
Как открыть в excel больше миллиона строк
Что такое большой файл? Ну так чтобы реально большой? В бытность свою я думал, что это файлик на 50-60 тыс строк записей. И оставался я бы в таком неведении до сих пор, но пришлось выполнять один проект, в котором надо было работать с файлами на 600-800 тыс строк. Хождение по мукам — под катом:
Что сначала
А сначала, друзья мои, ринулись мы в самое простое, что можно придумать. Interop.Excell, и все дела. Казалось. Ага, щаз. Как показали тестовые испытания, данный способ открытия приводил к тому, что за час было прочитано 200 тыс строк экселя, приложение активно потребляло оперативку, и раздвигало плечами остальные процессы на машине. Кончилось все ожидаемо, но следственный эксперимент надо было довести до конца — на 260 тысячах приложение свалилось в OutOfMemory на машине с 4 Гб. Стало понятно, что в лоб решить проблему не получится
Google it
Сколько нам открытий чудных… Гугль привел, как ни странно, в msdn, где я познакомился с двумя методами открытия очень больших файлов: DOM и SAX. Уж за давностью времен не вспомню, но какой то из них отвалился по причине опостылевшей уже на тот момент OutOfMemory, а второй был совершенно неюзабелен в плане доступа к данным. Почему — читаем ниже.
Из чего же, из чего же
Сделаны наши эксельки. Ни для кого, кто решил копнуть формат чуть глубже, не станет секретом, что в отличие от бинарным xls, xlsx — по сути zip архив с данными. Достаточно поменять расширение ручками и распаковать архив в папку — и мы получим всю внутреннюю структуру документа, что есть не что иное, как набор xml файлов и сопутствующей информации. Как оказалось, в корневом xml нет текстовых данных. Вместо этого мы имеем набор индексов, которые ссылаются на вспомогательный файл, в котором представлены пары «ключ/значение» Одним из вышеприведенных способов открыть то файл можно, но при этом нужно копаться в сопутствующих файлах и вытаскивать из них текстовые значения. Мрак.
И отступила тьма
После долгих мытарств и стенаний родилось следующее:
Наши любимые юзинги, которые некоторые личности забывают указывать:
using System;
using System.Collections. Generic ;
using System.Data;
using System.Data.OleDb;
using System.IO;
using System.Linq;
using DocumentFormat.OpenXml;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Spreadsheet;
* This source code was highlighted with Source Code Highlighter .
Собственно, сам код:
public delegate void MessageHave( string message);
public delegate void _DataLoaded( List < string >data);
public delegate void _NewProcent( int col);
public static _DataLoaded DataLoaded;
public static _NewProcent NewProcent;
public static MessageHave MessageHave_Event;
id++;
if (id == calc)
NewProcent(id);
calc += 1000;
>
>
DataLoaded(lines);
>
cnn.Close();
>
catch (Exception ex)
MessageHave_Event( "Exception: " + ex.Message);
cnn.Close();
>
>
>
* This source code was highlighted with Source Code Highlighter .
Код показал производительность порядка 15-20 минут на файлах в 600-800 тыс строк записей.
Если кому то реализация покажется кривой — сильно не пинать :) Выслушаю все комментарии
Если в один прекрасный момент вы осознаете, что ваш основной рабочий файл в Excel разбух до нескольких десятков мегабайт и во время открытия файла можно смело успеть налить себе кофе, то попробуйте пробежаться по описанным ниже пунктам - возможно один или несколько из них укоротят вашего "переростка" до вменяемых размеров и разгонят его "тормоза" :)
Проблема 1. Используемый диапазон листа больше, чем нужно
Если ваша таблица занимает 5 на 5 ячеек, то это отнюдь не означает, что Excel запоминает при сохранении этого файла только 25 ячеек с данными. Если вы в прошлом использовали какие-либо ячейки на этом листе, то они автоматически включаются в используемый диапазон (так называемый Used Range), который и запоминается при сохранении книги. Проблема в том, что при очистке используемых ячеек Excel далеко не всегда автоматически исключает их из используемого диапазона, т.е. начинает запоминать в файле больше данных, чем реально имеется.
Проверить это просто – нажмите на клавиатуре сочетание клавиш Ctrl+End и посмотрите куда переместится активная ячейка. Если она прыгнет на фактическую последнюю ячейку с данными на листе – отлично. А если вдруг ускачет сильно правее и/или ниже "в пустоту" – дело плохо: все эти ненужные пустые ячейки Excel тоже запоминает внутри файла.
Лечится это, тем не менее, достаточно легко:
- Выделите первую пустую строку под вашей таблицей
- Нажмите сочетание клавиш Ctrl+Shift+стрелка вниз – выделятся все пустые строки до конца листа.
- Удалите их, нажав на клавиатуре Ctrl+знак минус или выбрав на вкладке Главная – Удалить – Удалить строки с листа (Home – Delete – Delete rows) .
- Повторите то же самое со столбцами.
- Повторите все вышеописанные процедуры на каждом листе, где при нажатии на Ctrl+End активная ячейка перемещается не на фактическую последнюю ячейку с данными а "в пустоту" ниже и/или правее.
- Сохраните файл (обязательно, иначе изменения не вступят в силу!)
Если в вашей книге очень много таких листов, то проще, наверное, использовать короткий макрос.
Проблема 2. Используется старый формат XLS вместо новых XLSX, XLSM и XLSB
Много лет и версий подряд еще с начала девяностых в Excel был один формат файлов - XLS. Это, конечно, убирало проблемы совместимости, но, сам по себе, этот формат давно устарел и имел много неприятных недостатков (большой размер, непрозрачность внутренней структуры данных, легкую повреждаемость и т.д.)
Начиная с верии Excel 2007 Microsoft ввела новые форматы сохранения файлов, использование которых заметно облегчает жизнь и - ваши файлы:
- XLSX - по сути является зазипованным XML. Размер файлов в таком формате по сравнению с Excel 2003 меньше, в среднем, в 5-7 раз.
- XLSM - то же самое, но с поддержкой макросов.
- XLSB - двоичный формат, т.е. по сути - что-то вроде скомпилированного XML. Обычно в 1.5-2 раза меньше, чем XLSX. Единственный минус: нет совместимости с другими приложениями кроме Excel, но зато размер - минимален.
Проблема 3. Избыточное форматирование
Сложное многоцветное форматирование, само-собой, негативно отражается на размере вашего файла. А условное форматирование еще и ощутимо замедляет его работу, т.к. заставляет Excel пересчитывать условия и обновлять форматирование при каждом чихе.
Оставьте только самое необходимое, не изощряйтесь. Особенно в тех таблицах, которые кроме вас никто не видит. Для удаления только форматов (без потери содержимого!) выделите ячейки и выберите в выпадающем списке Очистить - Очистить форматы (Clear - Clear Formats) на вкладке Главная (Home) :
Особенно "загружают" файл отформатированные целиком строки и столбцы. Т.к. размер листа в последних версиях Excel сильно увеличен (>1 млн. строк и >16 тыс. столбцов), то для запоминания и обрабоки подобного форматирования нужно много ресурсов. В Excel 2013-2016, кстати, появилась надстройка Inquire, которая содержит инструмент для быстрого избавления от подобных излишеств - кнопку Удалить избыточное форматирование (Clean Excess Cell Formatting) :

Она мгновенно удаляет все излишнее форматирование до конца листа, оставляя его только внутри ваших таблиц и никак не повреждая ваши данные. Причем может это сделать даже для всех листов книги сразу.
Если вы не видите у себя в интерфейсе вкладку Inquire, то ее необходимо подключить на вкладке Разработчик - Надстройки COM (Developer - COM Addins) .
Проблема 4. Ненужные макросы и формы на VBA
Большие макросы на Visual Basic и особенно пользовательские формы с внедренной графикой могут весьма заметно утяжелять вашу книгу. Для удаления:
- нажмите Alt+F11, чтобы войти в редактор Visual Basic
- найдите окно Project Explorer’а (если его не видно, то выберите в меню View - Project Explorer)
- удалите все модули и все формы (правой кнопкой мыши - Remove - дальше в окне с вопросом о экспорте перед удалением - No):
Также код может содержаться в модулях листов - проверьте их тоже. Также можно просто сохранить файл в формате XLSX без поддержки макросов - все макросы и формы умрут автоматически. Также можно воспользоваться инструментом Очистить книгу от макросов из надстройки PLEX.
Проблема 5. Именованные диапазоны
Если в вашем файле используются именованные диапазоны (особенно с формулами, динамические или получаемые при фильтрации), то имеет смысл от них отказаться в пользу экономии размера книги. Посмотреть список имеющихся диапазонов можно нажав Ctrl+F3 или открыв окно Диспетчера имен (Name Manager) на вкладке Формулы (Formulas) :
Также вычищайте именованные диапазоны с ошибками (их можно быстро отобрать с помощью кнопки Фильтр в правом верхнем углу этого окна) - они вам точно не пригодятся.
Проблема 6. Фотографии высокого разрешения и невидимые автофигуры
Если речь идет о фотографиях, добавленных в книгу (особенно когда их много, например в каталоге продукции), то они, само-собой, увеличивают размер файла. Советую сжимать их, уменьшая разрешение до 96-150 точек на дюйм. На экране по качеству это совершенно не чувствуется, а размер файла уменьшает в разы. Для сжатия воспользуйтесь кнопкой Сжать рисунки (Compress pictures) на вкладке Формат (Format) :
Кроме видимых картинок на листе могут содержаться и невидимые изображения (рисунки, фотографии, автофигуры). Чтобы увидеть их, выделите любую картинку и на вкладке Формат (Format) нажмите кнопку Область выделения (Selection Pane) .
Для удаления вообще всех графических объектов на текущем листе можно использовать простой макрос:
Проблема 7. Исходные данные сводных таблиц
По-умолчанию Excel сохраняет данные для расчета сводной таблицы (pivot cache) внутри файла. Можно отказаться от этой возможности, заметно сократив размер файла, но увеличив время на обновление сводной при следующем открытии книги. Щелкните правой кнопкой мыши по сводной таблице и выберите команду Свойства таблицы (Pivot Table Properties) - вкладка Данные (Data) - снять флажок Сохранять исходные данные вместе с файлом (Save source data with file):
Если у вас несколько сводных таблиц на основе одного диапазона данных, то сократить размер файла здорово помогает метод, когда все сводные таблицы после первой строятся на основе уже созданного для первой таблицы кэша. В Excel 2000-2003 это делается выбором переключателя на первом шаге Мастера сводных таблиц при построении:
В Excel 2007-2016 кнопку Мастера сводных таблиц нужно добавлять на панель вручную - на ленте такой команды нет. Для этого щелкните по панели быстрого доступа правой кнопкой мыши и выберите Настройка панели быстрого доступа (Customize Quick Access Toolbar) и затем найдите в полном списке команд кнопку Мастер сводных таблиц (PivotTable and PivotChart Wizard) :
Проблема 8. Журнал изменений (логи) в файле с общим доступом
Если в вашем файле включен общий доступ на вкладке Рецензирование - Доступ к книге (Review - Share Workbook) , то внутри вашего файла Excel на специальном скрытом листе начинает сохраняться вся история изменений документа: кто, когда и как менял ячейки всех листов. По умолчанию, такой журнал сохраняет данные изменений за последние 30 дней, т.е. при активной работе с файлом, может запросто занимать несколько мегабайт.
Мораль: не используйте общий доступ без необходимости или сократите количество дней хранения данных журнала, используя вторую вкладку Подробнее (Advanced) в окне Доступ к книге. Там можно найти параметр Хранить журнал изменений в течение N дней (Keep change history for N days) или совсем отключить его:

Проблема 9. Много мусорных стилей
Про эту пакость я уже подробно писал ранее в статье о том, как победить ошибку "Слишком много форматов ячеек". Суть, если кратко, в том, что если вы разворачиваете на вкладке Главная список Стили ячеек (Home - Cell Styles) и видите там очень много непонятных и ненужных стилей, то это плохо - и для размера вашего файла Excel и для его быстродействия.

Удалить ненужные стили можно с помощью макроса или готовой команды из надстройки PLEX.
Проблема 10. Много примечаний
Примечания к ячейкам, конечно, не самый вредный момент из всех перечисленных. Но некоторые файлы могут содержать большое количество текста или даже картинок в примечаниях к ячейкам. Если примечания не содержат полезной для вас информации, то их можно легко удалить с помощью команды на вкладке Главная - Очистить - Очистить примечания (Home - Clear - Clear Comments) .
Работая с большой книгой в Excel в один совсем не прекрасный момент вы делаете что-то совершенно безобидное (добавление строки или вставку большого фрагмента ячеек, например) и вдруг получаете окно с ошибкой "Слишком много различных форматов ячеек":

Почему это происходит
Такая ошибка возникает, если в рабочей книге превышается предельно допустимое количество форматов, которое Excel может сохранять:
- для Excel 2003 и старше - это 4000 форматов
- для Excel 2007 и новее - это 64000 форматов
Причем под форматом в данном случае понимается любая уникальная комбинация параметров форматирования:
- шрифт
- заливки
- обрамление ячеек
- числовой формат
- условное форматирование
Так, например, если вы оформили небольшой фрагмент листа подобным образом:

. то Excel запомнит в книге 9 разных форматов ячеек, а не 2, как кажется на первый взгляд, т.к. толстая линия по периметру создаст, фактически 8 различных вариантов форматирования. Добавьте к этому дизайнерские танцы со шрифтами и заливками и тяга к красоте в большом отчете приведет к появлению сотен и тысяч подобных комбинаций, которые Excel будет вынужден запоминать. Размер файла от этого, само собой, тоже не уменьшается.
Подобная проблема также часто возникает при многократном копировании фрагментов из других файлов в вашу рабочую книгу (например при сборке листов макросом или вручную). Если не используется специальная вставка только значений, то в книгу вставляются и форматы копируемых диапазонов, что очень быстро приводит к превышению лимита.
Как с этим бороться
Направлений тут несколько:
- Если у вас файл старого формата (xls), то пересохраните его в новом (xlsx или xlsm). Это сразу поднимет планку с 4000 до 64000 различных форматов.
- Удалите избыточное форматирование ячеек и лишние "красивости" с помощью команды Главная - Очистить - Очистить форматы (Home - Clear - Clear Formatting) . Проверьте, нет ли на листах строк или столбцов отформатированных целиком (т.е. до конца листа). Не забудьте про возможные скрытые строки и столбцы.
- Проверьте книгу на наличие скрытых и суперскрытых листов - иногда на них и кроются "шедевры".
- Удалите ненужное условное форматирование на вкладке Главная - Условное форматирование - Управление правилами - Показать правила форматирования для всего листа (Home - Conditional Formatting - Show rules for this worksheet) .
- Проверьте, не накопилось ли у вас избыточное количество ненужных стилей после копирования данных из других книг. Если на вкладке Главная (Home) в списке Стили (Styles) огромное количество "мусора":

Запустить его можно с помощью сочетания клавиш Alt+F8 или кнопкой Макросы (Macros) на вкладке Разработчик (Developer) . Макрос удалит все неиспользуемые стили, оставив только стандартный набор:
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Состав колонок будет следующим:

В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
Для тестирования добавим spring-boot-starter-test
И еще нам нужен сам драйвер для подключения к БД
Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List с помощью простого метода:
А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "< ? = call message_ref(?, ?) >", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
В итоге наш метод генерации имеет следующий вид:
4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
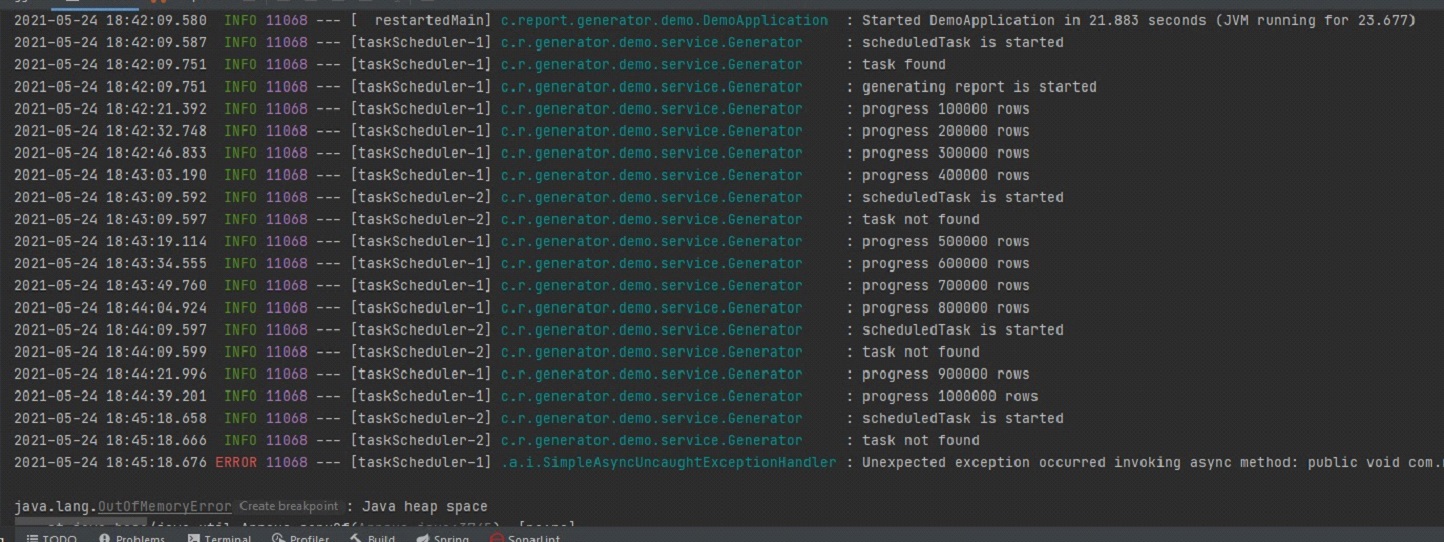
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.
Если вы открыли в Excel файл с большим набором данных, например текстовый (TXT) или CSV-файл, возможно, вы увидели предупреждение: "Этот набор данных слишком большой для сеткиExcel. Если вы сохраните эту книгу, вы потеряете данные, которые не были загружены.Это означает, что набор данных превышает количество строк или столбцов, доступных в Excel, поэтому некоторые данные не были загружены.

Чтобы не потерять данные, необходимо соблюдать дополнительные меры предосторожности.
Откройте файл в Excel для ПК,используя get Data (Получить данные). Если у вас есть приложение Excel для ПК, вы можете загрузить полный набор данных и проанализировать его с помощью таблиц с помощью Power Query.
Не сохранения файла в Excel. Если сохранить файл через исходный, вы потеряете все данные, которые не были загружены. Помните, что набор данных также неполный.
Сохранение усеченной копии. Если вам нужно сохранить файл, перейдите в папку >"Сохранить копию". Затем введите другое имя, которое будет ясно, что это усеченная копия исходного файла.
Открытие набора данных, превышаго ограничения Excel на сетку
С помощью Excel для ПК можно импортировать файл с помощью средства "Получить данные", чтобы загрузить все данные. Данные будут отображаться не больше, чем количество строк и столбцов в Excel, однако полный набор данных уже создан, и вы сможете анализировать его без потери данных.
Откройте пустую книгу в Excel.
На вкладке "Данные" > "Из текста/CSV> найдите файл и выберите "Импорт". В диалоговом окне предварительного просмотра выберите "Загрузить в. " > отчета.
После загрузки используйте список полей для у упорядочений полей в pivotTable. Для сведения данных в ней будет работать весь набор данных.
Вы также можете отсортировать данные в pivotTable илиотфильтроватьданные в ее.
Ограничения форматов файлов Excel
При работе в Excel важно помнить, какой формат файла вы используете. В формате файлов XLS на каждом листе может быть не более 65 536 строк, а в формате XLSX - 1 048 576 строк на листе. Дополнительные сведения см. в форматах файлов, поддерживаемых спецификациями и ограничениями Excel.
Чтобы предотвратить ограничение в Excel, не забудьте использовать для этого формат XLSX вместо XLS. Если вы знаете, что набор данных превышает ограничение XLSX, используйте альтернативные обходные пути для открытия и просмотра всех данных.
Совет: Убедитесь, что при открытие набора данных в Excel были импортироваться все данные. Вы можете проверить количество строк или столбцов в исходных файлах, а затем подтвердить их совпадение в Excel. Для этого вы можете выбрать всю строку или столбец и просмотреть количество в строке состояния в нижней части Excel.
Читайте также: