гистограммы
Полученная гистограмма представлена на рис.2.23.
Рис.2.23. Гистограмма частот
Замечание. Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Вариационный ряд может быть:
– дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
– интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа – в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот
В реальных социально-экономических системах нельзя проводить активные эксперименты, поэтому данные обычно представляют собой наблюдения за происходящим процессом, например: курс валюты на бирже в течение месяца, урожайность пшеницы в хозяйстве за 30 лет, производительность труда рабочих за смену и т.д. Результаты наблюдений — это в общем случае ряд чисел, расположенных в беспорядке, который для изучения необходимо упорядочить (проранжи- ровать).
Операция, заключающаяся в расположении значений признака по возрастанию, называется ранжированием опытных данных.
После операции ранжирования опытные данные можно сгруппировать так, чтобы в каждой группе признак принимал одно и то же значение, которое называется вариантом (х,). Число элементов в каждой группе называется частотой варианта («,).
Размахом вариации называется число

где хтах — наибольший вариант;
x min — наименьший вариант.
Сумма всех частот равна определенному числу л, которое называется объемом совокупности:

Отношение частоты данного варианта к объему совокупности называется относительной частотой, или частостью, этого варианта:

Последовательность вариант, расположенных в возрастающем порядке, называется вариационным рядом (вариация — изменение).
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариант с соответствующими частотами и (или) частостями.
Пример 1. В результате тестирования группа из 24 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 4, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 1, 2, 1, 2. Построить дискретный вариационный ряд.
Решение. Проранжируем исходный ряд, подсчитаем частоту и частость вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4.
В результате получим дискретный вариационный ряд (табл. 3.10).
Ранжированный ряд успеваемости
Число студентов, л,
Относительная частота, А
В Excel проранжируем исходный ряд. Для этого введем все данные в диапазон А1 :А24 и воспользуемся кнопкой Щ (Сортировка по возрастанию).
Подсчитаем частоту и частость вариант. Построим таблицу в диапазоне D2:G7 (рис. 3.13).

Рис. 3.13. Контекстное меню строки состояния
Рассмотрим два варианта подсчета частот:
- 1) выделим диапазон, в котором находятся нули. Щелкнем в нижней правой части окна Excel правой кнопкой мыши и выберем в контекстном меню вид итога, который по умолчанию будет появляться в итоговой строке при выделении произвольного диапазона (см. рис. 3.13) — количество. Таким образом, последовательно выделяя диапазоны с одинаковыми значениями вариант, мы получим все частоты;
- 2) выполним команду Сервис — Анализ данных — Гистограмма. Заполним диалоговое окно в соответствии с рис. 3.14.

Рис. 3.14. Диалоговое окно инструмента пакета анализа «Гистограмма»
В результате получим таблицу с частотами вариантов и соответствующий график (рис. 3.15).

Рис. 3.15. Результаты применения инструмента «Гистограмма)
Найдем объем выборки, заполнив все частоты вариант в диапазоне ЕЗ:Е7, выделим его левой кнопкой мыши и щелкнем по кнопке ? (автосумма).
В ячейку F3 введем формулу «=ЕЗ/$Е$8», за маркер заполнения (крест в правом нижнем углу ячейки) с помощью мыши скопируем до F7 и выберем кнопку автосумма, в результате получим частоты вариантов и их сумму (1). В ячейку G3 введем частоту варианта 0 — цифру 6 (или ссылку на ячейку, ее содержащую — ЕЗ), в ячейку G4 введем формулу «=G3+E4» и скопируем ее до ячейки G7, в результате получим накопленные частоты. Таким образом, мы получили дискретный вариационный ряд. Естественно, частоты необходимо округлить, но таким образом, чтобы их сумма равнялась 1. Для этого выделим левой кнопкой мыши диапазон частот (F3:F7), щелкнув по правой кнопке, откроем контекстное меню и выполним команду Формат ячеек — Числовой — Число знаков 3 — ОК. Преобразовав обозначения, получим дискретный вариационный ряд, представленный в табл. 3.11.
Интервальные графики (статистические диаграммы) представляют собой полезный инструмент для анализа частотных данных, предлагая пользователям возможность сортировать данные в группы (называемые рядами) на визуальном графике, аналогичном гистограмме. В этой статье пошагово описано как создать статистическую диаграмму и выполнить её настройку в Microsoft Excel.
Если вы хотите создавать статистические диаграммы в Excel, вам нужно будет использовать Excel 2016 или более позднюю версию. В более ранних версиях Office (Excel 2013 и до неё) эта функция отсутствует.
Как создать статистическую диаграмму в Excel
Говоря простым языком, частотный анализ данных состоит в том, что берутся собранные результаты и определяется, как часто встретились те или иные значения. В качестве примера можно взять результаты тестов учащихся и посчитать, в каких диапазонах чаще всего встречаются полученные студентами результаты.
Статистические диаграммы позволяют легко получать данные такого рода и визуализировать их в диаграмме Excel.
Начните с того, что введите данные в Microsoft Excel и выделите данные, на основе которых будет строится интервальный график. Вы можете выбрать данные вручную или кликните на любую ячейку в нужном диапазоне и нажмите Ctrl+A на клавиатуре.


В результате в вашу таблицу Excel будет вставлена гистограмма. Excel попытается параметры для данных, например, ширину интервалов, но вам может потребоваться внести изменения вручную после вставки диаграммы.
Форматирование гистограммы
Excel попытается определить интервалы и тип представления данных, но возможно вам придётся самостоятельно это настроить под ваши нужды. К примеру, в моём случае данные разбиты на 3 интервала, но я могу выбрать разбивку на интервалы с шагом в 10, либо отобразить данные по категориям. Рассмотрим это на конкретных примерах.
Кликните правой кнопкой мыши по надписям осей и выберите «Формат оси…»:

В открывшемся окне справа «Формат оси» выберите интервалы «По категориям»:

Теперь вы можете видеть каждое значение — в нашем случае это результаты тестов каждого из учеников.
Если нужен интервальный график, но с настраиваемой длиной интервала, то выберите вариант «Длина интервала» и установите нужную длину, например, 10:

Диапазоны нижней оси начинаются с наименьшего числа. Например, первая группа ячеек отображается как «[27, 37]», а самый большой диапазон заканчивается «[97, 107]», несмотря на то, что максимальный результат теста равен 100.
Вы можете выбрать определённое количество интервалов, в этом случае из максимального значения будет вычтено минимальное и полученный результат поделён на указанное количество интервалов — в результате интервалы могут заканчиваться на дробные числа:

Вы можете собрать все данные, которые больше определённого значения, в одном интервале, независимо от его длины. Для этого поставьте флажок «Выход за верхнюю границу интервала» и укажите значение, выше которого все результаты будут помещены в один интервал:

Аналогично в один интервал можно собрать все значения, ниже определённой величины, для этого поставьте флажок «Выход за нижнюю границу интервала» и укажите значение, ниже которого все результаты будут помещены в один интервал:

Эти опции работают в сочетании с другими форматами группировки интервалов, такими как ширина или количество интервалов.
Вы также можете вносить косметические изменения в вид интервального графика, включая замену заголовков и меток осей — для этого дважды кликните по области, которую вы хотите отредактировать. Дальнейшие изменения в тексте и цветах и параметрах панели можно выполнить, щёлкнув правой кнопкой мыши саму диаграмму и выбрав опцию «Форматировать область диаграммы».

Стандартные параметры форматирования диаграммы, в том числе изменение границ и параметров столбцов, появятся в меню «Формат области диаграммы» справа.
Если вас интересуют вопросы редактирования внешнего вида, то они более подробно рассмотрены в статье «Как сделать гистограмму в Microsoft Excel», где показано, как применять готовые стили или вручную настроить любые параметры графиков, в том числе формат текста.
Добрый день.
Подскажите пожалуйста, как можно разбить выборку значений на равные интервалы для последующего анализа?
Выборка из значений в диапазоне от 163 до 192
Количество значений 25
Размах = 29 (разница между макс и мин)
Интервалов = 6 (по формуле К = 1 + 3,322 * LOG(N))
Шаг = 4,95 (отношение 29 / 6)
Шаг (альтернативный вариант) = (192 - 163) / 6 = 4,83
Точность условно принята 0,1, можно и 0,01 или просто 1.
И с учетом шага и точности интервалы выстроились следующим образом:
1-й кл начало 160,58
1-й кл конец 165,52
2-й кл. начало 165,62
2-й кл. конец 170,35
3-й кл. начало 170,45
3-й кл. конец 175,18
4-й кл начало 175,28
4-й кл конец 180,02
5-й кл. начало 180,12
5-й кл. конец 184,85
6-й кл. начало 184,95
6-й кл. конец 189,68
Но не 192 как было надо. При чем, если снизить точность с 0,1 до 1, то все равно не выходит на границы диапазона.
Возможно есть альтернативные способы разбивки массива данных на равные интервалы?
В поиске на форуме подобной темы не нашел.
Заранее спасибо.
Добрый день.
Подскажите пожалуйста, как можно разбить выборку значений на равные интервалы для последующего анализа?
Выборка из значений в диапазоне от 163 до 192
Количество значений 25
Размах = 29 (разница между макс и мин)
Интервалов = 6 (по формуле К = 1 + 3,322 * LOG(N))
Шаг = 4,95 (отношение 29 / 6)
Шаг (альтернативный вариант) = (192 - 163) / 6 = 4,83
Точность условно принята 0,1, можно и 0,01 или просто 1.
И с учетом шага и точности интервалы выстроились следующим образом:
1-й кл начало 160,58
1-й кл конец 165,52
2-й кл. начало 165,62
2-й кл. конец 170,35
3-й кл. начало 170,45
3-й кл. конец 175,18
4-й кл начало 175,28
4-й кл конец 180,02
5-й кл. начало 180,12
5-й кл. конец 184,85
6-й кл. начало 184,95
6-й кл. конец 189,68
Но не 192 как было надо. При чем, если снизить точность с 0,1 до 1, то все равно не выходит на границы диапазона.
Возможно есть альтернативные способы разбивки массива данных на равные интервалы?
В поиске на форуме подобной темы не нашел.
Заранее спасибо. Gorbunov
Возможно есть альтернативные способы разбивки массива данных на равные интервалы?
В поиске на форуме подобной темы не нашел.
Заранее спасибо. Автор - Gorbunov
Дата добавления - 15.11.2017 в 12:30
Здравствуйте.
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
Здравствуйте.
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42? Pelena
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
Это условный пример, просто цифры, приложил их в файле Excel:
184 182 182 180 177
179 173 179 192 173
190 163 177 186 170
178 185 173 179 165
179 173 179 166 170
Но я понял Вас, сейчас посмотрю, логичное замечание. Не обратил внимание, это статистические формулы из книжки (Плохинский Н.А. "Биометрия" [1970]).
Равномерные интервалы можно расcчитывать так:
1. Вычисляем размах класса К. К=(макс-мин)/кол-во классов.
2. Начало 1го класса= мин.знач-К/2.
3.Конец 1го класса= мин.знач+К/2-сигма, где сигма - принятая точность измерений (1, 0,1, 0,01 и т.п.)
4. 2й и последующие классы расcчитываем как:
начало=конец предыдущего +сигма,
конец=полученное начало данного класса +размах класса-сигма.
5. Распределяем данные, строим диаграмму.
Таким образом, вы учитываете возможность, что есть еще меньшее значение, не попавшее в вашу выборку.
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
Это условный пример, просто цифры, приложил их в файле Excel:
184 182 182 180 177
179 173 179 192 173
190 163 177 186 170
178 185 173 179 165
179 173 179 166 170
Но я понял Вас, сейчас посмотрю, логичное замечание. Не обратил внимание, это статистические формулы из книжки (Плохинский Н.А. "Биометрия" [1970]).
Равномерные интервалы можно расcчитывать так:
1. Вычисляем размах класса К. К=(макс-мин)/кол-во классов.
2. Начало 1го класса= мин.знач-К/2.
3.Конец 1го класса= мин.знач+К/2-сигма, где сигма - принятая точность измерений (1, 0,1, 0,01 и т.п.)
4. 2й и последующие классы расcчитываем как:
начало=конец предыдущего +сигма,
конец=полученное начало данного класса +размах класса-сигма.
5. Распределяем данные, строим диаграмму.
Таким образом, вы учитываете возможность, что есть еще меньшее значение, не попавшее в вашу выборку. Gorbunov
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
Это условный пример, просто цифры, приложил их в файле Excel:
184 182 182 180 177
179 173 179 192 173
190 163 177 186 170
178 185 173 179 165
179 173 179 166 170
Но я понял Вас, сейчас посмотрю, логичное замечание. Не обратил внимание, это статистические формулы из книжки (Плохинский Н.А. "Биометрия" [1970]).
Равномерные интервалы можно расcчитывать так:
1. Вычисляем размах класса К. К=(макс-мин)/кол-во классов.
2. Начало 1го класса= мин.знач-К/2.
3.Конец 1го класса= мин.знач+К/2-сигма, где сигма - принятая точность измерений (1, 0,1, 0,01 и т.п.)
4. 2й и последующие классы расcчитываем как:
начало=конец предыдущего +сигма,
конец=полученное начало данного класса +размах класса-сигма.
5. Распределяем данные, строим диаграмму.
Таким образом, вы учитываете возможность, что есть еще меньшее значение, не попавшее в вашу выборку. Автор - Gorbunov
Дата добавления - 15.11.2017 в 13:35
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
А, нет, у меня все логично было, конец первого интервала (который впоследствии используется для итерационного процесса) рассчитывается на основе минимального значения 163.
Начало первого интервала берет больше шаг для того, чтобы учесть возможные значения, не попавшие в выборку.
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
А, нет, у меня все логично было, конец первого интервала (который впоследствии используется для итерационного процесса) рассчитывается на основе минимального значения 163.
Начало первого интервала берет больше шаг для того, чтобы учесть возможные значения, не попавшие в выборку. Gorbunov
Не совсем понятно, почему, минимальное значение 163, а начало первого диапазона 160,58? Если это правильно, то почему последнее число должно быть ровно 192, а не 189,58 или, скажем, 194,42?
А, нет, у меня все логично было, конец первого интервала (который впоследствии используется для итерационного процесса) рассчитывается на основе минимального значения 163.
Начало первого интервала берет больше шаг для того, чтобы учесть возможные значения, не попавшие в выборку. Автор - Gorbunov
Дата добавления - 15.11.2017 в 13:46
- дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
- интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа - в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Любой ряд распределения характеризуется двумя элементами:
- варианта (хi) – это отдельные значения признака единиц выборочной совокупности. Для вариационного ряда варианта принимает числовые значения, для атрибутивного – качественные (например, х=«государственный служащий»);
- частота (ni) – число, показывающее, сколько раз встречается то или иное значение признака.
Вариационный ряд называется интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Интервальный ряд может строиться как с интервалами равной длины (равноинтервальный ряд) так и с неодинаковыми интервалами, если это диктуется условиями статистического исследования. Например, может рассматриваться ряд распределения доходов населения со следующими интервалами: формуле Стерджесса:
k=1+3,322lg(n),
где k – число интервалов, n – объем выборки. (Конечно, формула обычно дает число дробное, а в качестве числа интервалов выбирается ближайшее целое к полученному число.)
Пример 1. Имеются данные о выбросах загрязняющих веществ из 50 источников:

Составить равноинтервальный ряд, построить гистограмму
Решение
Алгоритм построения равноинтервального ряда:
1) Внесем массив данных в лист Excel, он займет диапазон А1:J5
2) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
3) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
4) Поскольку число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.1. Пример 1. Построение равноинтервального ряда

5) Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10.
6) Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
7) Зададим массив интервалов, указывая для каждого из 7 интервалов верхнюю границу. Для этого в ячейке Е8 вычислим верхнюю границу первого интервала, введя формулу =B8+B11; в ячейке Е9 верхнюю границу второго интервала, введя формулу =E8+B11. Для вычисления оставшихся значений верхних границ интервалов зафиксируем номер ячейки В11 в введенной формуле при помощи знака $, так что формула в ячейке Е9 примет вид =E8+B$11, и скопируем содержимое ячейки Е9 в ячейки Е10-Е14. Последнее полученное значение равно вычисленному ранее в ячейке В9 максимальному значению в выборке.
Рис.1.2. Пример 1. Построение равноинтервального ряда

8) Теперь заполним массив «карманов» при помощи функции ЧАСТОТА. Поскольку результатом является столбец частот, введение функции следует завершить нажатием сочетания клавиш CTRL+SHIFT+ENTER.
Рис.1.3. Пример 1. Построение равноинтервального ряда

По полученному вариационном ряду построим гистограмму: выделим столбец частот и выберем на вкладке «Вставка» «Гистограмма». Получив гистограмму, изменим в ней подписи горизонтальной оси на значения в диапазоне интервалов, для этого выберем опцию «Выбрать данные» вкладки «Конструктор». В появившемся окне выберем команду «Изменить» для раздела «Подписи горизонтальной оси» и введем диапазон значений варианты, выделив его «мышью».
Читайте также: