
Как из вордстата выгрузить слова в excel
Многие люди не знают, как работать с трендами в интернете, где их искать. Перед тем, как начинать бизнес не знают, где посмотреть будет ли этот бизнес вообще популярен в определенной области/городе и нужен ли он. Поэтому напишу полный туториал, чтобы закрыть все вопросы по этой тематике.
Работать мы будем со специальным сервисом по сбору поисковых запросов пользователей Яндекса Вордстатом, интерфейс которого довольно прост и понятен:
В начале статьи, по традиции, поставлю цели:
- Понять весь функционал и научиться работать с Вордстатом;
- Как правильно собирать семантику с максимальной релевантностью и CTR >50%;
- Охватить тему статьи полностью и поработать с API Wordstat напрямую.
Ключевая роль сервиса заключается в том, что он помогает оценить пользовательский интерес к трендам, различным тематикам и подобрать ключевые слова для контекстной рекламы.
Для того, чтобы начать пользоваться Вордстатом, нам необходимо авторизоваться в аккаунте Яндекса:
После авторизации мы можем пользоваться сервисом. Просмотр данных поисковых запросов нам доступен во вкладке «По словам»:
В левой колонке мы видим статистику по словам, которые были вместе с вашим поисковым запросом и показы в месяц по ним. Для того, чтобы мы нашли наше слово в точном соответствии мы должны использовать операторы. В правой колонке показываются похожие по смыслу запросы на заданную нами фразу.
Наглядный пример использования ключевых слов с операторами:
Оператор "!" — фиксирует форму слова (число, падеж, время);
Оператор "[ ]" — Фиксирует порядок слов. При этом учитываются все словоформы и стоп-слова.
Подробнее об операторах читаем здесь.
По умолчанию Вордстат показывает запросы по всем типам устройств. Настройки можно изменять: десктоп/мобайл/только телефоны/только планшеты. В нашем случае отфильтруем только десктопы.
По умолчанию статистика показывается для всех регионов. Выбрать отображение статистики по интересующему нас региону можно во вкладке «Все регионы»:
Во вкладке «По регионам» отображаются данные со всех регионов, а также региональная популярность — доля, которую занимает регион в показах по слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.
Для удобства эти же данные отображаются на карте:
Во вкладке «История запросов» мы видим данные по запросу, обычно за 1,5 года. Здесь наглядно можем оценить тренды и влияние их на определенные запросы.
Статистику можно смотреть как в абсолютных значениях, так и в относительных. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
На этом изучение инструмента можно закончить и приступить к следующей нашей цели — правильному сбору семантического ядра.
В интернете уйма способов и сервисов и для сбора семантического ядра, а также искусственного его создания. Мы не будем создавать велосипед и танцевать с бубном, а соберем семантику легко, просто и бесплатно.
Для того, чтобы нам собрать нашу семантику, первым делом мы скачиваем с официального сайта Яндекса Директ Коммандер последней версии.
После загрузки запускаем программу, логинимся и создаем (без разницы с каким названием) кампанию:
Если до этого момента вы ни разу не запускали ни одной рекламной кампании на своем логине в Яндекс Директе, то вам необходимо создать любой черновик кампании через десктоп, и далее, получив все данные в Коммандер, работать с ним
Добавляем группу объявлений (по прежнему нет смысла заморачиваться с его названием):
Переходим во вкладку «Подбор фраз», и вуаля! Это тот же самый Вордстат, только в программе Директ Коммандер. Логика работы с ним такая же, только в отличии от веб версии Вордстата здесь мы можем сразу указать минус слова и отфильтровать все лишнее запросы:
После того как мы тщательно отфильтруем весь список поисковых запросов от ненужных нам запросов, можно приступать к экспорту нашей кампании в csv файл. Все, что остается нам сделать, это удалить лишние столбцы. Наше семантическое ядро находится в столбце «Фраза (с минус-словами)»:
Плюсы сбора семантики таким способом:
- Охват запросов с частотностью до 1 в месяц;
- Не наращиваем искусственную семантику, в которой наверняка будут запросы, которых в реальной истории поиска на самом деле нет;
- Увеличиваем CTR объявлений максимально (конечно не только благодаря семантике, но и правильному разбиению объявлений по кластерам запросов и их текстам. Однако все это на основе нашей семантики);
- Клики становятся дешевле;
- Это абсолютно бесплатно.
Прежде чем начать, ознакомимся с базовой информацией из справки Яндекс Директа
Описание параметров
Обязательные GET параметры
request — Данные запроса
lr — код региона, если 0 — то все регионы
imp — если 1 — то важный запрос
Ответ содержит
status — Код статуса (0 — нет ошибок)
err_msg — Текст ошибок
data — Количество показов в месяц
На этом все наши цели, которые мы поставили перед собой в начале статьи, были достигнуты.
P.S.: специально для тех, кто пишет, что таких статей полный интернет (интерфейс, семантика, API с полным изложением) - прикрепляйте в комментарии ссылки на эти статьи. Ознакомлюсь, буду благодарен.
P.S.S.: Я в курсе, что на скринах Хабр. Моя статья в начале была опубликована там. Это не мешает понять суть инструмента.
Больше статей о данных в моем телеграм-канале Нейрон (@dataisopen).
Нюанс: глядя запросы в мобайле, не забывайте,что мобайл растет сам по себе, запрос может быть просто перераспределенным из десктопа и в реале падающим, но на графике будет рост.
Если ежемесячно оценивать запросы на каком-то рынке, то можно взять 10-15 топовых, которые закроют 60% трафа и смотреть динамику. Абсолютные цифры не важны, главное - как они ведут себя от месяца к месяцу, рост или снижение.
Когда комментарий полезнее статьи.
Подобрать запросы с стр>50% это топ! Как ты узнаешь конверсию в клик не запустив кампании?
Тоже орнул с этого утверждения
40 закладок, 0 комментариев. Значит, нужный материал!
Вовсе нет. На "Полное руководство" (которое заявлено в заголовке) это совсем не тянет. Есть куда лучше маны по вордстату в сети. Объяснены лишь основные операторы ради пиара Телеграм-канала.
Скиньте ссылки на маны, которые лучше.
Обоснуйте, чего ещё не хватает в статье для полного руководства?
Тут скидывать нечего. Основа работы с вордстат - это операторы. Ты дал 2 примера про базовые операторы и отправил за остальными в гугл. Какой смысл в таком "Полном руководстве"?
А какой смысл переписывать справку? Те, кому нужно сами могут её осилить.
Одно дело прочитать методичку про операторы, а другое – показать примеры их использования для решения практических задач.
Например, мы хотим найти все фразы в 4 слова с вхождением ключевого слова "такси". Для этого используется запрос "такси такси такси такси". Это совершенно неочевидно. Вот таких практических примеров и ожидаешь от "Полного руководства", а не отсылок к манам.
В сети есть статьи с подобными практическими примерами. Они ещё как-то тянут на "Полное руководство". Твоя статья – нет.
К тому же ссылку ты даёшь на ман Яндекс.Директа, но не все механизмы Директа доступны для использования в Яндекс.Вордстате. Это всё-таки немного разные инструменты.

Так, ну что получается мы поняли. А вот чего хочется пока неясно. В каком виде нужна таблица? Есть скрин хотя бы на какой вид ты ориентируешься?
Проверил, у меня все нормально копируется. Может не нужно перед этим дважды щелкать на ячейку?
У вас есть кейсы (пусть даже минусовые, но содержательные) или полезные статьи?
Заведите блог и расскажите о своем опыте.
За каждый пост мы платим от 3 000 ₽
специальная вставка - текст, и числа в другом столбце будут
ну и перенос текста зажатый отожмите
Спасибо большое, что отвечаете! Ассистент установлен. Копирую с частотностью. Нужно, чтобы в каждой ячейке был 1 ключ, а они в одной все. А со следующей начинаются опять нормальные ячейки. И в новой книге снова так же вставляется.
Спасибо большое, что отвечаете! Ассистент установлен. Копирую с частотностью. Нужно, чтобы в каждой ячейке был 1 ключ, а они в одной все. А со следующей начинаются опять нормальные ячейки. И в новой книге снова так же вставляется.
Наталья, может ексел не правильно настроен, раз ассистент показывает такое.
Да я тоже подозреваю, что эксель не правильно работать стал. Наверно, нажала где-то не туда. А где, не знаю. Не в одном видео не нашла, как восстановить первоначальные настройки эксель.
Что значит "при выгрузке"? У вас что, Yandex Wordstat Helper установлен? Если просто "копировать - вставить" —- не получается?
Попробуйте так: выделите эту вашу ячейку (с кучей слов) и нажмите на вкладку "Данные". Выберите "Текст по столбцам", нажмите. В появившемся окошке поставьте метку (черная жирная точка) на "с разделителями". Нажмите внизу "Далее". И в открывшемся окошке поставьте галочку на "знак табуляции" (символом-разделителем является). Посмотрите чтобы в "считать последовательные разделители одним" никакой галки не стояло. А потом в маленьком окошке "ограничитель строк" выберите ограничитель (попробуйте все три по очереди).

Этот способ подбора минус-слов поможет вам, потратив всего около 10 минут времени, собрать полный список минус-слов, актуальных для вашего поискового запроса. Лайфхак поможет избавиться от показа вашего объявления на выдаче сразу всех посторонних запросов, которые довольно часто приводят на сайт нецелевых пользователей, которые, кликая по рекламе, тратят ваши деньги впустую.
- Яндекс.Вордстат;
- Microsoft Excel или его аналог;
- 10 минут времени.
Для начала введем наш запрос на Вордстате и извлечем все ключевые слова.

Можно копировать слова вручную и вставлять в Excel, а можно воспользоваться одним из многочисленных сервисов автоматического сбора. Например, есть довольно удобный плагин для Chrome - Yandex Wordstat Helper, в котором можно одним кликом скопировать все ключевые слова на одной старнице вордстата.

Далее вставляем полученный список в Excel. Теперь нам нужно убрать из него лишние символы. Это плюсики и цифры. Для этого воспользуемся инструментом “Найти и заменить” во вкладке “Главная” (Горячие клавиши Ctrl+H). Чтобы символ был удален поле “заменить на” оставляем пустым.

Теперь разделим фразы по столбцам, чтобы каждое слово находилось в отдельном столбце. Для этого воспользуемся инструментом “Текст по столбцам” во вкладке “Данные”.

Не забудьте поставить галочку на “Пробел”.

После этого объединим все столбцы в один.

Теперь нам нужно избавиться от повторяющихся строк. Для этого выделим столбец и воспользуемся инструментом “Удалить дубликаты” во всё той же вкладке “Данные”.

После этого количество строк сократится в несколько десятков раз.
Итак, мы получили готовый список практически всех слов, которые фигурируют в поисковых запросах нашей тематики. Теперь, чтобы получить именно минус-слова, не забудьте, с помощью “Найти и заменить” (Ctrl+H) удалить все нужные вам слова. В случае с доставкой пиццы это могут быть “пицца”, “вкусная”, “итальянская”, “доставка”, “быстрая” и все остальные, которые вы посчитайте полезными. Оставшийся список - и есть список минус-слов для вашей РК.
Всё для автоматизации в сети: парсеры, регеры, постеры, лайкеры. Готовые шаблоны для ZennoPoster. Шаблоны (боты) на заказ.
Быстрый способ выгрузить ключевые слова в excel из сервиса Wordstat
- Получить ссылку
- Электронная почта
- Другие приложения
Каким образом можно выгрузить ключевые слова
в excel из сервиса Wordstat ?
Чтобы не работать монотонную работу - копировать в вордстате и вставлять в экселе - достаточно воспользоваться одним из большого разнообразия парсеров вордстата. Под "парсером вордстата" тут понимается программа, которая в автоматическом режиме сканирует страницы вордстата, выгребает только нужные Вам данные и сохраняет их в эксель для дальнейшего удобного использования. В данной статье речь пойдёт о простой бесплатной программе - WordstatParser, которая не только сохраняет ключевые запросы в эксель, а ещё и грязную и точную частотку, плюс есть авторская кластеризация ключевых слов.
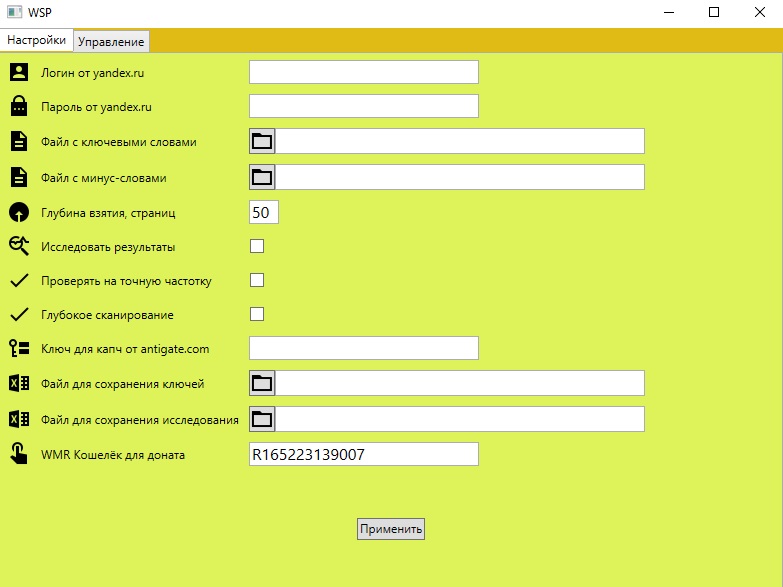
3. Файл с ключевыми словами - в данное поле указывается файл со списком ключевых слов (файл должен быть сохранён в формате utf-8, каждый ключ с новой строки), если Вы планируете активировать кластеризацию запросов после сбора, то в данном файле должна находится только 1 базовая ключевая фраза (все слова только в нижнем регистре (маленькими буквами))
4. Файл с минус-словами - в данное поле указывается файл со списком минус-слов (файл должен быть сохранён в формате utf-8, каждое минус-слово с новой строки)
5. Глубина взятия - до какой глубины парсить
6. Исследовать результаты - данная опция активирует этап кластеризации запросов, после того, как будут собраны ключи по базовой фразе (активируя данную опцию Вы обязательно должны указать файл для сохранения исследования)
7. Проверять на точную частоту - данная опция активрует сбор точной частотки по собранным ключам
8. Глубокое сканирование - данная опция активирует глубокое сканирование
9. Ключ для капч - указывать необязательно
11. Файл для сохранения исследования - эксель файл, в который будут сохраненны сгруппированые кластеры после кластеризации
Пример файла с кластерами по ключу - база клиентов.
Сказать "Спасибо" - поделитесь в соц сетях по этим кнопкам
Советы:
1. Тщательно проверяйте настройки перед запуском.
2. Если программа, после нажатия на кнопку - запустить - выключается - то скорее всего, что-то не так с настройками, либо есть повисшие процессы после предыдущего прерванного парсинга, повисшие процессы надо либо убить в диспетчере задач, либо перезагрузить компьютер.
3. Не прерывайте парсинг, дожидайтесь надписи - Все данные сохранены

Многие люди не знают, как работать с трендами в интернете, где их искать. Перед тем, как начинать бизнес не знают, где посмотреть будет ли этот бизнес вообще популярен и нужен ли он. Поэтому напишу полный туториал, чтобы закрыть все вопросы по этой тематике.
Работать мы будем со специальным сервисом по сбору поисковых запросов пользователей Яндекса Вордстатом, интерфейс которого довольно прост и понятен:
В начале, по традиции, поставлю цели:
- Понять весь функционал и научиться работать с Вордстатом;
- Как правильно собирать семантику с максимальной релевантностью и CTR >50%;
- Так как мы на Хабре, поработаем с API Wordstat напрямую.
Ключевая роль сервиса заключается в том, что он помогает оценить пользовательский интерес к трендам, различным тематикам и подобрать ключевые слова для контекстной рекламы.
Знакомство с сервисом
Для того, чтобы начать пользоваться Вордстатом нам необходимо авторизоваться в аккаунте Яндекса:

После авторизации мы можем пользоваться сервисом. Просмотр данных поисковых запросов нам доступен во вкладке «По словам»:

В левой колонке мы видим статистику по словам, которые были вместе с вашим поисковым запросом и показы в месяц по ним. Для того, чтобы мы нашли наше слово в точном соответствии мы должны использовать операторы. В правой колонке показываются похожие по смыслу запросы на заданную нами фразу.
Наглядный пример использования ключевых слов с операторами:


Оператор "!" — фиксирует форму слова (число, падеж, время);

Оператор "[]" — Фиксирует порядок слов. При этом учитываются все словоформы и стоп-слова.

Подробнее об операторах читаем здесь.
По умолчанию Вордстат показывает запросы по всем типам устройств. Настройки можно изменять: десктоп/мобайл/только телефоны/только планшеты. В нашем случае отфильтруем только десктопы.

По умолчанию статистика показывается для всех регионов. Выбрать отображение статистики по интересующему нас региону можно во вкладке «Все регионы»:

Во вкладке «По регионам» отображаются данные со всех регионов, а также региональная популярность — доля, которую занимает регион в показах по слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.

Для удобства эти же данные отображаются на карте:

Во вкладке «История запросов» мы видим данные по запросу, обычно за 1,5 года. Здесь наглядно можем оценить тренды и влияние их на определенные запросы.
Статистику можно смотреть как в абсолютных значениях, так и в относительных. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.

На этом изучение инструменты можно закончить и приступить к следующей нашей цели — правильный сбор семантического ядра.
Правильный сбор семантического ядра
В интернете уйма сервисов и способов для сбора семантического ядра, а также искусственного его создания. Мы не будем создавать велосипед и танцевать с бубном, а соберем семантику легко, просто и бесплатно.
Для того, чтобы нам собрать нашу семантику, первым делом мы скачиваем с официального сайта Яндекса Директ Коммандер последней версии.
После загрузки запускаем программу, логинимся и создаем (без разницы с каким названием) кампанию:

Добавляем группу объявлений (по прежнему нет смысле заморачиваться с его названием):

Переходим во вкладку «Подбор фраз», и вуаля! Это тот же самый Вордстат, только в программе Директ Коммандер. Логика работы с ним такая же, только в отличии от веб версии Вордстата здесь мы можем сразу указать минус слова:

После того как мы тщательно отфильтруем весь список поисковых запросов от лишних запросов, можно приступать к экспорту нашей кампании в csv файл. Все, что остается нам сделать, это удалить лишние столбцы. Наше семантическое ядро находится в столбце «Фраза (с минус-словами)»:

Плюсы сбора семантики таким способом:
- Охват запросов с частотностью до 1 в месяц;
- Не наращиваем искусственную семантику, в которой наверняка будут запросы, которых в реальной истории поиска на самом деле нет;
- Увеличиваем CTR объявлений максимально (конечно не только благодаря семантике, но и правильному разбиению объявлений по кластерам запросов и их текстам. Однако все это на основе нашей семантики);
- Клики становятся для нас дешевле;
- Это абсолютно бесплатно.
Работа с API Wordstat
Прежде чем начать, ознакомимся с базовой информацией из справки Яндекс Директа.
Описание параметров
Обязательные GET параметры
request — Данные запроса
GET параметры
lr — код региона, если 0 — то все регионы
imp — если 1 — то важный запрос
Ответ содержит
status — Код статуса (0 — нет ошибок)
err_msg — Текст ошибок
data — Количество показов в месяц
На этом все цели, которые мы поставили перед собой, в конце статьи были достигнуты.
Читайте также: