
Как избавиться от мультиколлинеарности в excel
Определение 3.1. Факторы коллинеарны, если между ними имеется связь, т.е. корреляция.
Определение 3.2. Явление мультипликативности – когда больше чем 2 фактора связаны между собой.
В случае мультиколлинеарности в первоначальном уравнении может быть дублирование, отсюда следует, что независимые факторы должны не зависеть.
О наличии мультиколлинеарности между независимыми факторами, как правило, судят по матрице попарных коэффициентов корреляции.
Считают, что 2 переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если их rxixj>0,7. Неявная зависимость факторов: 0,5< rxixj расч большое, а t-статистики маленькое).
Включение в модель мультиколлинеарных факторов затрудняется по следующим причинам:
1) Сложно объяснить коэффициенты регрессии с экономической точки зрения, т.к. коррелированы и имеется дубляж переменных.
2) Оценки параметров регрессии не надежны, отсюда следует, что модель не пригодна для анализа и прогнозирования.
О наличии мултиколлинеарности в целом для модели можно судить на основе следующего критерия:
1) Высчитывают определитель матрицы корреляционных парных коэффициентов.
Переменные Z1,k - главные компоненты.
Чем ближе det Rxixj к 1, тем меньше коллинеарность факторов.
где n – количество наблюдений
k – количество факторов
3) Определяется для степеней свободы
Для устранения мультиколлинеарности существует несколько подходов:
1. Исключение связанных между собой независимых факторов путем отбора мало существенных из них. Для этого необходимо исполнить следующие процедуры:
1) Включение дополнительных факторов
2) Исключение факторов
3) Пошаговая регрессия
При исключении факторов придерживаются следующих принципов (рассматривают только факторы, между которыми доказана мультиколлинеарность):
1) исходя из теоретических предположений о наименьшей информативности факторов
2) убирают самый наименее значимый фактор из мультиколлинеарных на основе t-статистики (t-статистика должна быть наименьшей)
2. Переход к ортогональным переменным с помощью метода главных компонентов.
В данном методе заменяют сильно коррелированные переменные совокупностью новых, между которыми корреляция отсутствует. Но эти переменные являются линейными комбинациями исходных переменных.
3. Подход, учитывающий мультиколлинеарность – метод гребневой регрессии.
В методе гребневой регрессии строятся несколько измененные коэффициенты регрессии МНК.
) -1 – обратная матрица
k – количество факторов
Ik+1 – матрица размерности n * m, приведенная к верхнетреугольному виду.
Добавление к диагональным элементам числа S позволяет получить невырожденную матрицу X T X и вместе с тем, оценки Bx будут иметь незначительные смещения. Но это можно компенсировать за счет правильного выбора S (т.е. средне квадратичные ошибки в методе гребневой регрессии будут меньше, чем аналогичные ошибки в МНК-оценках).
Для устранения или уменьшения мультиколлинеарности используется ряд методов.
Наиболее распространенные в таких случаях следующие приемы: исключение одного из двух сильно связанных факторов, переход от первоначальных факторов к их главным компонентам, число которых быть может меньше, затем возвращение к первоначальным факторам.
Самый простой из них состоит в том, что из двух объясняющих переменных, имеющих высокий коэффициент корреляции (больше 0,8), одну переменную исключают из рассмотрения. При этом какую переменную оставить, а какую удалить из анализа, решают в первую очередь на основании экономических соображений. Если с экономической точки зрения ни одной из переменных нельзя отдать предпочтение, то оставляют ту из двух переменных, которая имеет больший коэффициент корреляции с зависимой переменной.
Еще одним из возможных методов устранения или уменьшения мультиколлинеарности является использование стратегии шагового отбора.

Наиболее широкое применение получили следующие схемы построения уравнения множественной регрессии: метод включения факторов и метод исключения – отсев факторов из полного его набора. В соответствии с первой схемой признак включается в уравнение в том случае, если его включение существенно увеличивает значение множественного коэффициента корреляции, что позволяет последовательно отбирать факторы, оказывающие существенное влияние на результирующий признак даже в условиях мультиколлинеарности системы признаков, отобранных в качестве аргументов из содержательных соображений. При этом первым в уравнение включается фактор, наиболее тесно коррелирующий с Y, вторым в уравнение включается тот фактор, который в паре с первым из отобранных дает максимальное значение множественного коэффициента корреляции, и т.д.
Вторая схема заключается в том, что после построения уравнения регрессии и оценки значимости всех коэффициентов регрессии из модели исключают тот фактор, коэффициент при котором незначим и имеет наименьший коэффициент t . После этого получают новое уравнение множественной регрессии и снова производят оценку значимости всех оставшихся коэффициентов регрессии. Процесс исключения факторов останавливается на том шаге, при котором все регрессионные коэффициенты значимы.
Особым случаем мультиколлинеарности при использовании временных выборок является наличие в составе переменных линейных или нелинейных трендов. В этом случае рекомендуется сначала выделить и исключить тренды, а затем определить параметры регрессии по остаткам. Игнорирование наличия трендов в зависимой и независимой переменных ведет к завышению степени влияния независимых переменных на результирующий признак, что получило название ложной корреляции.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню Сервис/Надстройки .
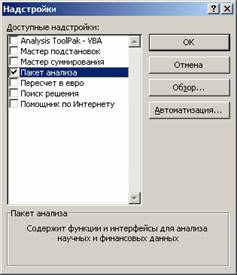
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel , нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:

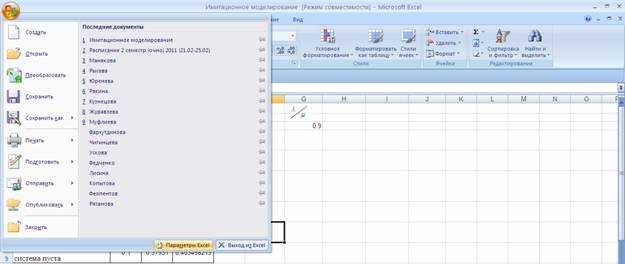
Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа , нажать кнопку Перейти и в следующем окне включить пакет анализа.
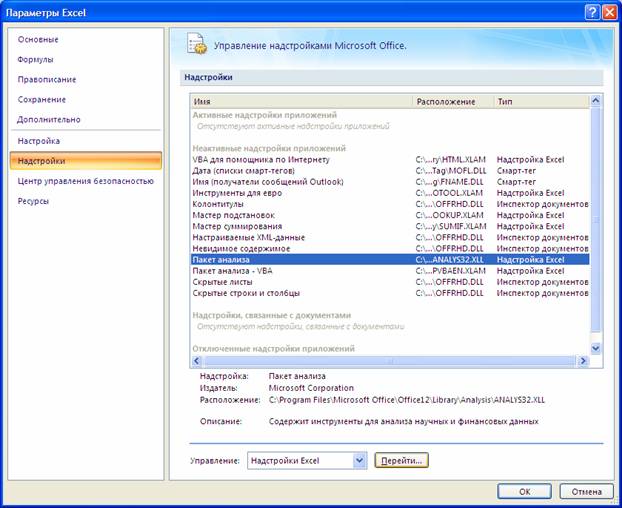
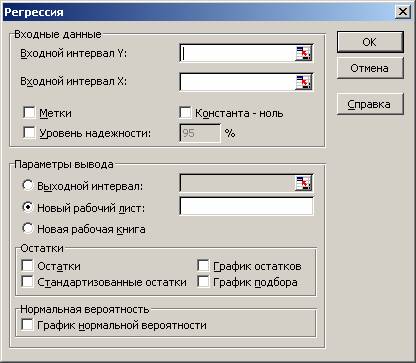
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия . (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия ) Появится диалоговое окно, которое нужно заполнить:
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R -квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения - это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R 2 = 0 (нет линейной зависимости), иначе принимается гипотеза R 2 ≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a0 , стандартной ошибки Sb0 и t -статистики tb0.
P-значение - это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП( t -статистика; n-m-1). Если P -значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% - это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2. xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Алгоритм работы
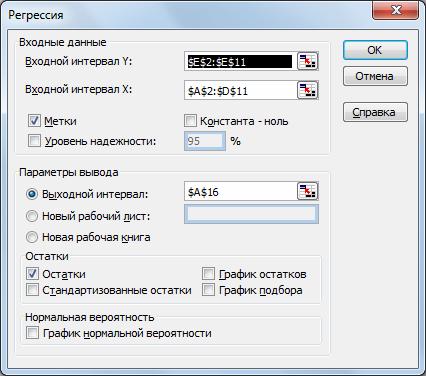
Вводим заданные значения xi и y , затем выбираем пункт меню Сервис/Анализ данных/Регрессия. Далее указываем интервалы значений xи y, включаем режим Метки, оставляем уровень надежность по умолчанию, указываем выходной интервал и включаем вывод остатков:
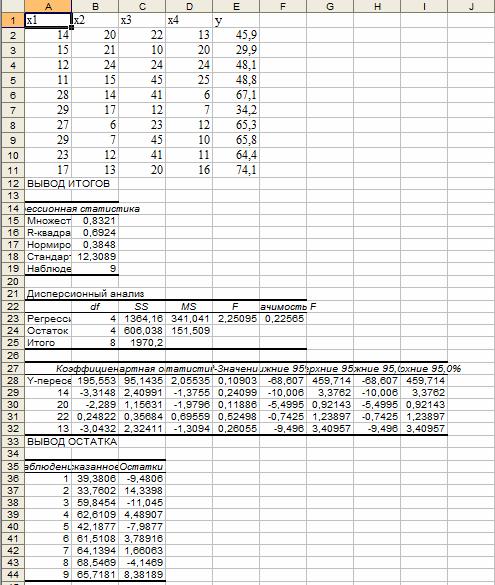
а) Коэффициенты уравнения соответствуют данным столбца Коэффициенты (следующий за столбцомY-пересечения) (блок Дисперсионный анализ).
б) Стандартная ошибка регрессии соответствует значению Стандартная ошибка блока Регрессионная статистика.
Стандартные ошибки коэффициентов соответствуют значениям столбца Стандартная ошибка блока Дисперсионный анализ.
в) Доверительные интервалы соответствуют интервалам Нижние %, Верхние %.
г) Статистическая значимость коэффициентов уравнения соответствует столбцу t -статистика. Граничная точка t(α; n-m-1) вычисляется с помощью функции СТЬЮДРАСПОБР(0,05;n-m-1) . Если i -ое значение P-значения меньше a, то i -ый коэффициент статистически значим и влияет на результативный признак.
д) Коэффициент детерминации R-квадрат в блоке Регрессионная статистика. Скорректированный (нормированный) коэффициент детерминации R2n. Это означает, что модель объясняет R2n*100% общего разброса значений результативного признака с учетом поправки на число степеней свободы.
Проверка гипотезы о статистической значимости коэффициента детерминации:
Проводим правостороннюю проверку. Граничная точка Fα;n-m-1 определяется с помощью функции FРАСПОБР(α;m;n-m-1) .
Статистика F (определяется из блока Дисперсионный анализ).
Если F> Fα;n-m-1, то гипотеза отвергается H0 и принимает гипотеза H1 на уровне значимости α%.
Этот вывод подтверждает число из столбца Значимость F, которое должно быть меньше значения a.
- Среднее значение: СРЗНАЧ(диапазон)
- Квадратическое отклонение: КВАДРОТКЛ(диапазон)
- Дисперсия: ДИСП(диапазон)
- Дисперсия для генеральной совокупности: ДИСПР(диапазон)
- Среднеквадратическое отклонение: СТАНДОТКЛОН(диапазон)
- Уравнение регрессии y = b1x1+b2x2+. bnxn+b0: ЛИНЕЙН(диапазон Y;диапазон X;1;1) .
- Выделите блок ячеек размером (n+1) столбцов и 5 строк.
Методические пояснения. 1. Для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические»), обратите внимание, что эта функция является функцией массива, поэтому ее использование подразумевает выполнение следующих шагов:
1) В свободном месте рабочего листа выделите область ячеек размером 5 строк и 2 столбца для вывода результатов;
2) В Мастере функций (категория «Статистические») выберите функцию ЛИНЕЙН .
3) Заполните поля аргументов функции:
Известные_значения_y — адреса ячеек, содержащих значения признака ;
Известные_значения_x — адреса ячеек, содержащих значения фактора ;
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
4) После того, как будут заполнены все аргументы функции, нажмите комбинацию клавиш ++ .
Результаты расчета параметров регрессионной модели будут выведены в виде следующей таблицы:
Значение коэффициента b | Значение коэффициента a |
Стандартная ошибка mb коэффициента b | Стандартная ошибка ma коэффициента a |
Коэффициент детерминации R 2 | Стандартное отклонение остатков Sост |
Значение F-статистики | Число степеней свободы, равное n-2 |
Регрессионная сумма квадратов | Остаточная сумма квадратов |
2. Табличные значения распределения Стьюдента определите с помощью функции СТЬЮДРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы — число степеней свободы, для парной линейной регрессии равно n-2, где n — число наблюдений.
3. Табличное значение распределения Фишера определите с помощью функции FРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы1 — число степеней свободы числителя, для парной регрессии равно 1 (т.к. один фактор);
Степени_свободы2 — число степеней свободы знаменателя, для парной регрессии равно n-2, где n — число наблюдений.
4. Коэффициент корреляции вычислите с помощью функции КОРРЕЛ. Аргументы функции:
Массив 1ш и Массив 2 — адреса ячеек, в которых содержатся значения величин, для которых вычисляется коэффициент корреляции.
5. Для вычисления (X T X) -1
1) Построите матрицу .
2) Постройте транспонированную к ней матрицу X T . Для построения матрицы X T необходимо воспользоваться функцией ТРАНСП (категория Ссылки и массивы).
3) матрицу X T необходимо умножить на матрицу X;
Произведение матриц вычисляется с помощью функции МУМНОЖ, аргументами которой являются перемножаемые матрицы. Перемножаемые матрицы должны удовлетворять условию соответствия размеров: матрица размера mxn может быть умножена справа на матрицу размера nxk, в результате получится матрица размера mxk.
В случае множественной регрессии с тремя факторами матрица X будет иметь размер nx4, матрица X T — размер 4xn, а их произведение X T X — размер 4x4.
Функция МУМНОЖ является функцией массива! Поэтому перед использованием функции МУМНОЖ необходимо выделить область размером mxk, в которой будет выведен результат, затем вставить функцию МУМНОЖ, указав ее аргументы. После этого в левой верхней ячейке выделенной области появится первый элемент результирующей матрицы. Для вывода всей матрицы нажмите комбинацию клавиш ++ .
4) найти обратную матрицу (X T X) -1 ;
Обратную матрицу (X T X) -1 вычислите с помощью функции МОБР . Функция МОБР также является функцией массива и ее использование аналогично функции МУМНОЖ: сначала необходимо выделить область ячеек, в которой будет получена обратная матрица, вставить функцию МОБР, затем ++ .
6. Коэффициенты множественной линейной регрессии вычисляются с помощью функции ЛИНЕЙН . Для того чтобы использовать эту функцию для вычисления параметров множественной регрессии необходимо
1) Сначала выделить на рабочем листе область размером 5x(k+1), где k — число объясняющих переменных.
2) Затем заполнить поля аргументов этой функции, которые имеют тот же смысл, что и в случае парной регрессии:
Известные_значения_y — адреса ячеек, содержащих значения признака y;
Известные_значения_x — адреса ячеек, содержащих значения всех объясняющих переменных.
Обратите внимание: выборочные значения факторов должны располагаться рядом друг с другом (в смежной области), причем предполагается, что в первом столбце (строке) содержатся значения первой объясняющей переменной, во втором столбце — второй и т.д.
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
При построении уравнения множественной регрессии может возникнуть проблема мультиколлинеарности факторов. Мультиколлинеарностью называется линейная взаимосвязь двух или нескольких объясняющих переменных, которая может проявляться в функциональной (явной) или стохастической (скрытой) форме.
Выявление связи между отобранными признаками и количественная оценка тесноты связи осуществляются с использованием методов корреляционного анализа. Для решения этих задач сначала оценивается матрица парных коэффициентов корреляции, затем на ее основе определяются частные и множественные коэффициенты корреляции и детерминации, проверяется их значимость. Конечной целью корреляционного анализа является отбор факторных признаков x1, x2,…,xm для дальнейшего построения уравнения регрессии.
Если факторные переменные связаны строгой функциональной зависимостью, то говорят о полной мультиколлинеарности. В этом случае среди столбцов матрицы факторных переменных Х имеются линейно зависимые столбцы, и, по свойству определителей матрицы, det(X T X) = 0 , т. е. матрица (X T X) вырождена, а значит, не существует обратной матрицы. Матрица (X T X) -1 используется в построении МНК-оценок. Таким образом, полная мультиколлинеарность не позволяет однозначно оценить параметры исходной модели регрессии.
Признаки мультиколлинеарности
- Регрессионные коэффициенты значительно изменяются по мере удаления или добавления новых предикторов;
- Регрессионный коэффициент отрицательный, хотя, исходя из теории, значения зависимой переменной должны расти пропорционально изменению предиктора(или наоборот);
- Ни один из коэффициентов не обладает статистической значимостью, однако F-статистика показывает значимость коэффициента детерминации.
- Регрессионный коэффициент не является значимым, хотя теоретически связь между ним и зависимой переменной должна быть существенной.
- При изменении данных (увеличении или уменьшении выборки) оценки коэффициентов значительно изменяются
К каким трудностям приводит мультиколлинеарность факторов, включенных в модель, и как они могут быть разрешены?
- оценки параметров становятся ненадежными. Они обнаруживают большие стандартные ошибки. С изменением объема наблюдений оценки меняются (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
- затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированны; параметры линейной регрессии теряют экономический смысл;
- становится невозможным определить изолированное влияние факторов на результативный показатель.
- увеличение дисперсий оценок параметров расширяет интервальные оценки и ухудшает их точность;
- уменьшение t-статистик коэффициентов приводит к неверным выводам о значимости факторов;
- неустойчивость МНК-оценок и их дисперсий.
Точных количественных критериев для обнаружения частичной мультиколлинеарности не существует. О наличии мультиколлинеарности может свидетельствовать близость к нулю определителя матрицы (X T X). Также исследуют значения парных коэффициентов корреляции. Если же определитель матрицы межфакторной корреляции близок к единице, то мультколлинеарности нет.
Существуют различные подходы преодоления сильной межфакторной корреляции. Простейший из них – исключение из модели фактора (или факторов), в наибольшей степени ответственных за мультиколлинеарность при условии, что качество модели при этом пострадает несущественно (а именно, теоретический коэффициент детерминации -R 2 y(x1. xm) снизится несущественно).
С помощью какой меры невозможно избавиться от мультиколлинеарности?
a) увеличение объема выборки;
b) исключения переменных высококоррелированных с остальными;
c) изменение спецификации модели;
d) преобразование случайной составляющей.
Парные (линейные) и частные коэффициенты корреляции
Тесноту связи, например между переменными x и y по выборке значений (xi, yi), i= 1,n , (1)
где x и y – средние значения, Sx и Sy – стандартные отклонения соответствующих выборок.
Парный коэффициент корреляции изменяется в пределах от –1 до +1. Чем ближе он по абсолютной величине к единице, тем ближе статистическая зависимость между x и y к линейной функциональной. Положительное значение коэффициента свидетельствует о том, что связь между признаками прямая (с ростом x увеличивается значение y ), отрицательное значение – связь обратная (с ростом x значение y уменьшается).
Можно дать следующую качественную интерпретацию возможных значений коэффициента корреляции: если |r|Для оценки мультиколлинеарности факторов используют матрицу парных коэффициентов корреляции зависимого (результативного) признака y с факторными признаками x1, x2,…,xm, которая позволяет оценить степень влияния каждого показателя-фактора xj на зависимую переменную y, а также тесноту взаимосвязей факторов между собой. Корреляционная матрица в общем случае имеет вид
.
Матрица симметрична, на ее диагонали стоят единицы. Если в матрице есть межфакторный коэффициент корреляции rxjxi>0.7, то в данной модели множественной регрессии существует мультиколлинеарность.
Поскольку исходные данные, по которым устанавливается взаимосвязь признаков, являются выборкой из некой генеральной совокупности, вычисленные по этим данным коэффициенты корреляции будут выборочными, т. е. они лишь оценивают связь. Необходима проверка значимости, которая отвечает на вопрос: случайны или нет полученные результаты расчетов.
Значимость парных коэффициентов корреляции проверяют по t-критерию Стьюдента. Выдвигается гипотеза о равенстве нулю генерального коэффициента корреляции: H0: ρ = 0. Затем задаются параметры: уровень значимости α и число степеней свободы v = n-2. Используя эти параметры, по таблице критических точек распределения Стьюдента находят tкр, а по имеющимся данным вычисляют наблюдаемое значение критерия:
, (2)
где r – парный коэффициент корреляции, рассчитанный по отобранным для исследования данным. Парный коэффициент корреляции считается значимым (гипотеза о равенстве коэффициента нулю отвергается) с доверительной вероятностью γ = 1- α, если tНабл по модулю будет больше, чем tкрит.
Если переменные коррелируют друг с другом, то на значении коэффициента корреляции частично сказывается влияние других переменных.
Частный коэффициент корреляции характеризует тесноту линейной зависимости между результатом и соответствующим фактором при устранении влияния других факторов. Частный коэффициент корреляции оценивает тесноту связи между двумя переменными при фиксированном значении остальных факторов. Если вычисляется, например, ryx1|x2 (частный коэффициент корреляции между y и x1 при фиксированном влиянии x2), это означает, что определяется количественная мера линейной зависимости между y и x1, которая будет иметь место, если устранить влияние x2 на эти признаки. Если исключают влияние только одного фактора, получают частный коэффициент корреляции первого порядка.
Сравнение значений парного и частного коэффициентов корреляции показывает направление воздействия фиксируемого фактора. Если частный коэффициент корреляции ryx1|x2 получится меньше, чем соответствующий парный коэффициент ryx1, значит, взаимосвязь признаков y и x1 в некоторой степени обусловлена воздействием на них фиксируемой переменной x2. И наоборот, большее значение частного коэффициента по сравнению с парным свидетельствует о том, что фиксируемая переменная x2 ослабляет своим воздействием связь y и x1.
Частный коэффициент корреляции между двумя переменными (y и x2) при исключении влияния одного фактора (x1) можно вычислить по следующей формуле:
. (3)
Для других переменных формулы строятся аналогичным образом. При фиксированном x2
;
при фиксированном x3
.
Значимость частных коэффициентов корреляции проверяется аналогично случаю парных коэффициентов корреляции. Единственным отличием является число степеней свободы, которое следует брать равным v = n – l -2, где l – число фиксируемых факторов.
На основании частных коэффициентов можно сделать вывод об обоснованности включения переменных в регрессионную модель. Если значение коэффициента мало или он незначим, то это означает, что связь между данным фактором и результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор можно исключить из модели.
Пошаговая регрессия
Отбор факторов x1, x2, …,xm, включаемых в модель множественной регрессии, является одним из важнейших этапов эконометрического моделирования. Метод последовательного (пошагового) включения (или исключения) факторов в модель позволяет выбрать из возможного набора переменных именно те, которые усилят качество модели.
При реализации метода на первом шаге рассчитывается корреляционная матрица. На основе парных коэффициентов корреляции выявляется наличие коллинеарных факторов. Факторы xi и xj признаются коллинеарными, если rxjxi>0.7. В модель включают лишь один из взаимосвязанных факторов. Если среди факторов отсутствуют коллинеарные, то в модель могут быть включены любые факторы, оказывающие существенное влияние на y.
На втором шаге строится уравнение регрессии с одной переменной, имеющей максимальный по абсолютной величине парный коэффициент корреляции с результативным признаком.
На третьем шаге в модель вводится новая переменная, имеющая наибольшее по абсолютной величине значение частного коэффициента корреляции с зависимой переменной при фиксированном влиянии ранее введенной переменной.
При введении в модель дополнительного фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться. Если этого не происходит, т. е. коэффициент множественной детерминации увеличивается незначительно, то ввод нового фактора признается нецелесообразным.
Пример №1 . По 20 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от удельного веса рабочих высокой квалификации в общей численности рабочих x1 (% от стоимости фондов на конец года) и от ввода в действие новых основных фондов x2 (%).
| Y | X1 | X2 |
| 6 | 10 | 3,5 |
| 6 | 12 | 3,6 |
| 7 | 15 | 3,9 |
| 7 | 17 | 4,1 |
| 7 | 18 | 4,2 |
| 8 | 19 | 4,5 |
| 8 | 19 | 5,3 |
| 9 | 20 | 5,3 |
| 9 | 20 | 5,6 |
| 10 | 21 | 6 |
| 10 | 21 | 6,3 |
| 11 | 22 | 6,4 |
| 11 | 23 | 7 |
| 12 | 25 | 7,5 |
| 12 | 28 | 7,9 |
| 13 | 30 | 8,2 |
| 13 | 31 | 8,4 |
| 14 | 31 | 8,6 |
| 14 | 35 | 9,5 |
| 15 | 36 | 10 |
- Построить корреляционное поле между выработкой продукции на одного работника и удельным весом рабочих высокой квалификации. Выдвинуть гипотезу о тесноте и виде зависимости между показателями X1 и Y .
- Оценить тесноту линейной связи между выработкой продукции на одного работника и удельным весом рабочих высокой квалификации с надежностью 0,9.
- Рассчитать коэффициенты линейного уравнения регрессии для зависимости выработки продукции на одного работника от удельного веса рабочих высокой квалификации.
- Проверить статистическую значимость параметров уравнения регрессии с надежностью 0,9 и построить для них доверительные интервалы.
- Рассчитать коэффициент детерминации. С помощью F -критерия Фишера оценить статистическую значимость уравнения регрессии с надежностью 0,9.
- Дать точечный и интервальный прогноз с надежностью 0,9 выработки продукции на одного работника для предприятия, на котором высокую квалификацию имеют 24% рабочих.
- Рассчитать коэффициенты линейного уравнения множественной регрессии и пояснить экономический смысл его параметров.
- Проанализировать статистическую значимость коэффициентов множественного уравнения с надежностью 0,9 и построить для них доверительные интервалы.
- Найти коэффициенты парной и частной корреляции. Проанализировать их.
- Найти скорректированный коэффициент множественной детерминации. Сравнить его с нескорректированным (общим) коэффициентом детерминации.
- С помощью F -критерия Фишера оценить адекватность уравнения регрессии с надежностью 0,9.
- Дать точечный и интервальный прогноз с надежностью 0,9 выработки продукции на одного работника для предприятия, на котором высокую квалификацию имеют 24% рабочих, а ввод в действие новых основных фондов составляет 5%.
- Проверить построенное уравнение на наличие мультиколлинеарности по: критерию Стьюдента; критерию χ2. Сравнить полученные результаты.
Проверим переменные на мультиколлинеарность по третьему виду статистических критериев (критерий Стьюдента). Для этого найдем частные коэффициенты корреляции.
Частные коэффициенты корреляции.
Коэффициент частной корреляции отличается от простого коэффициента линейной парной корреляции тем, что он измеряет парную корреляцию соответствующих признаков (y и xi) при условии, что влияние на них остальных факторов (xj) устранено.
На основании частных коэффициентов можно сделать вывод об обоснованности включения переменных в регрессионную модель. Если значение коэффициента мало или он незначим, то это означает, что связь между данным фактором и результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор можно исключить из модели.
Теснота связи низкая.
Определим значимость коэффициента корреляции ryx1 /x2 .
Для этого рассчитаем наблюдаемые значения t-статистики по формуле:
где k = 1 - число фиксируемых факторов.
По таблице Стьюдента находим Tтабл
tкрит(n-k-2;α/2) = (17;0.025) = 2.11
Поскольку tнабл tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически - значим
Как видим, связь y и x2 при условии, что x1 войдет в модель, снизилась. Отсюда можно сделать вывод, что ввод в регрессионное уравнение x2 остается нецелесообразным.
Можно сделать вывод, что при построении регрессионного уравнения следует отобрать факторы x1 , x2.
Для борьбы с мультиколлинеарностью можно использовать следующие способы:
1. Ничего не делать;
2. Увеличить число наблюдений;
3. Исключить из модели переменную (переменные), имеющую высокую тесноту связи с другими независимыми переменными;
4. Преобразовать мультиколлинеарные переменные путем
§ представления их в виде линейной комбинации;
§ преобразования уравнения к виду логарифмического или к уравнению в первых разностях;
Первый прием предполагает создание новой переменной, которая является функцией мультиколлинеарных переменных и использование данной новой переменной взамен мультиколлинеарных в уравнении регрессии.
Второй – представление мультиколлинеарной переменной в виде разности: ;
5. Использовать статистические методы: главных компонент, гребневой регрессии, факторного анализа.
Алгортм Фаррара-Глобера.
С помощью данного алгоритма последовательно проверяется наличие мультиколлинеарности всего массива независимых переменных, каждой независимой переменной с остальными, а также попарная мультиколлинеарность.
В первом случае используется критерий («хи»-квадрат), во втором – -критерий Фишера и в третьем – -критерий Стьюдента. Алгоритм распадается на семь шагов.
1-й шаг. Стандартизация (нормализация) данных.
Для каждого наблюдения всех независимых переменных осуществляются расчеты
. В результате получают векторы нормализованных данных , которые образуют матрицу .
2-й шаг. Нахождение корреляционной матрицы для независимых переменных.
Вычисляют или в матричном виде ,
где – матрица коэффициентов парной корреляции независимых переменных.
3-й шаг. Вычисление значения критерия для проверки гипотезы о наличии мультиколлинеарности всего массива данных.
Расчетное значение критерия получается из формулы
где – определитель корреляционной матрицы .
Данное значение -критерия сравнивается с табличным при числе степеней свободы и уровне значимости , где – количество независимых переменных.
Если , то в массиве данных имеет место мультиколлинеарность.
Следующие два шага позволяют исследовать наличие мультиколлинеарности между каждой независимой переменной и остальными независимыми переменными.
4-й шаг. Нахождение обратной матрицы
5-й шаг. Вычисление значений -критерия Фишера для проверки гипотезы о наличии мультиколлинеарности между каждой независимой переменной и остальными независимыми переменными.
Для этого используется формула , где – диагональный элемент матрицы .
Расчетные значения -критерия сравниваются с табличными для числа степеней свободы и , и уровня значимости . Если , то -я переменная мультиколлинеарна с остальными.
Для каждой переменной можно рассчитать коэффициент детерминации
Для оценки наличия парной мультиколлинеарности производятся действия, описанные следующими двумя шагами.
6-й шаг. Расчет частных коэффициентов корреляции.
Частный коэффициент корреляции показывает тесноту связи между двумя переменными при условии, что остальные переменные постоянны, т.е. не меняются.
7-й шаг. Расчет значений -критерия Стьюдента для каждой пары независимых переменных.
Расчетные значения -критерия сравниваются с табличным знаением при степенях свободы и уровне значимости .
Если ,то между независимыми переменными и существует мультиколлинеарность.
Мультиколлинеарность
Последствия и признаки мультиколлинеарности
Если факторные переменные связаны строгой функциональной зависимостью, то говорят о полной мультиколлинеарности. В этом случае среди столбцов матрицы факторных переменных Х имеются линейно зависимые столбцы, и, по свойству определителей матрицы, det(X T X) = 0 , т. е. матрица (X T X) вырождена, а значит, не существует обратной матрицы. Матрица (X T X) -1 используется в построении МНК-оценок. Таким образом, полная мультиколлинеарность не позволяет однозначно оценить параметры исходной модели регрессии.
К каким трудностям приводит мультиколлинеарность факторов, включенных в модель, и как они могут быть разрешены?
Мультиколлинеарность может привести к нежелательным последствиям:
- оценки параметров становятся ненадежными. Они обнаруживают большие стандартные ошибки. С изменением объема наблюдений оценки меняются (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
- затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированны; параметры линейной регрессии теряют экономический смысл;
- становится невозможным определить изолированное влияние факторов на результативный показатель.
Вид мультиколлинеарности, при котором факторные переменные связаны некоторой стохастической зависимостью, называется частичной. Если между факторными переменными имеется высокая степень корреляции, то матрица (X T X) близка к вырожденной, т. е. det(X T X) ≈ 0.
Матрица (X T X) -1 будет плохо обусловленной, что приводит к неустойчивости МНК-оценок. Частичная мультиколлинеарность приводит к следующим последствиям:
- увеличение дисперсий оценок параметров расширяет интервальные оценки и ухудшает их точность;
- уменьшение t-статистик коэффициентов приводит к неверным выводам о значимости факторов;
- неустойчивость МНК-оценок и их дисперсий.
Точных количественных критериев для обнаружения частичной мультиколлинеарности не существует. О наличии мультиколлинеарности может свидетельствовать близость к нулю определителя матрицы (X T X). Также исследуют значения парных коэффициентов корреляции. Если же определитель матрицы межфакторной корреляции близок к единице, то мультколлинеарности нет.
Существуют различные подходы преодоления сильной межфакторной корреляции. Простейший из них – исключение из модели фактора (или факторов), в наибольшей степени ответственных за мультиколлинеарность при условии, что качество модели при этом пострадает несущественно (а именно, теоретический коэффициент детерминации -R 2 y(x1. xm) снизится несущественно).
С помощью какой меры невозможно избавиться от мультиколлинеарности?
a) увеличение объема выборки;
b) исключения переменных высококоррелированных с остальными;
c) изменение спецификации модели;
d) преобразование случайной составляющей.
Парные (линейные) и частные коэффициенты корреляции
Парный коэффициент корреляции изменяется в пределах от –1 до +1. Чем ближе он по абсолютной величине к единице, тем ближе статистическая зависимость между x и y к линейной функциональной. Положительное значение коэффициента свидетельствует о том, что связь между признаками прямая (с ростом x увеличивается значение y ), отрицательное значение – связь обратная (с ростом x значение y уменьшается).
Можно дать следующую качественную интерпретацию возможных значений коэффициента корреляции: если |r| 0.7, то в данной модели множественной регрессии существует мультиколлинеарность.
Поскольку исходные данные, по которым устанавливается взаимосвязь признаков, являются выборкой из некой генеральной совокупности, вычисленные по этим данным коэффициенты корреляции будут выборочными, т. е. они лишь оценивают связь. Необходима проверка значимости, которая отвечает на вопрос: случайны или нет полученные результаты расчетов.
Значимость парных коэффициентов корреляции проверяют по t-критерию Стьюдента. Выдвигается гипотеза о равенстве нулю генерального коэффициента корреляции: H0: ρ = 0. Затем задаются параметры: уровень значимости α и число степеней свободы v = n-2. Используя эти параметры, по таблице критических точек распределения Стьюдента находят tкр, а по имеющимся данным вычисляют наблюдаемое значение критерия:
, (2)
где r – парный коэффициент корреляции, рассчитанный по отобранным для исследования данным. Парный коэффициент корреляции считается значимым (гипотеза о равенстве коэффициента нулю отвергается) с доверительной вероятностью γ = 1- α, если tНабл по модулю будет больше, чем tкрит.
Если переменные коррелируют друг с другом, то на значении коэффициента корреляции частично сказывается влияние других переменных.
Частный коэффициент корреляции характеризует тесноту линейной зависимости между результатом и соответствующим фактором при устранении влияния других факторов. Частный коэффициент корреляции оценивает тесноту связи между двумя переменными при фиксированном значении остальных факторов. Если вычисляется, например, ryx1|x2 (частный коэффициент корреляции между y и x1 при фиксированном влиянии x2), это означает, что определяется количественная мера линейной зависимости между y и x1, которая будет иметь место, если устранить влияние x2 на эти признаки. Если исключают влияние только одного фактора, получают частный коэффициент корреляции первого порядка.
Сравнение значений парного и частного коэффициентов корреляции показывает направление воздействия фиксируемого фактора. Если частный коэффициент корреляции ryx1|x2 получится меньше, чем соответствующий парный коэффициент ryx1, значит, взаимосвязь признаков y и x1 в некоторой степени обусловлена воздействием на них фиксируемой переменной x2. И наоборот, большее значение частного коэффициента по сравнению с парным свидетельствует о том, что фиксируемая переменная x2 ослабляет своим воздействием связь y и x1.
Частный коэффициент корреляции между двумя переменными (y и x2) при исключении влияния одного фактора (x1) можно вычислить по следующей формуле:
. (3)
Для других переменных формулы строятся аналогичным образом. При фиксированном x2
;
при фиксированном x3
.
Значимость частных коэффициентов корреляции проверяется аналогично случаю парных коэффициентов корреляции. Единственным отличием является число степеней свободы, которое следует брать равным v = n – l -2, где l – число фиксируемых факторов.
На основании частных коэффициентов можно сделать вывод об обоснованности включения переменных в регрессионную модель. Если значение коэффициента мало или он незначим, то это означает, что связь между данным фактором и результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор можно исключить из модели.
Пошаговая регрессия
На втором шаге строится уравнение регрессии с одной переменной, имеющей максимальный по абсолютной величине парный коэффициент корреляции с результативным признаком.
На третьем шаге в модель вводится новая переменная, имеющая наибольшее по абсолютной величине значение частного коэффициента корреляции с зависимой переменной при фиксированном влиянии ранее введенной переменной.
При введении в модель дополнительного фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться. Если этого не происходит, т. е. коэффициент множественной детерминации увеличивается незначительно, то ввод нового фактора признается нецелесообразным.
Пример №1 . По 20 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от удельного веса рабочих высокой квалификации в общей численности рабочих x1 (% от стоимости фондов на конец года) и от ввода в действие новых основных фондов x2 (%).
| Y | X1 | X2 |
| 6 | 10 | 3,5 |
| 6 | 12 | 3,6 |
| 7 | 15 | 3,9 |
| 7 | 17 | 4,1 |
| 7 | 18 | 4,2 |
| 8 | 19 | 4,5 |
| 8 | 19 | 5,3 |
| 9 | 20 | 5,3 |
| 9 | 20 | 5,6 |
| 10 | 21 | 6 |
| 10 | 21 | 6,3 |
| 11 | 22 | 6,4 |
| 11 | 23 | 7 |
| 12 | 25 | 7,5 |
| 12 | 28 | 7,9 |
| 13 | 30 | 8,2 |
| 13 | 31 | 8,4 |
| 14 | 31 | 8,6 |
| 14 | 35 | 9,5 |
| 15 | 36 | 10 |
- Построить корреляционное поле между выработкой продукции на одного работника и удельным весом рабочих высокой квалификации. Выдвинуть гипотезу о тесноте и виде зависимости между показателями X1 и Y .
- Оценить тесноту линейной связи между выработкой продукции на одного работника и удельным весом рабочих высокой квалификации с надежностью 0,9.
- Рассчитать коэффициенты линейного уравнения регрессии для зависимости выработки продукции на одного работника от удельного веса рабочих высокой квалификации.
- Проверить статистическую значимость параметров уравнения регрессии с надежностью 0,9 и построить для них доверительные интервалы.
- Рассчитать коэффициент детерминации. С помощью F -критерия Фишера оценить статистическую значимость уравнения регрессии с надежностью 0,9.
- Дать точечный и интервальный прогноз с надежностью 0,9 выработки продукции на одного работника для предприятия, на котором высокую квалификацию имеют 24% рабочих.
- Рассчитать коэффициенты линейного уравнения множественной регрессии и пояснить экономический смысл его параметров.
- Проанализировать статистическую значимость коэффициентов множественного уравнения с надежностью 0,9 и построить для них доверительные интервалы.
- Найти коэффициенты парной и частной корреляции. Проанализировать их.
- Найти скорректированный коэффициент множественной детерминации. Сравнить его с нескорректированным (общим) коэффициентом детерминации.
- С помощью F -критерия Фишера оценить адекватность уравнения регрессии с надежностью 0,9.
- Дать точечный и интервальный прогноз с надежностью 0,9 выработки продукции на одного работника для предприятия, на котором высокую квалификацию имеют 24% рабочих, а ввод в действие новых основных фондов составляет 5%.
- Проверить построенное уравнение на наличие мультиколлинеарности по: критерию Стьюдента; критерию χ2. Сравнить полученные результаты.
Проверим переменные на мультиколлинеарность по третьему виду статистических критериев (критерий Стьюдента). Для этого найдем частные коэффициенты корреляции.
Частные коэффициенты корреляции.
Коэффициент частной корреляции отличается от простого коэффициента линейной парной корреляции тем, что он измеряет парную корреляцию соответствующих признаков (y и xi) при условии, что влияние на них остальных факторов (xj) устранено.
На основании частных коэффициентов можно сделать вывод об обоснованности включения переменных в регрессионную модель. Если значение коэффициента мало или он незначим, то это означает, что связь между данным фактором и результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор можно исключить из модели.
Теснота связи низкая.
Определим значимость коэффициента корреляции ryx1 /x2 .
Для этого рассчитаем наблюдаемые значения t-статистики по формуле:
где k = 1 — число фиксируемых факторов.
По таблице Стьюдента находим Tтабл
tкрит(n-k-2;α/2) = (17;0.025) = 2.11
Поскольку tнабл tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
Как видим, связь y и x2 при условии, что x1 войдет в модель, снизилась. Отсюда можно сделать вывод, что ввод в регрессионное уравнение x2 остается нецелесообразным.
Можно сделать вывод, что при построении регрессионного уравнения следует отобрать факторы x1 , x2.
На основе таблицы данных (см. Приложение) для соответствующего варианта :
1. Проверить наличие коллинеарности и мультиколлинеарности. Отобрать неколлинеарные факторы.
2. Построить уравнение линейной регрессии.
3. Определить коэффициент множественной корреляции.
4. Проверить адекватность уравнения при уровнях значимости 0,05 и 0,01.
5. Построить частные уравнения регрессии.
6. Определить средние частные коэффициенты эластичности.
Краткие указания к выполнению лабораторной работы с помощью программных средств MS Excel
1. Для проверки наличия коллинеарности или мультиколлинеарности необходимо построить корреляционную матрицу, используя СервисÞАнализ данныхÞКорреляция табличного процессора MS Excel (см. Лабораторную работу №1).
| x1 | x2 | x3 | x4 | x5 | x6 | y | |
| x1 | |||||||
| x2 | 0.967 | 1.000 | |||||
| x3 | 0.910 | 0.903 | 1.000 | ||||
| x4 | 0.602 | 0.541 | 0.515 | 1.000 | |||
| x5 | -0.079 | -0.095 | 0.025 | 0.129 | 1.000 | ||
| x6 | -0.359 | -0.429 | -0.526 | -0.354 | -0.331 | 1.000 | |
| y | 0.959 | 0.960 | 0.865 | 0.742 | -0.052 | -0.428 | 1.000 |
Рис. 2.1. Пример корреляционной матрицы, построенной для всех независимых переменных x1,…,x6 и зависимой переменной у.
Исключать переменные из регрессионного уравнения можно по следующему алгоритму, продемонстрируемом на следующем примере (Рис. 2.1).
Из рисунка 2.1 следует, что наблюдается коллинеарность между факторами x1иx2, так как коэффициент корреляции между ними равен 0,967 (>>0.700). Более того, x2иx3также сильно коррелированны. При этом корреляция между x1иx3менее значимая (0,602<0,700), и эти независимые переменные сильно коррелированны с y. Наблюдается также высокая положительная корреляция между x3иy. Сама переменная x3 слабо коррелирует с x1иx3.
Таким образом, в линейное уравнение множественной регрессии могут быть включены независимые переменные x1, x3 иx4. Наряду с x2, из дальнейшего рассмотрения исключаются переменные, х5 и x6в силу слабой коррелированности этих переменных с зависимой переменной y.
2. Используя СервисÞАнализ данныхÞКорреляция табличного процессора MS Excel (см. Лабораторную работу №2), заполняется диалоговое окно "Регрессия" с выделением диапозонов значения для входного интервала Y и X. При этом в входной интервал X входят все значения переменных, включенных в регрессию.
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |
| Y-пересечение | -9.553881794 | 38.50490016 | -0.248121194 | 0.809061431 |
| Переменная X1 | 0.040936422 | 0.025120874 | 1.629577951 | 0.134245631 |
| Переменная X3 | 0.159940519 | 0.092019499 | 1.738115522 | 0.112827489 |
| Переменная X4 | -0.097836325 | 0.161067927 | -0.607422761 | 0.557111047 |
Рис. 2.2. Пример таблицы рабочего листа вывода итогов, содержащей регрессионные коэффициенты для переменных, включенных в регрессию.
Из приведенной таблицы (Рис. 2.2), получается следующее множественное регрессионное уравнение, содержащие три независимых переменных:
3) Указанный коэффициент множественной корреляции R, наряду с коэффициентом детерминации R 2 и скорректированным коэффициентом детерминации приведен в верхней таблице рабочего листа вывода итогов (Рис. 2.3).
| Регрессионная статистика | |
| Множественный R | 0.969 |
| R-квадрат | 0.938 |
| Нормированный R-квадрат | 0.920 |
| Стандартная ошибка | 45.315 |
| Наблюдения |
Рис. 2.3. Пример таблицы, содержащей R, R 2 и скорректированный R 2 .
4) Проверка значимости уравнения регрессии основана на использовании F-критерии Фишера. Фактическое значение Фишера Fфакт берется из таблицы "Дисперсионный анализ" листа вывода итогов (Рис. 2.4):
| df | SS | MS | F | Значимость F |
| Регрессия | 313551.0012 | 104517.0004 | 50.89612302 | 2.3136E-06 |
| Остаток | 20535.35597 | 2053.535597 | ||
| Итого | 334086.3571 |
Рис. 2.4. Пример таблицы, содержащей результаты дисперсионного анализ.
Из рисунка 2.4 получается, что Fфакт = 50,896.
Для определения критического значения Fкрит используется встроенная функция MS Excel «FРАСПОБР» (Рис. 2.5), задавая следующие параметры: вероятность (α = 0,05 и α = 0,01), степени_свободы1 равно количеству независимых переменных в уравнении и степени_свободы2 равно количеству наблюдений минус количество коэффициентов уравнения регрессии (Рис. 2.5)

Рис. 2.5. Пример Окна параметров MS Excel «FРАСПОБР»
Из рисунка 2.5 следует, что критическое значение Fкрит=3.708
Так как расчетное значение Fфакт = 50,896 больше Fкрит=3.708, то с вероятностью p=0.95 (где p=1-α) можно утверждать, что полученное регрессионное уравнение является адекватным. Если Fфакт меньше Fкрит, то делается обратный вывод.
5. Строятся частные регрессионные уравнения, предварительно определив средние значения зависимой и независимых переменных, входящих в регрессионное уравнение. В приведенном примере:
Частное уравнение регрессии характеризует взаимосвязь зависимой переменной у от независимой xi при неизменном уровне всех остальных (значения всех остальных переменных считается равным их среднему)
Например, частное уравнения зависимости у от независимой x1 будет иметь следующий вид:
Аналогично определяются все оставшиеся уравнения частной регрессии.
6. Коэффициенты частной эластичности определяются аналогично случая парной регрессии (см. лабораторную работу №2)
7. Все расчеты выполняются в MS Excel. Отчет готовиться в MS Word с описанием основных шагов выполнения данной лабораторной работы и интерпретацией полученных результатов.
8. Подготовленный отчет сдается через электронную систему обучения ГОУ ВПО КГТЭИ.
Читайте также: