
Как построить авторегрессионную модель в excel
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» - «Диаграмма» - «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».

"Странный этот мир, где двое смотрят на одно и то же, а видят полностью противоположное." © Агата Кристи
Реклама

MS Office и VBA Рубрика содержит интересные решения, малоизвестные функции и возможности, надстройки и макросы, в общем, все то, что может сделать вашу работу в пакете программ MS Office (в первую очередь - Excel, Word, Access) более эффективной.
Авторегрессия - моделирование и прогнозирование в Excel
5.0 (10) | 31527 | 0

Урок по построению линейной авторегрессионной модели первого-третьего порядков для динамических рядов с целью прогнозирования.
Что такое авторегрессия?
В предыдущей статье о линейной регрессии мы попытались разобраться в том как выразить зависимость итогового показателя Y от влияющих факторов с помощью линейной модели.
А что если показать зависимость Y от самого себя, вернее от того каков был Y в прошлом периоде (день, месяц, год и т.п.)? Именно к этому сводится суть авторегрессионной модели, то есть, вполне рационально можно предположить практически для любого показателя, что его текущий уровень в какой-то мере зависит от того какой он был раньше, например, тот же уровень ВВП зависит от того каков был его показатель в прошлом году. Именно поиск этой зависимости позволяет строить довольно точные модели, по которым очень легко сделать прогноз.
Структура модели
где a0 — постоянная - коэффициент описывающий ситуацию прохождение влияющих факторов через начало координат, то есть показывает каким будет итог модели в случае, когда влияющие факторы равны нулю;
ai — коэффициенты, которые описывают степень зависимости итогового Y от влияющих факторов, в данном случае, от того каким был Y в прошлом периоде регрессии;
Yi-1 — влияющие факторы, которые в данном случае и есть итоговый Y, но тот, каким он был раньше.
Ɛi — случайная компонента или как еще ее принято называть погрешность модели (по сути, это разница между расчетным значением модели за известные периоды и между самими известными значениями, то есть Yрасч. - Y).
AR I - Авторегрессия первого порядка
Как видно из формулы выше, линейная модель авторегрессии первого порядка состоит только из одного влияющего фактора, а именно из Y-1, то есть изучается наиболее тесная зависимость только от того каким был итоговый показатель периодом с шагом назад.
Рассмотрим построение модели с помощью "пакета анализа" в эксель (вся процедура и поочередность шагов аналогичны описанным в статье Линейная регрессия в Excel через Анализ данных) на примере ряда динамики ВВП Украины с 2004 по 2012 гг.

Исходные данные предварительно нужно подготовить, а именно прописать x(Yi-1) указав предыдущий Y - это, как мы уже выяснили, и будет нашим влияющим фактором. Таким образом наша совокупность, то есть динамический ряд который будет использоваться для регрессии сократился на одну позицию (обратите внимание на столбец t), то есть с 2005 по 2012 гг.
Далее в экселе активируем вкладку "Данные" и нажимаем "Анализ данных", указываем диапазон исходных данных по примеру как на скриншоте выше и жмем кнопку ОК. (Если по указанному пути нет кнопки "Анализ данных", то пакет анализа нужно активировать, как это сделать описано в статье Линейная регрессия в Excel через Анализ данных)

Результаты расчетов пакет анализа выдает нам на новом листе (если в настройках не было указано иначе), первоочередные по важности ячейки выделил желтым цветом, и из этих данных собираем модель, подставляя в уравнение общего вида рассчитанные коэффициенты:
Возвращаемся в нашу табличку с исходными данными и подставляем полученное уравнение в столбец в качестве формулы, таким образом, получаем расчетные значения по модели, что мы и сделали в столбце Y(расчетный), протягивая формулу на период ниже, получаем прогноз (в табличке строка выделена желтым).
Сравнить реальные данные с смоделированными можно с помощью графика:

AR II - Авторегрессия второго порядка
Модель авторегрессии второго порядка отличается от первой тем, что она включает в себя еще один влияющий фактор Yi-2, то есть показывается зависимость от того каким был Y не только один период назад, но и от того каким он был два периода назад. Порой это позволяет выявить большую взаимосвязь и соответственно построить более точный прогноз.
Все расчеты проводятся аналогично описанию в авторегрессии первого порядка, за той лишь разницей что теперь два столбца с влияющими факторами. Также стоит обратить внимание на то что на этот раз диапазон динамического ряда исходных данных используемых для построения модели сократится не на один период, а уже на два (обратите внимание на столбец t)

В нашем случае, полученная модель Y=151395,987+0,724*x1+0,32*x2 или Y=151395,987+0,724*Yi-1+0,32*Yi-2, имеет показатель детерминации R 2 ниже чем у модели первого порядка (0,927 против 0,94) да и среднее отклонение у нее больше (64 837,91 против 58 139,90), что значит что модель первого порядка более точная. Это может быть связано с тем, что диапазон исходных данных достаточно мал, чтобы его сокращение на один период имело значительные последствия для точности модели.

AR III - Авторегрессия третьего порядка
Модель авторегрессии третьего порядка наиболее тесно описывает зависимость от того каким был итоговый показатель раньше, так как в качестве влияющих факторов используется три отправные точки - каким Y был 1 период назад, 2 периода назад и 3 периода назад. То есть, она больше актуальна для анализа тех сфер деятельности, где полученный результат влияет на размер долгосрочных инвестиций, к примеру - ВВП, доходы по отраслям, продажи крупных корпораций и т.п.
В то же время требования к размаху исследуемого динамического ряда у этой модели выше - так как диапазон исходных данных сокращается на три периода, то чтобы не пострадало качество модели, необходимо расширять исследуемый период.
Необходимые манипуляции для построения модели и прогноза аналогичны тому, что мы проделывали выше и включают в себя предварительную подготовку данных и обработку их пакетом анализа.

В нашем случае, коэффициент детерминации R 2 наиболее низкий (0,89), да и среднее отклонение больше чем в модели первого порядка, опять таки, это обьясняется тем, что исследуемый период достаточно короткий, чтобы его уменьшение давало значительное влияние на качество построения модели.

Итоги
1. Получение высококачественной модели с адекватным прогнозом при минимуме временных затрат и требований к исходным данным.
1. Прогноз по исходным данным возможен только на один период вперед. Если нужно сделать прогноз на более длительный срок, то в качестве влияющих факторов для расчета придется брать не реально существующий Y, а тот который рассчитан по модели, что в итоге даст прогноз на прогнозе, а значит адекватность такого прогноза, как минимум, в два раза меньше.
2. С увеличением разрядности авторегрессии возникает необходимость расширять диапазон исходных данных.
О сайте
"Понемногу обо всем и все, о немногом" - именно такой слоган, по-видимому, является наилучшим определением тематики блога. Здесь пишу о том, что для меня интересно или важно, собственно, поэтому разброс тематик очень широк – от размышлений на философские темы и смешных историй, до конкретных инструкций или анализа событий.
Правда, помимо общих тематик, которые есть почти на каждом личном блоге, стоит выделить специализированные рубрики блога, которые будут полезны и интересны вебмастерам, программистам, дизайнерам, офисным работникам и пользователям ПК, желающим повысить свои навыки и уровень знаний. Подробнее о спецрубриках
Записки вебмастера – рубрика, которая призвана собрать коллекцию полезных скриптов и авторских решений, интересных особенностей и стандартов верстки, решение вопросов юзабилити и функционала, полезных ресурсов и программ.
Вопрос дизайна – это актуальные тренды, пошаговые и видео-уроки в фотошопе, необходимые плагины для фоторедакторов, векторные и PSD исходники, PNG иконки и GIF анимации, кириллические шрифты с засечками и без засечек, заливки (паттерны) и градиенты.
Мой ПК – каждая статья в этой рубрике направлена на то, чтобы узнать свой компьютер лучше. Здесь можно будет почитать о системных процессах и редактировании системного реестра, о способах защитить личные данные и компьютер в целом, о настройке локальной сети и подключениях к сети интернет, обзор ряда программ, которые делают работу за компьютером удобнее, быстрее и приятнее.
MS Office и VBA – эта рубрика содержит интересные решения, малоизвестные функции и возможности, надстройки и макросы, в общем, все то, что может сделать вашу работу в пакете программ MS Office (в первую очередь - Excel, Word, Access, PowerPoint) более эффективной.
Прочие офисные программы – рубрика о программах для ведения учета (конфигурации, платформы, внешние отчеты для 1C), сдачи отчетности (MeDoc, БестЗвіт) и статистического анализа данных (SPSS), также здесь можно найти обзоры программного обеспечения для работы с периферийными устройствами. Свернуть
P.S. В своих постах я не претендую на абсолютность точки зрения, поэтому всегда рад диалогу с читателями, посредством комментариев или любым из доступных социальных сервисов
"Странный этот мир, где двое смотрят на одно и то же, а видят полностью противоположное." © Агата Кристи
Реклама
MS Office и VBA Рубрика содержит интересные решения, малоизвестные функции и возможности, надстройки и макросы, в общем, все то, что может сделать вашу работу в пакете программ MS Office (в первую очередь - Excel, Word, Access) более эффективной.
Линейная регрессия в Excel через Анализ данных
4.9 (49) | 120648 | 2

Научимся строить линейную регрессионную модель с несколькими влияющими факторами в Эксель всего в несколько кликов с помощью встроенного Пакета анализа.
Что такое линейная регрессионная модель и зачем это нужно
Это наиболее распространенный способ показать зависимость какой-то переменной от других, например, как зависит уровень ВВП от величины иностранных инвестиций или от кредитной ставки Нацбанка или от цен на ключевые энергоресурсы.
Моделирование позволяет показать величину этой зависимости (коефициенты), благодаря которым можно делать непосредственно прогноз и осуществлять какое-то планирование, опираясь на эти прогнозы. Также, опираясь на регрессионный анализ, можно принимать управленческие решения направленные на стимулирование приоритетных причин влияющих на конечный результат, собственно модель и поможет выделить эти приоритетные факторы.
Общий вид модели линейной регрессии:
где a — параметры (коэффициенты) регрессии, x — влияющие факторы, k — количество факторов модели.
Исходные данные
Среди исходных данных нам необходим некий набор данных, который бы представлял из себя несколько последовательных или связанных между собой величин итогового параметра Y (например, ВВП) и такое же количество величин показателей, влияние которых мы изучаем (например, иностранные инвестиции).
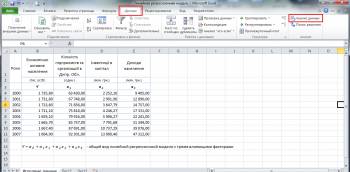
На рисунке выше показана таблица с этими самыми исходными данными, в качестве Y выступает показатель экономически активного населения, а количество предприятий, размер инвестиций в капитал и доходов населения - это влияющие факторы, то бишь иксы.
По рисунку также можно сделать ошибочный вывод, что речь в моделировании может идти только о динамических рядах, то есть моментным рядам зафиксированных последовательно во времени, но это не так, с тем же успехом можно моделировать и в разрезе структуры, например, величины указанные в таблице могут быть разбиты не годам, а по областям.
Для построения адекватных линейных моделей желательно чтобы исходные данные не имели сильных перепадов или обвалов, в таких случаях желательно проводить сглаживание, но о сглаживании поговорим в следующий раз.
Пакет анализа
Параметры модели линейной регрессии можно рассчитать и вручную с помощью Метода наименьших квадратов (МНК), но это довольно затратно по времени. Немного быстрее это можно посчитать по этому же методу с помощью применения формул в Excel, где сами вычисления будет делать программа, но проставлять формулы все равно придется вручную.
В Excel есть надстройка Пакет анализа, который является довольно мощным инструментом в помощь аналитику. Этот инструментарий, помимо всего прочего, умеет рассчитывать параметры регрессии, по тому же МНК, всего в несколько кликов, собственно, о том как этим инструментом пользоваться дальше и пойдет речь.
Активируем Пакет анализа
По умолчанию эта надстройка отключена и в меню вкладок вы ее не найдете, поэтому пошагово рассмотрим как ее активировать.
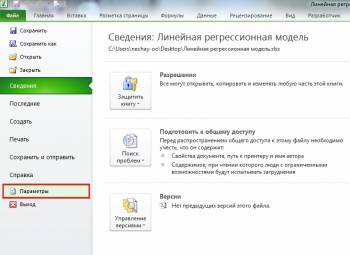
В эксель, слева вверху, активируем вкладку Файл, в открывшемся меню ищем пункт Параметры и кликаем на него.
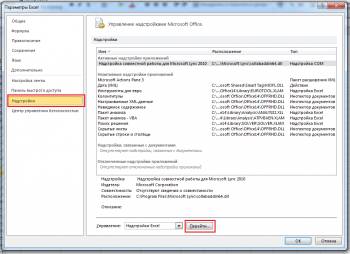
В открывшемся окне, слева, ищем пункт Надстройки и активируем его, в этой вкладке внизу будет выпадающий список управления, где по умолчанию будет написано Надстройки Excel, справа от выпадающего списка будет кнопка Перейти, на нее и нужно нажать.
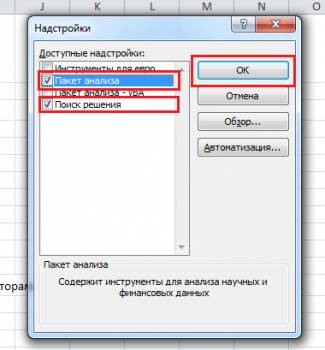
Всплывающее окошко предложит выбрать доступные надстройки, в нем необходимо поставить галочку напротив Пакет анализа и заодно, на всякий случай, Поиск решения (тоже полезная штука), а затем подтвердить выбор кликнув по кнопочке ОК.
Инструкция по поиску параметров линейной регрессии с помощью Пакета анализа
После активации надстройки Пакета анализа она будет всегда доступна во вкладке главного меню Данные под ссылкой Анализ данных
В активном окошке инструмента Анализа данных из списка возможностей ищем и выбираем Регрессия
Далее откроется окошко для настройки и выбора исходных данных для вычисления параметров регрессионной модели. Здесь нужно указать интервалы исходных данных, а именно описываемого параметра (Y) и влияющих на него факторов (Х), как это на рисунке ниже, остальные параметры, в принципе, необязательны к настройке.
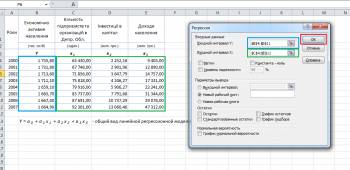
После того как выбрали исходные данные и нажали кнопочку ОК, Excel выдает расчеты на новом листе активной книги (если в настройках не было выставлено иначе), эти расчеты имеют следующий вид:
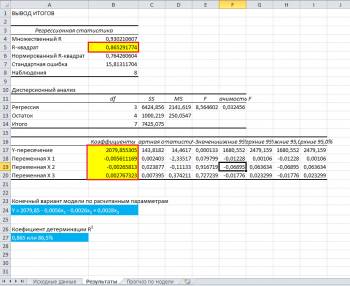
Ключевые ячейки залил желтым цветом именно на них нужно обращать внимание в первую очередь, остальные параметры значимость также немаловажны, но их детальный разбор требует пожалуй отдельного поста.
Итак, 0,865 - это R 2 - коэффициент детерминации, показывающий что на 86,5% расчетные параметры модели, то есть сама модель, объясняют зависимость и изменения изучаемого параметра - Y от исследуемых факторов - иксов. Если утрировано, то это показатель качества модели и чем он выше тем лучше. Понятное дело, что он не может быть больше 1 и считается неплохо, когда R 2 выше 0,8, а если меньше 0,5, то резонность такой модели можно смело ставить под большой вопрос.
Теперь перейдем к коэффициентам модели:
2079,85 - это a0 - коэффициент который показывает какой будет Y в случае, если все используемые в модели факторы будут равны 0, подразумевается что это зависимость от других неописанных в модели факторов;
-0,0056 - a1 - коэффициент, который показывает весомость влияния фактора x1 на Y, то есть количество предприятий в пределах данной модели влияет на показатель экономически активного населения с весом всего -0,0056 (довольно маленькая степень влияния). Знак минус показывает что это влияние отрицательно, то есть чем больше предприятий, тем меньше экономически активного населения, как бы это ни было парадоксальным по смыслу;
-0,0026 - a2 - коэффициент влияния объема инвестиций в капитал на величину экономически активного населения, согласно модели, это влияние также отрицательно;
0,0028 - a3- коэффициент влияния доходов населения на величину экономически активного населения, здесь влияние позитивное, то есть согласно модели увеличение доходов будет способствовать увеличению величины экономически активного населения.
Соберем рассчитанные коэффициенты в модель:
Собственно, это и есть линейная регрессионная модель, которая для исходных данных, используемых в примере, выглядит именно так.
Расчетные значения модели и прогноз
Как мы уже обсуждали выше, модель строится не только чтобы показать величину зависимостей изучаемого параметра от влияющих факторов, но и чтобы зная эти влияющие факторы можно было делать прогноз. Сделать этот прогноз довольно просто, нужно просто подставить значения влияющих факторов в место соответствующих иксов в полученное уравнение модели. На рисунке ниже эти расчеты сделаны в экселе в отдельном столбце.
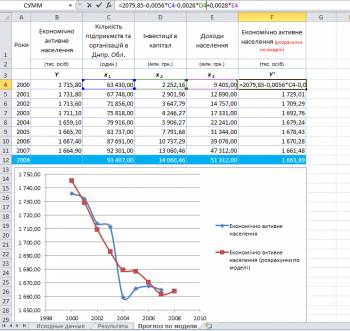
Фактические значения (те что имели место в реальности) и расчетные значения по модели на этом же рисунке отображены в виде графиков, чтобы показать разность, а значит погрешность модели.
Повторюсь еще раз, для того чтобы сделать прогноз по модели нужно чтобы были известные влияющие факторы, а если речь идет о временном ряде и соответственно прогнозе на будущее, например, на следующий год или месяц, то далеко не всегда можно узнать какие будут влияющие факторы в этом самом будущем. В таких случаях, нужно еще делать прогноз и для влияющих факторов, чаще всего это делают с помощью авторегрессионной модели - модели, в которой влияющими факторами являются сам исследуемый объект и время, то есть моделируется зависимость показателя от того каким он был в прошлом.
Как строить авторегрессионную модель рассмотрим в следующей статье, а сейчас предположим, что, то какие будут величины влияющих факторов в будущем периоде (в примере 2008 год) нам известно, подставляя эти значения в расчеты мы получим наш прогноз на 2008 год.
Рассмотрим планирование продаж и денежных потоков помощью авторегрессионной модели. Оценка будущих денежных поступлений важна как для собственника компании, так и инвесторам для определения ее эффективности в перспективе.
Планирование продаж и денежных потоков предприятия
Прогнозирование продаж и денежных потоков является важной задачей компании. Оценка будущих поступлений от реализации продукции позволяет планировать денежные потоки, которые могут быть направлены на повышение эффективности, производительности и стоимости предприятия для инвесторов.
Цель оценки объема продаж – оценка результативности и эффективности предприятия, точки безубыточности и финансового запаса прочности в перспективе.
Цель оценки денежных потоков – оценка потенциала компании для развития инноваций и реализации инвестиционных проектов.
Продажи компании и денежные потоки тесно взаимосвязаны между собой следующей формулой:

Оценка стоимости бизнеса | Финансовый анализ по МСФО | Финансовый анализ по РСБУ |
Расчет NPV, IRR в Excel | Оценка акций и облигаций |
Методы планирования продаж и денежных потоков
Существует множество различных методов прогнозирования объема продаж (денежных потоков): модель скользящего среднего (MA, Moving Average), модель авторегрессии (AR, AutoRegressive), модель авторегрессии скользящего среднего (Autoregressive Moving Average model, ARMA), модель Бокса-Дженкинса и др. В данной статье мы более подробно разберем прогнозирование с помощью модели авторегрессии.
Авторегрессионные модели (англ. AR, AutoRegressive model) используются для описания устойчивых (стационарных) процессов в экономике, когда на будущие значения прогнозируемой величины влияют предыдущие значения. Авторегрессионные модели (AR) используются в прогнозировании как макроэкономических показателей (ВВП, инфляция и др.), так и для оценки микроэкономических показателей: объем будущих продаж, чистой прибыли, размера денежных потоков т.д.
Модель прогнозирования продаж и денежных потоков
Авторегрессионная модель планирования объема продаж и денежных потоков имеет следующий аналитический вид:
где:
Yi – прогноз денежного потока или объема продаж;
Yi-1 – значение денежного потока и продаж в предыдущем периоде;
α, β – коэффициенты в модели авторегрессии;
ξ – случайная величина (белый шум).
Пример планирования продаж и денежных потоков предприятия ОАО «МТС» в Excel
Разберем практический пример планирования продаж (выручки) и объема денежных потоков предприятия ОАО «МТС». Данное предприятие было выбрано для анализа, потому что имеет устойчивую сеть дистрибьюторов и постоянный спрос на продукцию, что позволяет адекватно сделать оценку. На рисунке ниже представлена выручка и денежный поток компании за 10 лет. Данные были взяты из официальной отчетности предприятия. Денежные потоки представляли собой сумму чистой прибыли предприятия и амортизации (Форма №5 стр. 640 + Форма №2 стр. 190).
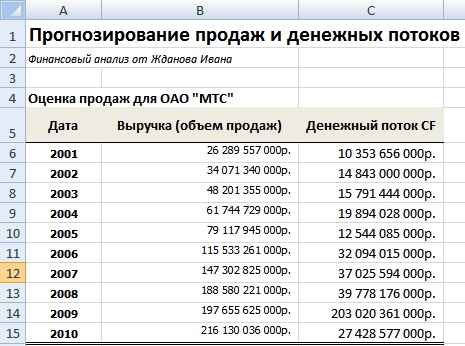
Объем продаж и денежный поток для ОАО «МТС»
Графически изменение объема продажи и денежного потока имеет следующий вид:
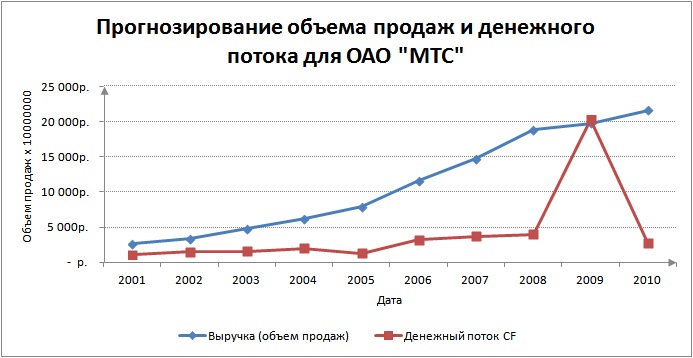
Как мы видим из рисунка, денежный поток компании резко изменился в 2009 году из-за большого размера начисленной амортизации, что сильно искажает динамику изменения денежного потока. Сделаем прогноз на два года вперед объема продаж и денежного потока предприятия по модели AR.
Первоначально для построения модели необходимо определить тесноту связи между ближайшими значениями продаж (денежного потока). Для этого необходимо произвести оценку регрессии со сдвигом ряда объема продаж. Был взят лаг в один год, потому что максимальное влияние на будущие значения оказывают именно предыдущие продажи.
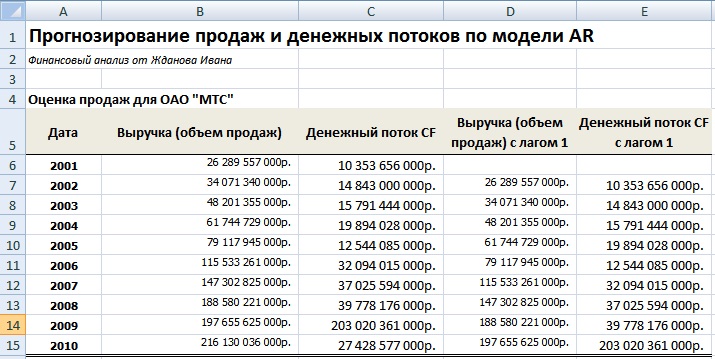
Расчет авторегрессии для объема продаж и денежного потока в Excel
На следующем этапе необходимо рассчитать значения коэффициентов регрессии между рядами и рядами с лагами в один год. Воспользуемся надстройкой: Главное меню Excel → «Данные» → «Анализ данных» → «Регрессия». Рассчитаем параметры отдельно для прогнозирования выручки и денежного потока. Пример оценки объема продаж представлен на рисунке ниже.
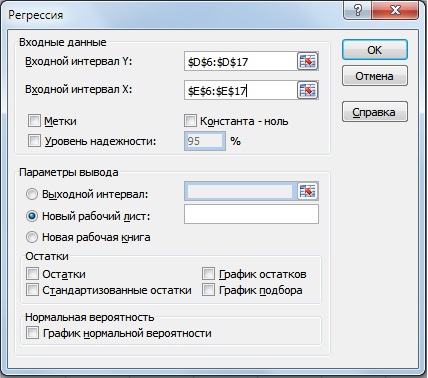
Мы получили базовые значения в модели регрессии для выручки (объема продаж). Так коэффициент альфа (α) в модели регрессии равен 16851967162, а коэффициент бета (β) 1,04. Полученная статистика по регрессионной модели имеет следующие важные показатели оценки ее адекватности и точности прогнозирования. Первое на что следует обратить внимание это показатель R-квадрат (коэффициент детерминации), который показывает качество модели в шкале от 0 до 1. В нашем примере качество модели высокое и составляет 0,97. Показатель модели критерий-F близок к 0, что показывает устойчивость модели. Статистический показатель P-значение отражает адекватность значений данных коэффициент (альфа, бета) для полученной модели он меньше 15% для обоих коэффициентов, что удовлетворяет нормативам.
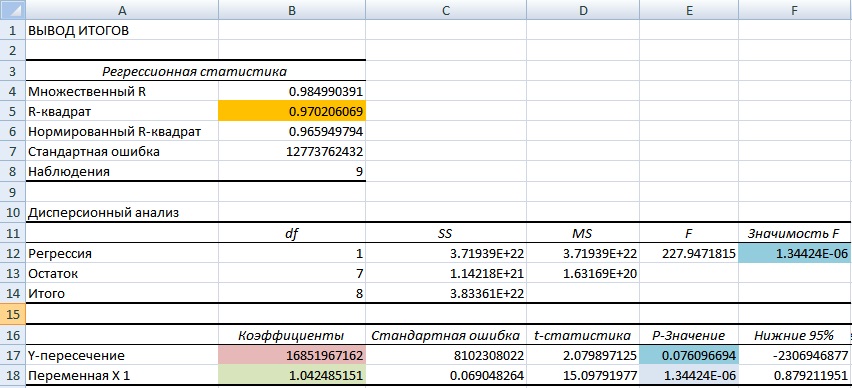
Показатели оценки качества регрессионной модели в Excel
Аналогично строится модель планирования денежных потоков предприятия. В результате полученные модели прогнозирования объема продаж и денежных потоков описываются с помощью следующих уравнений:

Сделаем прогноз на основе полученных моделей значений объема продажи и денежного потока на два года вперед. С помощью формул в Excel сделаем прогноз по модели.
Прогноз продаж по модели AR =$B$19+B6*$B$20
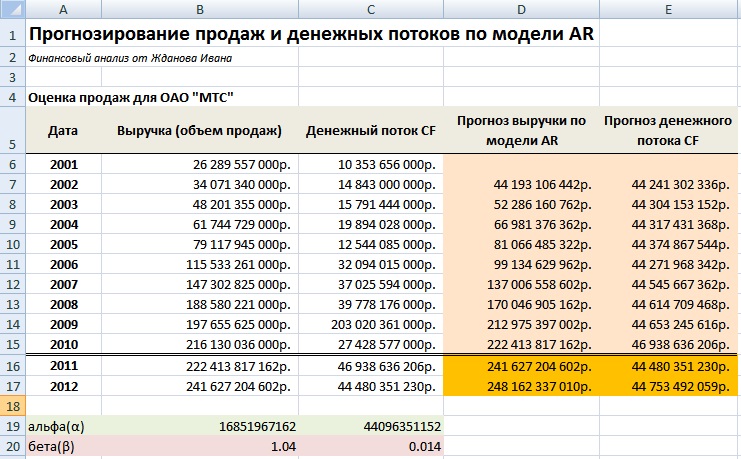
Планирование продаж и денежных потоков предприятия по модели авторегрессии в Excel
Визуально планирование продаж будет иметь следующий вид. Наблюдается повышающийся тренд на два года вперед.
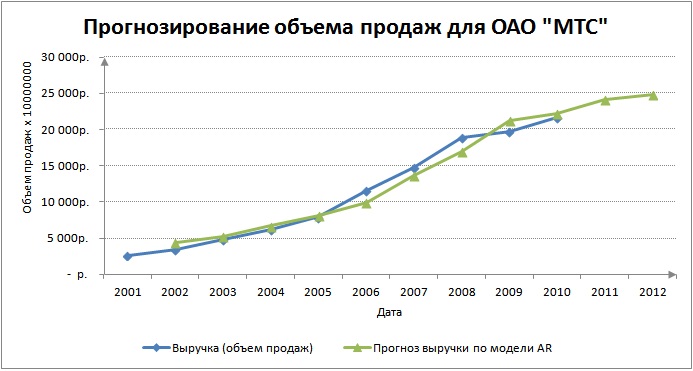
График прогноза объема продаж (выручки) предприятия
Графически прогноз денежного потока на два года вперед сильно не изменится.
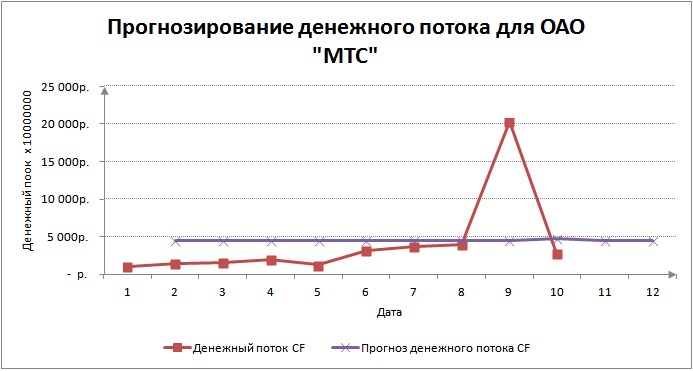
Прогнозирование денежного потока предприятия по модели авторегрессии (AR)
Использование методов прогнозирования денежных потоков позволяет оценить показатели эффективности инвестиционных проектов, более подробно про методы оценки проектов читайте в моей статье: «6 методов оценки эффективности инвестиций в Excel. Пример расчета NPV, PP, DPP, IRR, ARR, PI«. Существуют также другие методы планирования объемов продаж компании: XYZ-анализ, ABC-анализ, которые тоже зарекомендовали себя на практике. Так метод ABC анализа на практическом примере разобран в статье: «ABC анализ продаж. Пример расчета в Excel«.
Мастер-класс: «Как рассчитать план продаж»
Резюме
Использование методов авторегресси (AR) для планирования будущих объемов продаж (денежного потока) обосновано, если предприятие имеет устойчивую сеть дистрибьюторов и покупателей на свою продукцию. Достоинством использования данного метода оценки является возможность учета влияния предыдущего объема продаж (денежного потока) на будущие значения. В ситуациях экономического кризиса и нестабильности оценка может сильно изменяться под воздействием макроэкономических факторов и глобальных трендов.
1.В таблице представлен временной ряд некоторого показателя. На основе показателей ряда необходимо получить точечные и интервальные прогнозы на двухлетний период упреждения.
Таблица 6.1 - Информация периода наблюдения
| Годы | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 |
| Уфакт | 27,8 | 27,5 | 27,4 | 27,5 | 27,4 | 27,4 | 24,6 | 23,9 | 23,7 | 23,5 |
| Годы | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 |
| Уфакт | 22,3 | 21,6 | 21,2 | 20,0 | 20,0 | 19,7 | 18,5 | 18,1 | 16,9 | 16,7 |
По данным таблицы построим графики значений и добавим линии тренда с помощью диаграммы Excel в виде линейной, логарифмической, степенной, экспоненциальной и полиномиальной функций. Полученные результаты объединим в таблицу для выбора наиболее предпочтительной модели.
Таблица 6.2 - Аппроксимирующие функции
| Модель тренда | σ | |||
| линейная | y = -0,6407*t + 29,512 | 1,913 | 0,969 | 0,668 |
| логарифмическая | y = -4,0173*ln(t) + 31,423 | 5,781 | 0,784 | 1,752 |
| степенная | y = 32,741*t -0,1743 . | 6,490 | 0,755 | 2,032 |
| экспоненциальная | y = 30,284*e -0,0283* t | 2,267 | 0,965 | 0,792 |
| полиномиальная | y = -0,0073*t 2 – 0,4947*t + 29,001 | 1,905 | 0,972 | 0,635 |
По показателям адекватности (средняя ошибка аппроксимации, коэффициент детерминации и стандартное отклонение) для прогнозирования выбираем полиномиальную функцию. Используя эту модель, можно рассчитать точечные и интервальные прогнозы. Точечные прогнозы:
y21 = -0.0073*21 2 – 0.4947*21 + 29.001 = 15.393
y22 = -0.0073*22 2 – 0.4947*22 + 29.001 = 16.584
Расчет величин интервалов:
2.Проверим гипотезу о наличии автокорреляции в остатках с помощью критерия Дарбина-Уотсона для аддитивной модели временного ряда. Исходные данные и промежуточные расчеты заносим в таблицу (6.3).
Фактическое значение критерия Дарбина-Уотсона для данной модели составляет:
Сформулируем гипотезы: Н0 – в остатках нет автокорреляции; Н1 – в остатках есть положительная автокорреляция; – в остатках есть отрицательная автокорреляция. Зададим уровень значимости . По таблице значений критерия Дарбина-Уотсона определим для числа наблюдений и числа независимых параметров модели (мы рассматриваем только зависимость от времени ) критические значения и . Фактическое значение -критерия Дарбина-Уотсона попадает в интервал (1,37<2,24<2,63). Следовательно, гипотеза об отсутствии автокорреляции в остатках подтверждается.
Таблица 6.3 - Исходные данные и промежуточные расчета
| εt | ||||
| -5,252 | – | – | 27,584 | |
| -35,843 | -5,252 | 935,8093 | 1284,7 | |
| -74,183 | -35,843 | 1469,956 | 5503,1 | |
| 48,937 | -74,183 | 15158,53 | 2394,8 | |
| -26,946 | 48,937 | 5758,23 | 726,09 | |
| 60,464 | -26,946 | 7640,508 | 3655,9 | |
| 45,124 | 60,464 | 235,3156 | 2036,2 | |
| 50,244 | 45,124 | 26,2144 | 2524,5 | |
| 2,361 | 50,244 | 2292,782 | 5,574 | |
| -59,229 | 2,361 | 3793,328 | 3508,1 | |
| 41,431 | -59,229 | 10132,44 | 1716,5 | |
| -68,450 | 41,431 | 12073,83 | 4685,4 | |
| 69,668 | -68,45 | 19076,58 | 4853,6 | |
| 36,078 | 69,668 | 1128,288 | 1301,6 | |
| -34,263 | 36,078 | 4947,856 | ||
| -50,143 | -34,263 | 252,1744 | 2514,3 | |
| Сумма | -0,002 | 50,141 | 84921,85 | 37911,97 |
3. На основе данных о валовом внутреннем продукте (ВВП) необходимо выполнить следующие операции:
- доказать с помощью теста Дики-Фуллера, что изучаемый временной ряд является стационарным;
- построить автокорреляционную функцию и сделать вывод о наличии тенденции автокорреляции в остатках;
- в случае отсутствия автокорреляции построить аддитивную модель временного ряда; в случае наличия автокорреляции построить модель авторегрессии;
- осуществить прогноз на четыре уровня вперед.
Исходный временной ряд приведен в таблице 6.6.
Решение задачи разобьем на этапы:
а) докажем стационарность временного ряда с помощью теста Дики-Фуллера (см. формулу 6.32). Исходные данные теста представлены в таблице 6.5.
Таблица 6.6 - Информация периода наблюдения
| Год | квартал | ВВП | Год | квартал | ВВП |
| I | 1900,9 | I | 3516,8 | ||
| II | 2105,0 | II | 3969,8 | ||
| III | 2487,9 | III | 4615,2 | ||
| IV | 2449,8 | IV | 4946,4 | ||
| I | 2259,5 | I | 4479,2 | ||
| II | 2525,7 | II | 5172,9 | ||
| III | 3009,2 | III | 5871,7 | ||
| IV | 3023,1 | IV | 6096,2 | ||
| I | 2850,7 | I | 5661,8 | ||
| II | 3107,8 | II | 6325,8 | ||
| III | 3629,8 | III | 7248,1 | ||
| IV | 3655,0 | IV | 7545,4 | ||
| I | 6566,2 | ||||
| II | 7647,5 |
Таблица 6.5 - Исходные данные теста Дики-Фуллера

| Yt | t | Yt-1 | Yt | t | Yt-1 |
| - | 3969,8 | 3516,8 | |||
| 1900,9 | 4615,2 | 3969,8 | |||
| 2487,9 | 4946,4 | 4615,2 | |||
| 2449,8 | 2487,9 | 4479,2 | 4946,4 | ||
| 2259,5 | 2449,8 | 5172,9 | 4479,2 | ||
| 2525,7 | 2259,5 | 5871,7 | 5172,9 | ||
| 3009,2 | 2525,7 | 6096,2 | 5871,7 | ||
| 3023,1 | 3009,2 | 5661,8 | 6096,2 | ||
| 2850,7 | 3023,1 | 6325,8 | 5661,8 | ||
| 3107,8 | 2850,7 | 7248,1 | 6325,8 | ||
| 3629,8 | 3107,8 | 7545,4 | 7248,1 | ||
| 3629,8 | 6566,2 | 7545,4 | |||
| 3516,8 | 7647,5 | 6566,2 |
В таблице yt – зависимая переменная; t, yt-1 – независимые переменные регрессионной модели. По описанной в третьей главе последовательности регрессионного анализа находим постоянные коэффициенты модели: r=0,378. Так как значение коэффициента r принадлежит интервалу (0;1), то изучаемый временной ряд является стационарным.
б) Исследуем временной ряд с помощью автокорреляционной функции (рис. 6.5, 6.6). На рисунках показаны: исходный ряд (сверху) и автокорреляционная функция (АКФ) до лага 9 (снизу). На нижней диаграмме штриховой линией обозначен уровень «белого шума» - граница статистической значимости коэффициентов корреляции.
Рис. 6.5. Линейная модель тренда,
построенная по исходным данным
Рис. 6.6. Выборочная автокорреляционная функция
Если значения коэффициентов автокорреляции превышают уровень «белого шума», то коэффициент является статистически значимым. Автокорреляционная функция была построена с помощью одноименной надстройки программного продукта Microsoft Excel.
Если бы все коэффициенты автокорреляции были незначимы, что ряд был бы не пригоден для прогнозирования. Таким образом, имеется сильная корреляция 1 и 2 порядка, соседних членов ряда, но и удаленных на 1 единицу времени друг от друга. Корреляционные коэффициенты значительно превышают уровень «белого шума». По графику автокорреляции видим наличие четкого тренда.
Наличие сезонных колебаний позволяет выявить внутренняя динамика ряда. На первом этапе необходимо найти первую разность его членов, т.е. для каждого квартала найти изменение значения по сравнению с предыдущим кварталом (табл. 6.6).
Таблица 6.6 - Первая разность уровней временного ряда
| Год | квартал | ВВП | Год | квартал | ВВП |
| I | - | I | -138,2 | ||
| II | 204,1 | II | 453,0 | ||
| III | 382,9 | III | 645,4 | ||
| IV | -38,1 | IV | 331,2 | ||
| I | -190,3 | I | -467,2 | ||
| II | 266,2 | II | 693,7 | ||
| III | 483,5 | III | 698,8 | ||
| IV | 13,9 | IV | 224,5 | ||
| I | -172,4 | I | -434,4 | ||
| II | 257,1 | II | 664,0 | ||
| III | 522,0 | III | 922,3 | ||
| IV | 25,2 | IV | 297,3 | ||
| I | -979,2 | ||||
| II | 1081,3 |
Для первой разности построим автокорреляционную функцию (рис. 6.8). По графику 6.8 можно видеть, что первые разности возрастают, т.к. тренд восходящий. Видна автокорреляция 2 и 4-го порядков, что говорит о полугодовой и годовой сезонности. Если бы сезонность не была выявлена, то прогноз осуществлялся бы аддитивной моделью тренда. В данном случае обосновано применение авторегрессионной модели прогнозирования.
в) построим авторегрессионную модель. Так как АКФ экспоненциально убывает, то порядок авторегрессионной модели p будет равен 2, тогда авторегрессионная модель (6.10) примет вид:
Рис. 6.7. Исходный ряд частот
(первых разностей уровней временного ряда)
Исходные данные для проведения регрессионного анализа приведены в таблице 6.7.
Рис. 6.8. Частотная выборочная автокорреляционная функция
Таблица 6.7 - Исходные данные для нахождения коэффициентов авторегрессионной модели при p=2
| t | Yt | Yt-1 | Yt-2 | t | Yt | Yt-1 | Yt-2 |
| - | - | 3969,8 | 3516,8 | ||||
| - | 4615,2 | 3969,8 | 3516,8 | ||||
| 2487,9 | 1900,9 | 4946,4 | 4615,2 | 3969,8 | |||
| 2449,8 | 2487,9 | 4479,2 | 4946,4 | 4615,2 | |||
| 2259,5 | 2449,8 | 2487,9 | 5172,9 | 4479,2 | 4946,4 | ||
| 2525,7 | 2259,5 | 2449,8 | 5871,7 | 5172,9 | 4479,2 | ||
| 3009,2 | 2525,7 | 2259,5 | 6096,2 | 5871,7 | 5172,9 | ||
| 3023,1 | 3009,2 | 2525,7 | 5661,8 | 6096,2 | 5871,7 | ||
| 2850,7 | 3023,1 | 3009,2 | 6325,8 | 5661,8 | 6096,2 | ||
| 3107,8 | 2850,7 | 3023,1 | 7248,1 | 6325,8 | 5661,8 | ||
| 3629,8 | 3107,8 | 2850,7 | 7545,4 | 7248,1 | 6325,8 | ||
| 3629,8 | 3107,8 | 6566,2 | 7545,4 | 7248,1 | |||
| 3516,8 | 3629,8 | 7647,5 | 6566,2 | 7545,4 |
Зачеркнутые числа не участвует в построении модели авторегрессии. Зависимыми переменными являются yt-1 и yt-2. С помощью программного продукта Excel был проведен регрессионный анализ и были найдены постоянные коэффициенты модели:
y29=247,017+0,766* 7978,7+0,241* 7687,5=8211,4;
y30=247,017+0,766* 8211,4+0,241* 7978,7=8459,8.
6. Исходный временной ряд приведен в таблице 6.8.
Таблица 6.8 - Информация периода наблюдения
| Годы | |||||||||
| Динамика производства продукции | 10,0 | 11,1 | 12,1 | 12,5 | 13,7 | 13,9 | 19,6 | 15,9 | 19,0 |
Необходимо осуществить прогноз методами экспоненциального сглаживания и гармонических весов Хельвига. Данный временной ряд нестационарен, что можно доказать с помощью теста Дики-Фуллера. Опишем процедуру экспоненциального сглаживания. Сглаженные данные получим с помощью уравнения (6.14). Пусть параметр сглаживание α равен 0,8, т.е. фактор затухания (1-α) равен 0,2. Тогда процесс экспоненциального сглаживания имеет вид
Таким образом, получен прогноз на 10-е наблюдение.
Процедура экспоненциального сглаживания может быть осуществлена программными средствами Excel: Сервис®Анализ данных®Экспоненциальное сглаживание (рис. 6.9).
Рис. 6.9. Экспоненциальное сглаживание уровней временного ряда с фактором затухания 0,2
Далее представим процедуру сглаживания уровней временного ряда методом гармонических весов Хельвига. Находим параметры уравнений отдельных фаз движения скользящего тренда.
Примем k=3, тогда получим (9-3+1) = 7 уравнений:
Далее по выделенным фазам были рассчитаны автокорреляционные функции, значения которых показали, что величина автокорреляционных функций уменьшается, то есть выполняется одно из основных условий применения метода гармонических весов для прогнозирования социально-экономических явлений.
С помощью полученных уравнений определяем значение скользящего тренда. При t=1 имеем одно значение Y * 1(t) , которое получаем из уравнения Y1(t)=8,97+1,05·1=10,02.
При t=2 имеем два значения Y * 2(t) , которые получим из уравнений
Затем были рассчитаны приросты:
Гармонические веса определялись по формуле :
Гармонические коэффициенты, полученные по формуле составили: С2 = 0,0156; С3 = 0,0335; С4 = 0,0543; С5 = 0,0793; С6 = 0,1106; С7 = 0,1522; С8 = 0,2147; С9 = 0,3397.
Все эти коэффициенты удовлетворяют необходимым условиям. Используя формулу , находим средний абсолютный прирост и рассчитываем прогнозные значения производства реализованной продукции; полученные данные вносим в таблицу 6.9. Доверительные интервалы прогноза находятся с применением неравенства Чебышева для случайной величины .
здесь – заданное целое положительное число, , где
Значения переменной коррелированны между собой. Поэтому можно предположить, что прогнозная величина переменна. Она является функцией отдаленности от l, где l = 1,2,3, ……t-1. Функция определяется из формулы:
Тогда доверительные интервалы для предсказанных значений yt+1 следующие:
В примере значение тыс. руб., значение примем равным 4, а значение найдем по формуле (6.39). Все расчеты объединим в таблице 6.9.
Читайте также: