
Где вкладка данные excel
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку "Пакет анализа".
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки "Надстройка анализа", вы можете загрузить надстройку VBA так же, как и надстройку "Надстройка анализа". В поле Доступные надстройки выберите "Надстройка анализа — VBA".
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий , имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений , используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения "различаются". В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные "различаются".
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа "Описательная статистика" применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа "Экспоненциальное сглаживание" применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
Инструмент "Анализ Фурье" применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.
Инструмент "Гистограмма" применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа "Скользящее среднее" применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент "Генерация случайных чисел" применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа "Регрессия" применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа "Выборка" создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
Z-тест. Средство анализа "Две выборки для середины" выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.

Программа Excel – это не просто табличный редактор, но ещё и мощный инструмент для различных математических и статистических вычислений. В приложении имеется огромное число функций, предназначенных для этих задач. Правда, не все эти возможности по умолчанию активированы. Именно к таким скрытым функциям относится набор инструментов «Анализ данных». Давайте выясним, как его можно включить.
Включение блока инструментов
Чтобы воспользоваться возможностями, которые предоставляет функция «Анализ данных», нужно активировать группу инструментов «Пакет анализа», выполнив определенные действия в настройках Microsoft Excel. Алгоритм этих действий практически одинаков для версий программы 2010, 2013 и 2016 года, и имеет лишь незначительные отличия у версии 2007 года.
Активация
- Перейдите во вкладку «Файл». Если вы используете версию Microsoft Excel 2007, то вместо кнопки «Файл» нажмите значок Microsoft Office в верхнем левом углу окна.






После выполнения этих действий указанная функция будет активирована, а её инструментарий доступен на ленте Excel.
Запуск функций группы «Анализ данных»
Теперь мы можем запустить любой из инструментов группы «Анализ данных».
-
Переходим во вкладку «Данные».


- Корреляция;
- Гистограмма;
- Регрессия;
- Выборка;
- Экспоненциальное сглаживание;
- Генератор случайных чисел;
- Описательная статистика;
- Анализ Фурье;
- Различные виды дисперсионного анализа и др.

Работа в каждой функции имеет свой собственный алгоритм действий. Использование некоторых инструментов группы «Анализ данных» описаны в отдельных уроках.
Как видим, хотя блок инструментов «Пакет анализа» и не активирован по умолчанию, процесс его включения довольно прост. В то же время, без знания четкого алгоритма действий вряд ли у пользователя получится быстро активировать эту очень полезную статистическую функцию.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.

Группа Подключения. С помощью команды Подключения этой группы можно импортировать данные в таблицу из разных внешних источников, например из Интернета или из другого файла. В этой группе указаны все подключения, которые используются (если такие есть) в таблице. Здесь же вы сможете изменить их свойства.
Сортировка и фильтр. Подобные команды мы уже рассмотрели при изучении группы Редактирование вкладки Главная (см. «Работа с содержимым ячеек»).
Работа с данными
Теперь рассмотрим инструменты группы Работа с данными.
Текст по столбцам. Эта кнопка поможет вам разделить информацию в столбце. Например, вы ввели в один столбец имена и фамилии. Можете сделать так, чтобы имена отделились от фамилий в отдельный столбец (рис. 6.2). Только между частями той информации, которую вы собираетесь разделять, должен стоять одинаковый для всех «разделитель». Например, знак пробела. Или запятая.

Рис. 6.2. Текст по столбцам: а — до разделения, б — после
В данном случае символом-разделителем является пробел, что вам и нужно будет отметить в одном из появившихся окон.

Рис. 6.3. Исходная таблица (а) и таблица с удаленными строками-дублями (б)

Рис. 6.4. Отчет о проделанной работе
Проверка данных. Эта команда позволит вам ставить свои условия тем, кто будет вводить данные в таблицу. Например, вы объявляете голосование, когда каждый участник должен проставить в таблице баллы от 1 до 10. Голосовать будем за картины. Вот такая таблица получилась у меня (рис. 6.5)
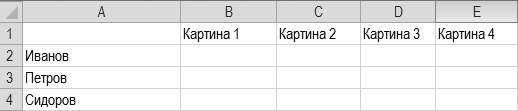
Рис. 6.5. Таблица, сделанная для голосования
Выделите ту область таблицы, где будут выставляться оценки, и нажмите кнопку Проверка данных. В открывшемся окне Проверка вводимых данных перейдите на вкладку Параметры, если она не открылась сразу. Укажите нужные значения (рис. 6.6).

Рис. 6.6. Ставим условие
Здесь нужно набрать текст, появляющийся на экране в тот момент, когда человек выделит ячейку, в которую будет вводить оценку (рис. 6.8).
Я обращаю ваше внимание на список Вид.

Рис. 6.11. Обвели неверные значения
Ах, Сидоров, Сидоров… Теперь его оценку придется аннулировать. Чтобы не расстраиваться, можете удалить обводку неверных данных (в списке кнопки Проверка данных).
Мы рассмотрели один из вариантов фильтра вводимых в таблицу значений. Теперь вернемся к рис. 6.6. Если вы откроете список Тип данных, то увидите, что можно выбрать (рис. 6.12).
Рис. 6.12. Выбираем условие
Есть такие варианты.
- Любое значение — текст, число…
- Целое число — тут все понятно.
- Действительное — любое положительное, отрицательное число. Или ноль.
- Список — вы можете ввести список допустимых значений в диапазон ячеек и дать ссылку на этот диапазон.
- Дата — вы сможете установить пограничные даты (например, «не позже чем») или промежуток между двумя датами.
- Время — вы можете установить пограничное время. Или промежуток времени.
- Длина текста — вы можете ограничить длину текста.
Консолидация. Эта команда позволяет объединить диапазоны ячеек и просто ячейки в один большой новый диапазон.
Анализ «что если». Дает возможность подбирать данные. Если вы еще помните, как подгоняли данные, которые должны получиться в лабораторной работе, под ответ, то в этой функции для вас не будет практически ничего нового. Первым в списке кнопки Анализ «что если» идет Диспетчер сценариев. Его применение я объясню на примере. На рис. 6.13 показана таблица для расчета денег, которые нужно собрать на питание в классе.

Рис. 6.13. Исходные данные
Из таблицы понятно, что в классе 25 детей, из них 3 льготника и 5 отказались от питания. Ячейку A3 я назвала Цена_обеда. Думаю, вы легко догадаетесь, что именно в ней находится. В ячейке А4 — сумма, которую нужно собрать с класса. Рассчитывается она по формуле, показанной на рис. 6.14.
![]()
Рис. 6.14. Формула для расчета денег на обеды
Это мы так ненавязчиво повторяем весь пройденный материал. Тут вам и ячейки с именем, и формулы… Как видите, количество питающихся за полную стоимость детей мы умножаем на цену обеда и прибавляем льготников, то есть тех, кто ест за полцены. Если понадобится рассчитать сумму для другого класса, то необходимо будет ввести другой набор цифр. Для третьего класса — третий набор. А что делать, если вам для этих классов нужно не только питание рассчитать, но еще и миллион бумажек заполнить? Смело выбирайте строку Диспетчер сценариев кнопки Анализ «что если»! Откроется окно (рис. 6.15).

Рис. 6.15. Окно Диспетчер сценариев
Не пугайтесь непонятного названия, нажимайте кнопку Добавить, сейчас все станет ясно. Есть диапазон ячеек B2:D2. Я хочу, чтобы была возможность вводить в этот диапазон данные разных классов, причем вводить сразу «оптом». Сценарий в этом случае — это запомненные значения для диапазона ячеек, которым вы можете дать имя (рис. 6.16).

Рис. 6.16. Создаем сценарий
Выделяем нужный диапазон, его адрес отобразиться в поле Изменяемые ячейки. Даем им название 1 «А». Нажимаем ОК. В следующем окне подтверждаем значения ячеек сценария (рис. 6.17).

Рис. 6.17. Значения ячеек сценария
Опять откроется окно Диспетчер сценариев. В то, что вы видите на рис. 6.18, я добавила еще два сценария, в которые ввела данные для двух других первых классов.

Рис. 6.18. Выбираем сценарий
Здесь есть такие кнопки:
- Добавить — добавляет новый сценарий;
- Удалить — удаляет выбранный сценарий;
- Изменить — изменяет данные в сценарии;
- Объединить — объединяет сценарии;
- Отчет — представляет отчет о результатах расчетов;
- Вывести — применяет сценарий к таблице, то есть подставляет выбранный набор данных и рассчитывает результат. Очень быстро и удобно.
Далее в списке кнопки Анализ «что если» идет команда Подбор параметров. Она и позволяет выполнить ту самую подгонку данных лабораторной работы под результат. Берем лабораторную работу по физике за 9 класс, например, на тему «Определение модуля упругости обычной резинки». Берем круглую резинку, длиной l0 и диаметром D, подвешиваем на ней груз весом F. Резинка растягивается, и ее длина становится равной l. Модуль упругости рассчитывается по формуле: Eпр = 4Flo / πD 2 (l — lo). Результат рассчитывается по формуле, которую вы видите в строке формул на рис. 6.19. Сама формула находится в ячейке А2.

Рис. 6.19. Пишем программу для определения модуля упругости
Здесь: В2 — начальная длина резинки (0,1 м = 10 см); С2 — конечная длина резинки (0,13 м = 13 см); D2 — вес (0,5 Н, подвесили грузик массой 50 г). Если вы не помните, что такое граммы и ньютоны и чем вес отличается от массы, не пугайтесь. Я, собственно, просто собиралась рассказать, как подогнать результат лабораторки, но тут во мне проснулся физик. Так что терпите; Е2 — диаметр резинки (у нас резинка кругленькая, типа «моделька», диаметр 0,02 м = 2 мм); F2 — число пи. Подставив числа в формулу, мы получили модуль упругости, равный 530 516. Табличное же значение модуля упругости для резины — 7 • 106 Па.
Поступим следующим образом (рис. 6.20).

Рис. 6.20. Подгоняем ответ
Нужно подобрать в ячейке А2 значение 7 • 106, изменяя значения ячейки С2. То есть программа нам сейчас найдет такое значение конечной длины резинки, при котором модуль упругости будет совпадать с табличным. И это значение равно… 0,102 м. То есть «моделька», на которую подвесили груз массой 50 г, практически не должна изменить длину. Вернее, она растянется, но измерить это изменение обычной линейкой невозможно. А можно еще «попросить» программу подогнать вес груза. Подобрать в ячейке А1 значение 7 • 106, изменяя значение ячейки В1. После подгонки мы узнаем, что для того, чтобы модуль упругости совпал с табличным, нужно, чтобы наша резинка растянулась на 3 см при весе… 44 кг. Отсюда вывод: табличное значение модуля упругости для «модельки» не подходит. Так и расскажем бедным девятиклассникам, которые делают эту лабораторную работу.
Все, физика в себе я усыпила. Переходим к следующей строке в списке команды Анализ «что если».
Таблица данных. Это самая загадочная команда. Честно говорю, я целый вечер безуспешно пыталась разобраться в том, как она работает. В итоге, обложившись инструкциями и взяв помощь зала мужа, таки разобралась. И я вам скажу честно — оно того не стоит. Эта команда дает возможность ввести в диапазон ячеек данные, а потом эти данные по очереди подставить в формулу. Гораздо проще применить автозаполнение. Тех, кто не помнит, как это делается, отправляю к статье про Автозаполнение. Результат тот же, а объяснять просто в разы меньше.

Одной из самых интересных функций в программе Microsoft Excel является Поиск решения. Вместе с тем, следует отметить, что данный инструмент нельзя отнести к самым популярным среди пользователей в данном приложении. А зря. Ведь эта функция, используя исходные данные, путем перебора, находит наиболее оптимальное решение из всех имеющихся. Давайте выясним, как использовать функцию Поиск решения в программе Microsoft Excel.
Включение функции
Можно долго искать на ленте, где находится Поиск решения, но так и не найти данный инструмент. Просто, для активации данной функции, нужно её включить в настройках программы.
Для того, чтобы произвести активацию Поиска решений в программе Microsoft Excel 2010 года, и более поздних версий, переходим во вкладку «Файл». Для версии 2007 года, следует нажать на кнопку Microsoft Office в левом верхнем углу окна. В открывшемся окне, переходим в раздел «Параметры».

В окне параметров кликаем по пункту «Надстройки». После перехода, в нижней части окна, напротив параметра «Управление» выбираем значение «Надстройки Excel», и кликаем по кнопке «Перейти».

Открывается окно с надстройками. Ставим галочку напротив наименования нужной нам надстройки – «Поиск решения». Жмем на кнопку «OK».

После этого, кнопка для запуска функции Поиска решений появится на ленте Excel во вкладке «Данные».

Подготовка таблицы
Теперь, после того, как мы активировали функцию, давайте разберемся, как она работает. Легче всего это представить на конкретном примере. Итак, у нас есть таблица заработной платы работников предприятия. Нам следует рассчитать премию каждого работника, которая является произведением заработной платы, указанной в отдельном столбце, на определенный коэффициент. При этом, общая сумма денежных средств, выделяемых на премию, равна 30000 рублей. Ячейка, в которой находится данная сумма, имеет название целевой, так как наша цель подобрать данные именно под это число.

Коэффициент, который применяется для расчета суммы премии, нам предстоит вычислить с помощью функции Поиска решений. Ячейка, в которой он располагается, называется искомой.

Целевая и искомая ячейка должны быть связанны друг с другом с помощью формулы. В нашем конкретном случае, формула располагается в целевой ячейке, и имеет следующий вид: «=C10*$G$3», где $G$3 – абсолютный адрес искомой ячейки, а «C10» — общая сумма заработной платы, от которой производится расчет премии работникам предприятия.

Запуск инструмента Поиск решения
После того, как таблица подготовлена, находясь во вкладке «Данные», жмем на кнопку «Поиск решения», которая расположена на ленте в блоке инструментов «Анализ».

Открывается окно параметров, в которое нужно внести данные. В поле «Оптимизировать целевую функцию» нужно ввести адрес целевой ячейки, где будет располагаться общая сумма премии для всех работников. Это можно сделать либо пропечатав координаты вручную, либо кликнув на кнопку, расположенную слева от поля введения данных.

После этого, окно параметров свернется, а вы сможете выделить нужную ячейку таблицы. Затем, требуется опять нажать по той же кнопке слева от формы с введенными данными, чтобы развернуть окно параметров снова.

Под окном с адресом целевой ячейки, нужно установить параметры значений, которые будут находиться в ней. Это может быть максимум, минимум, или конкретное значение. В нашем случае, это будет последний вариант. Поэтому, ставим переключатель в позицию «Значения», и в поле слева от него прописываем число 30000. Как мы помним, именно это число по условиям составляет общую сумму премии для всех работников предприятия.

Ниже расположено поле «Изменяя ячейки переменных». Тут нужно указать адрес искомой ячейки, где, как мы помним, находится коэффициент, умножением на который основной заработной платы будет рассчитана величина премии. Адрес можно прописать теми же способами, как мы это делали для целевой ячейки.

В поле «В соответствии с ограничениями» можно выставить определенные ограничения для данных, например, сделать значения целыми или неотрицательными. Для этого, жмем на кнопку «Добавить».

После этого, открывается окно добавления ограничения. В поле «Ссылка на ячейки» прописываем адрес ячеек, относительно которых вводится ограничение. В нашем случае, это искомая ячейка с коэффициентом. Далее проставляем нужный знак: «меньше или равно», «больше или равно», «равно», «целое число», «бинарное», и т.д. В нашем случае, мы выберем знак «больше или равно», чтобы сделать коэффициент положительным числом. Соответственно, в поле «Ограничение» указываем число 0. Если мы хотим настроить ещё одно ограничение, то жмем на кнопку «Добавить». В обратном случае, жмем на кнопку «OK», чтобы сохранить введенные ограничения.

Как видим, после этого, ограничение появляется в соответствующем поле окна параметров поиска решения. Также, сделать переменные неотрицательными, можно установив галочку около соответствующего параметра чуть ниже. Желательно, чтобы установленный тут параметр не противоречил тем, которые вы прописали в ограничениях, иначе, может возникнуть конфликт.

Дополнительные настройки можно задать, кликнув по кнопке «Параметры».

Здесь можно установить точность ограничения и пределы решения. Когда нужные данные введены, жмите на кнопку «OK». Но, для нашего случая, изменять эти параметры не нужно.

После того, как все настройки установлены, жмем на кнопку «Найти решение».

Далее, программа Эксель в ячейках выполняет необходимые расчеты. Одновременно с выдачей результатов, открывается окно, в котором вы можете либо сохранить найденное решение, либо восстановить исходные значения, переставив переключатель в соответствующую позицию. Независимо от выбранного варианта, установив галочку «Вернутся в диалоговое окно параметров», вы можете опять перейти к настройкам поиска решения. После того, как выставлены галочки и переключатели, жмем на кнопку «OK».

Если по какой-либо причине результаты поиска решений вас не удовлетворяют, или при их подсчете программа выдаёт ошибку, то, в таком случае, возвращаемся, описанным выше способом, в диалоговое окно параметров. Пересматриваем все введенные данные, так как возможно где-то была допущена ошибка. В случае, если ошибка найдена не была, то переходим к параметру «Выберите метод решения». Тут предоставляется возможность выбора одного из трех способов расчета: «Поиск решения нелинейных задач методом ОПГ», «Поиск решения линейных задач симплекс-методом», и «Эволюционный поиск решения». По умолчанию, используется первый метод. Пробуем решить поставленную задачу, выбрав любой другой метод. В случае неудачи, повторяем попытку, с использованием последнего метода. Алгоритм действий всё тот же, который мы описывали выше.

Как видим, функция Поиск решения представляет собой довольно интересный инструмент, который, при правильном использовании, может значительно сэкономить время пользователя на различных подсчетах. К сожалению, далеко не каждый пользователь знает о его существовании, не говоря о том, чтобы правильно уметь работать с этой надстройкой. В чем-то данный инструмент напоминает функцию «Подбор параметра…», но в то же время, имеет и существенные различия с ним.
Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Вкладка Вид ленты отвечает за то, как выглядит документ на экране (рис. 5.1). Обратите внимание, это именно вид документа на экране. С самим документом ничего не происходит, вам просто будут показывать его в разном виде.

Рис. 5.1. Вкладка Вид
Рассмотрим, какие есть режимы отображения документа на экране.
Обычный. В этом виде сделаны все предыдущие иллюстрации (рис. 5.2). Сплошная таблица, на которой может быть черный пунктир, в данном случае между столбцами G и H, обозначающий границу печатной страницы.

Рис. 5.2. Вид Обычный
Разметка страницы. В этом режиме страница показана так, как она будет выглядеть на печати (рис. 5.3). При этом отображаются колонтитулы. Появились горизонтальные и вертикальные линейки, чтобы вы видели ширину полей (пустое место по бокам листа) и могли оценить реальную ширину ваших строк и столбцов. Кстати, вы вполне можете поменять их габариты, если они вас не устраивают.

Рис. 5.3. Разметка страницы
Страничный режим. Для этого режима мне понадобился большой документ, написанный в Excel (рис. 5.4). В данном режиме страницы документа показаны так, как они будут выглядеть на печати. Границы подвижны! Вы можете просто подвинуть их мышкой как вам нужно. Только учтите, что лист бумаги не безразмерный и чем больше информации вы захотите на него впихнуть, тем мельче она будет отображаться.

Рис. 5.4. Страничный режим
Что делать? Например, скрыть ненужные столбцы, перевернуть лист или сделать так, чтобы документ печатался в альбомной ориентации листа. Изменить ориентацию можно на вкладке Разметка страниц в группе Параметры страницы, нажав кнопку Ориентация. Подробнее об этой вкладке — в следующей публикации.
Представления. Допустим, вы будете много работать с прайс-листами. И вы уже поняли, что удобнее всего смотреть на экране и распечатывать прайс именно в альбомной ориентации. Значит, вы можете запомнить удобное вам представление листа. Представление листа может включать в себя параметры печати. А потом, открыв новый прайс, применить к нему это представление, и он предстанет перед вами на экране в удобном и привычном для вас виде.
Во весь экран. Этот режим предназначен для чтения: с экрана убирается все ненужное, остается только документ. Чтобы вернуться к привычному окну программы, нажмите Esc.
Читайте также: