
Файлы объединяющие текстовые xml и битовые форматы
Двоичное представление Python и битовые манипуляции
Все мы знаем, что вся информация в компьютере в конечном итоге представлена двоичными 0 и 1, а некоторые алгоритмы управляются рабочими битами. Это требует от нас понимания того, как представлять двоичные файлы в Python и как это делать.
Двоичное представление
Прежде всего, в Python вы можете использовать строку, начинающуюся с «0b» или «-0b» для представления двоичного файла, как показано ниже.
Из этого мы видим, что числа, которые мы представляем в двоичном формате, станут более привычными десятичными числами после печати, и их будет легче понять.
Когда нам нужно увидеть двоичное представление десятичных чисел, мы можем использовать функцию bin
Манипуляции с двоичными битами
Первое, что необходимо прояснить, - это то, что все операции (включая битовые) выполняются на компьютере в виде дополнений. Дополнительные сведения см. В статьеИсходный код, его дополнение и дополнение, Внутренняя расчетная схема компьютера выглядит следующим образом:
В Python предусмотрены следующие двоичные битовые операции:
Давайте посмотрим отдельно ниже:
Сдвиг влево
- Если взять в качестве примера 0b11, дополнение к 0b11 равно 0b11, поэтому сдвиг влево должен сдвинуть все позиции 0 и 1 влево, а затем добавить 0 к пробелу после сдвига.
- Сдвиг отрицательного числа влево относительно сложен. Если взять -2
- Сдвиг влево на 32 или 64 бита (в зависимости от системы) автоматически преобразуется в длинный тип.
- Операция сдвига влево эквивалентна умножению на 2 ** n, взяв в качестве примера 5 (2* 3) результат 40.
Сдвиг вправо
- В Python, если бит знака равен 0, старший бит заполняется 0 после сдвига вправо, а если бит знака равен 1, старший бит заполняется 1;
- Перед вычислением его также необходимо преобразовать в одно дополнение. Если взять -8 >> 3 в качестве примера, исходный код -8 - 10 . 01000, а соответствующее дополнение - 11 . 11000, которое становится 1 после сдвигаясь вправо. ..1, соответствующий исходный код будет 10 . 01, то есть -1.
- Операция сдвига вправо эквивалентна делению на 2 ** n, 8 >> 3 эквивалентно 8 / (2 ** 3) = 1
или же
То же самое преобразуется в дополнение до одного перед выполнением операции ИЛИ, если в одном бите есть 1, это 1.
Поэтому операция ИЛИ часто используется для включения переключателя в технологии масок, то есть для установки его в 1 для определенного бита.
Например, чтобы установить третью позицию числа равным 1, мы можем установить маску на 0b100, а затем ИЛИ
против
И часто используется операция по отключению технологии маски, то есть установка ее на 0 для определенного бита.
XOR часто используется для инвертирования всех битов
Операция not заключается в изменении 0 на 1 и 1 на 0. Единственное, что необходимо отметить, это то, что бит знака также изменится при отрицании, например -3, исходный код 10 . 011, дополнение - 11 . 101, а отрицание. После того, как оно становится 00 . 010, поскольку бит знака равен 0, соответствующий исходный код равен самому себе, то есть 2.
Бинарный инструмент
bitarray
Существует очень полезный пакет для битов, называемый bitarray, где объект bitarray может помочь нам хранить 0, 1 или логические значения и работать как список.
Описание bitarrary см. На Github.проект bitarray
Применение битовых операций
Общие приложения, такие как оценка четных и нечетных чисел X и 0x1, изменение знакового бита ~ X + 1, обмен числами и т. Д., Подробнее см. В статье по ссылке.
Далее автор хотел бы проиллюстрировать применение битовых манипуляций на примере реального проекта.
В следующей таблице приведено описание заголовка пакета TS (поток TS является широко используемым форматом передачи в индустрии потокового мультимедиа). Мы видим, что для уменьшения ненужных потерь заголовок пакета определяется бит за битом при определении домена, тогда, если мы хотим получить значение соответствующего поля, вам нужно использовать битовые операции.
Заголовок пакета (заголовок пакета) описание информации
| Серийный номер | имя | номер бита | описание |
|---|---|---|---|---|
| 1 | sync_byte | 8 бит | Байт синхронизации |
| 2 | transport_error_indicator | 1bit | Информация об индикации ошибки (1: пакет имеет ошибку передачи не менее 1 бита) |
| 3 | payload_unit_start_indicator | 1bit | Флаг начала загрузки блока (заполняется, если размер пакета меньше 188 байт) |
| 4 | transport_priority | 1bit | Флаг приоритета транспорта (1: высокий приоритет) |
| 5 | PID | 13bits | Номер идентификатора пакета, уникальный номер соответствует разным пакетам |
| 6 | transport_scramble_control | 2 бита | Флаг шифрования (00: незашифрованный; другие средства зашифрованы) |
| 7 |ization_field_control | 2 бита | Дополнительное поле управления |
| 8 | непрерывность_счетчика | 4 бита | Счетчик приращения пакета |
В качестве примера возьмем значение PID. После того, как мы получим байтовую строку заголовка пакета, нам потребуются следующие шаги:
- Вам нужно получить второй байт, а затем игнорировать старшие три бита второго байта (вы можете видеть из таблицы, что старшие три бита - это другая информация, не имеющая ничего общего с PID);
- Сдвиньте последние 5 цифр второго байта на 8 цифр влево, таким образом переместив его в старшую цифру;
- После сдвига добавьте значение 3-го байта, чтобы получить значение PID.
Чтобы выполнить первый шаг, мы должны сначала использовать технологию масок, обычно используемую в битовых операциях, то есть выполняя операции & над значением соответствующего бита как 0
Чтобы выполнить второй шаг, вам необходимо использовать операцию сдвига влево.После операции сдвига влево значение третьего байта добавляется к фактическому значению PID.
Полная реализация кода выглядит следующим образом:
1, ord () преобразует байтовую строку в соответствующее число для выполнения битовой операции;
2, 0x1f - шестнадцатеричное представление, преобразованное в двоичное - 0b00011111.
Python понимает все популярные форматы файлов. Кроме того, у каждой библиотеки есть свой, «теплый ламповый», формат. Синтаксис, разумеется, у каждого формата сугубо индивидуален. Я собрал все функции для работы с файлами разных форматов на один лист A4, с приложением в виде примера использования в jupyter notebook.

Я условно разделил форматы на три блока по способу использования. Как известно, файлы нужны для обмена информацией: между людьми, между программами (первый блок), между компьютером и сетью (второй) и «save game» – между одной и той же программой в разные моменты времени (третий блок).
Вкратце о каждом блоке:
1) Универсальные форматы:
- .csv – текстовый, значения, разделённые по идее запятыми (comma separated), но например, русский эксель предпочитает разделять точками с запятыми, поскольку в русской локали запятая уже используется – в качестве десятичного разделителя;
- .raw – бинарный формат для тех, кто не любит форматы файлов. Тип данных и, если данные многомерные, соответствующие размеры должны передаваться отдельно, в файле только сами данные;
- .xls/.xlsx – старый бинарный (ограничение в 65k строк) и новый xml’ный форматы экселя;
- .mat – это на самом деле тоже два формата (оба бинарные): старый проприетарный и новый на основе hdf5. Питон умеет работать с обоими (через библиотеки).
- .json – текстовый, выглядит как словарь в питоне, но кавычки можно использовать только двойные;
- .xml – текстовый, похож на html.
- .pkl – бинарный формат, в него умеют сохраняться все встроенные питоновские объекты. Пользовательские классы тоже умеют, а если питон сохраняет как-то не так, можно ему помочь через магические методы. Поддерживает дописывание в конец существующего файла (appending).
- .npy и .npz – в numpy аж целых два своих формата (оба бинарные). Появились как реакция на потерю обратной совместимости у pkl в момент перехода python v2->v3. Накладные расходы минимальные (~ на 100 байт больше, чем соответствующий raw; pkl, впрочем, немногим больше: на ~150 байт больше raw). В .npy можно сохранить только один массив, а в npz – сразу несколько, причём достать их оттуда впоследствии можно по имени.
- .h5 – бинарный формат hdf5. Примечателен тем, что в нем можно хранить целую иерархическую структуру данных, это практически файловая система в одном файле. Кроме того, его можно открыть в matlab без конвертации. Минусы:
a) небольшие файлы занимают неоправданно много места (например, 300 байт pkl vs 3.1 Мb у h5),
b) много багов,
c) есть дописывание в существующий файл, но если при этом случится ошибка (а так бывает), данные из него достать будет проблематично.

– в формате pdf
– в формате png:
Пример использования всех функций с диаграммы: html с оглавлением и ipynb-исходником
В чем прелесть XML? Он реализован под все платформы, «человекочитаемый», для него созданы схемы данных (условно человекочитаемые). Открывая 25-мегабайтный файл в браузере сразу замечаешь недостатки этого текстового формата, и начинаешь задумываться. Делаем мы это, конечно, не часто, но все же — чем бы заменить XML?
Добавление самопальных бинарных контейнеров в проект заканчивается провалом, когда к вам приходят партнеры и просят подключить их к этому каналу данных. Google Protobuf поначалу выглядит хорошо, но вскоре понимаешь, что это не замена для XML, не хватает функциональности. BSON в 5 раз медленнее Protobuf, уступает в компактности и для него не реализованы схемы данных.
Разработаем же еще один бинарный формат.
USDS (или $S) — Universal serialized data structures — универсальные сериализованные структуры данных, бинарный формат, способный полностью заменить XML и JSON. Основные отличия:
- Вместо текстовых тегов/ключей используются целые числа. Соотношение «Имя» — «Целочисленный идентификатор» задается отдельно, в «Словаре». Словарь может быть прикреплен к документу USDS или может быть передан отдельно.
- Нет закрывающих тегов, как в XML;
- Документы USDS формируются строго по схеме, которая также задается в Словаре. Поддерживаются полиморфизм и опциональные поля.
- Числовые значения в документе USDS хранятся в бинарном виде (не как текст).


Что-то в этом уже есть, хотя работы еще не мало: Basic Parser всегда будет уступать Google Protobuf, но не на столько же.
Хоть формат и бинарный, использовать его не сложнее, чем XML. Посмотрим, как это будет выглядеть на С++ (а в далеком светлом будущем и на других языках).
Шаг 1: составляем Словарь
Как было сказано выше, документ USDS строится только по схеме, которая может выглядеть так:
Все правила построения схемы можно посмотреть здесь. Библиотека USDS Basic Parser пока что поддерживает далеко не все элементы схемы, но пример выше — рабочий. Сохраняем схему в текстовый файл, или вставляем прямо в исходный код, что дальше?
Шаг 2: инициализируем парсер:
Так или иначе, схема данных оказалась в массиве «text_dictionary», скормим его парсеру:
Парсер готов генерировать бинарные USDS документы. Если вам необходимо только декодировать бинарники, то инициализация словарем не требуется: парсер автоматически вытащит словарь прямо из бинарного документа USDS.
Шаг 3: создаем бинарный документ:
Алгоритм ничем не отличается от работы с любым другим DOM-парсером: добавляем несколько корневых объектов, инициализируем их значениями, генерируем выходной массив данных.
Особенности работы с массивами опущены, вы можете посмотреть их отдельно, скачав исходный код примера.
Шаг 4: декодирование бинарного документа:
Для чистоты эксперимента создадим отдельный объект парсера, не будем его инициализировать словарем и посмотрим, разберет ли он наш бинарный документ:
Обратите внимание, что «Сервер» заранее ничего не знает о схеме данных, но спокойно получил бинарник, нашел в нем поля по их текстовым именам и корректно преобразовал их в значения переменных С++. Именно эта функция недоступна в Google Protobuf и ASN.1.
Вы можете существенно ускорить программу, если будете инициализировать поля по их числовым идентификаторам (ID, совпадают с теми, что указаны в Словаре), смотрите исходный код примера.
Это действительно очень важная функция: вы не можете прочитать посторонний бинарный пакет Google Protobuf или ASN.1 (кроме XER), а иногда очень хочется. При использовании BSON можно преобразовать любой пакет данных в JSON, что уже неплохо. Не отстает от него и USDS:
Сервер не только получил произвольный бинарный документ, но и смог преобразовать его в JSON. Ту же операцию можно было выполнить и на стороне «Клиента»: сформировать DOM-объект и сразу преобразовать его в JSON, который также строго соответствует схеме данных.
В планы разработки USDS заложен редактор документов USDS с полноценным GUI. В ближайшем будущем в USDS Basic Parser будет реализована конвертация между XML, JSON и USDS в любом направлении.
Зачем я опубликовал сырой продукт (Pre-Alpha), который настоятельно не рекомендуется использовать в проектах? Мне важен ваш отклик:
- чего не хватает в продукте?
- нужен ли он вообще?
- понятно ли написана документация и исходный код?
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
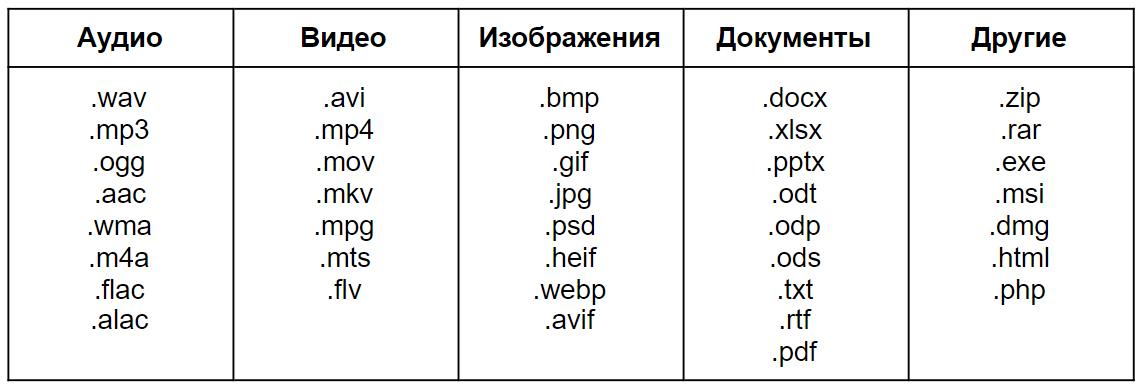
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Проще говоря, растровое изображение - это изображение, состоящее из одного пикселя. Распространенными форматами изображений являются jpg (jpeg), png и bmp, все они растровые.
1.2 Вектор
Векторная графика - это геометрические примитивы, основанные на математических уравнениях, таких как точки, линии или многоугольники в компьютерной графике для представления изображений.
---- Википедия
Векторная диаграмма отличается от растрового изображения тем, что она не состоит из одного пикселя, а ее суть - математическое выражение. Файл формата svg представляет собой векторную диаграмму.
1.3 Разница между растровым изображением и векторной диаграммой
Наиболее очевидная разница между растровым изображением и векторной диаграммой:Мозаика появится, когда растровое изображение будет увеличено, и качество изображения ухудшится; векторную графику можно бесконечно увеличивать без снижения качества изображения.

Источник изображения: Википедия
На рисунке a представляет исходное изображение. Если a - векторная диаграмма, когда изображение в красной рамке увеличивается, эффект аналогичен b, и вы можете видеть, что качество изображения не снизилось; если a - растровое изображение, когда изображение в красной рамке увеличивается , эффект похож на c, и отчетливо видны один за другим маленькие квадратики, качество изображения значительно снижается.
1.4 Как выразить цвет пикселей
Выберите растровое изображение и увеличьте масштаб до 3200% в PS, как вы можете видеть ниже:
![[ , , (img-MESatFy9-1573204554252)(img/image-20191102143341677.jpg)]](https://russianblogs.com/images/304/0d0b2383d47b2e6be66ab5a00da159d8.jpg)
Вы можете ясно видеть один за другим маленькие квадратики, которые являются пикселями.
Пиксель имеет определенное положение и значение цвета. Цвет каждого пикселя представлен комбинацией RGB или значением серого.
В этом разделе основное внимание уделяется тому, как представлять цвета.
По битовой глубине растровые изображения можно разделить на 1, 4, 8, 16, 24 и 32-битные изображения. Битовая глубина здесь относится к количеству битов, используемых для представления цвета пикселя. Если пиксель представлен одним битом цвета, его битовая глубина равна 1, если пиксель представлен четырьмя битами цвета, его битовая глубина равна 4 и так далее.
- Если пиксели изображения1 битДля представления цвета этот бит равен 0 или 1, тогда он может представлять 2 1 Два цвета, а именно черный и белый, фото чисто черно-белое фото.
Если пиксели изображения8 битДля представления цвета эти восемь битов могут представлять 2 8 Цвета, 256. Такой образобычно(Есть исключения, я расскажу об этом ниже) называетсяОттенки серого, Потому что эти 256 цветов являются черным и белым серым (серый здесь означает 244 различных степени серого). Изображение в градациях серого выглядит следующим образом:
Если пиксели изображения24 битДля представления цвета эти 24 бита могут представлять 2 24 Есть более 16 миллионов цветов. Это изображение называетсяКарта истинного цвета. Эти 24 бита разделены на три канала по 8 бит, которые представляют красный, зеленый и синий соответственно. Это метод цветового кодирования RGB, который использует оптическую интенсивность трех основных цветов - красного, зеленого и синего - для представления цвета. Это наиболее распространенный метод кодирования растровых изображений, который можно напрямую использовать для отображения на экране.
2. Формат файла BMP
2.1 Введение в BMP
BMPВзято из сокращения bitmap Bitmap, также известного как DIB (device-independent bitmap), является независимым от дисплеябитовая картаФормат файла цифрового изображения. Обычно встречается в операционных системах Microsoft Windows и OS / 2. ---- Википедия
Формат BMP - это формат, представляющий растровое изображение.
Разрядность пикселей в изображениях формата BMP может быть 1, 4, 8, 24, 32, но обычные битовые глубины BMP по-прежнему равны 8 и 24.
Выберите изображение BMP, щелкните правой кнопкой мыши, чтобы открыть Свойства -> Детали, вы можете просмотреть его битовую глубину.
Когда битовая глубина файла BMP равна 8, это не обязательно означает, что изображение в оттенках серого, как показано ниже:
Разрядность этого изображения составляет 8, но это не изображение в оттенках серого, мы его называемПсевдоцветная карта。
Следующее изображение представляет собой полноцветное изображение с битовой глубиной 24, которое можно использовать для сравнения:
Видно, что качество изображения в истинных цветах значительно выше, чем у изображения в ложных цветах.
2.2 Составление формата файла BMP
Файл BMP состоит из следующих четырех частей:
- Заголовок растрового файла (BITMAPFILEHEADER)
- Заголовок растровой информации (BITMAPINFOHEADER)
- Таблица цветов * (RGBQUAD [])
- Массив пикселей (Pixels [] [])
Поскольку таблица цветов не обязательно существует, добавьте * Описание.
Кратко объясним информацию о каждой части ниже:
2.2.1 Заголовок растрового файла
Используется для описания состояния всего файла BMP, включая такую информацию, как тип, размер файла и начальная позиция растрового изображения файла BMP.
Заголовок файла растрового изображения имеет в общей сложности14 байт。
2.2.2 Заголовок информации о растровом изображении
Используется для описания такой информации, как размер растрового изображения.
Общий заголовок информации о растровом изображении40 байт。
2.2.3 Таблица цветов
Он используется для описания цвета в растровом изображении.Он имеет несколько элементов таблицы.Каждый элемент таблицы представляет собой структуру типа RGBQUAD, которая определяет цвет.
Вы можете видеть, что запись в таблице RGB4 байта。
Количество данных структуры RGBQUAD в таблице цветов определяется заголовком информации о битовой карте.biBitCountЧтобы убедиться:
- Когда biBitCount = 1, 4, 8, есть 2, 16 и 256 записей соответственно.
- При biBitCount = 24 элемент таблицы цветов отсутствует.
2.2.4 Массив пикселей
l Запишите значение каждого пикселя растрового изображения, порядок записи - слева направо в пределах строки развертки и снизу вверх между строками развертки. Количество байтов, занимаемых значением пикселя растрового изображения, выглядит следующим образом:
Когда biBitCount = 1, 8 пикселей занимают 1 байт;
Когда biBitCount = 4, 2 пикселя занимают 1 байт;
Когда biBitCount = 8, 1 пиксель занимает 1 байт;
Когда biBitCount = 24, 1 пиксель занимает 3 байта: R, G, B;
Windows оговаривает, что количество байтов, занимаемых строкой сканирования, должно быть кратно 4 (то есть в единицах длины), и если этого недостаточно, оно заполняется 0.
Три, пример формата файла BMP анализа
Откройте файл grey8.bmp с помощью notepad ++, выберите плагин -> HEX-Editor -> Просмотреть в HEX, если нет, вы можете выбрать управление плагином для установки, окончательный интерфейс выглядит следующим образом:
![[ , , (img-MYsNmSvS-1573204554260)(img/image-20191102154654330.jpg)]](https://russianblogs.com/images/788/676f26793611815540799fc2ba9483fc.jpg)
Это необходимо для отображения информации об изображении в шестнадцатеричной форме, шестнадцатеричное число занимает 4 бита, поэтому одна строка представляет шестнадцать байтов.
Прежде чем анализировать файл BMP, мы должны сначала понять порядок хранения данных:
![[ , , (img-NSD9dSVY-1573204554262)(img/bmp_5.jpg)]](https://russianblogs.com/images/894/e78c633026f41f181a731a71888a5fbe.jpg)
В файле BMP, если часть данных должна быть представлена несколькими байтами, порядок байтов данных следующий: «младший адрес для хранения младших данных и высокий адрес для хранения высоких данных». Например, порядок хранения данных 0x1756 в памяти:
Этот метод хранения называется прямым порядком байтов (little endian), а противоположный - big endian.
3.1 Заголовок растрового файла
Красный прямоугольник на рисунке ниже - это заголовок файла растрового изображения:

Первые два байта (0, 1) указывают тип файла растрового изображения, а именно 0x4d42 Представляет тип BMP, который совпадает с Первые два байта в DUMP обозначают один и тот же символ BM. 。
Следующие четыре байта (2, 3, 4, 5) указывают размер файла растрового изображения, а именно 0x0000c436 Представляет размер файла точечного рисунка, преобразованного в десятичное значение 50230, мы открываем свойства grey8.bmp и обнаруживаем, что его размер действительно составляет 50230 байт:

Следующие два байта (6, 7) - это зарезервированные слова файла битовой карты 1, которые должны иметь значение 0, то есть 0x0000.
Следующие два байта (8, 9) - это зарезервированное слово 2 файла битовой карты, которое должно быть 0, то есть 0x0000.
Последние четыре байта (a, b, c, d) являются начальной позицией данных растрового изображения, и его значение равно 0x00000436, которое преобразуется в десятичное число 1078. Он представляет собой количество байтов от начала файла до массива пикселей, то есть его размер: заголовок файла растрового изображения (14 байтов) + заголовок информации о растровом изображении (40 байтов) + [256 записей * 4 слова Раздел], потому что запись в таблице цветов не обязательно существует, поэтому используйте [] Приложите. В изображении grey8.bmp есть таблица цветов, поэтому начальное значение растровых данных - 1078.
3.2 Заголовок информации о растровом изображении
![[ , , (img-7pzsYKPp-1573204554264)(img/BITMAPINFOHEADER .jpg)]](https://russianblogs.com/images/553/ac1c2fc0689d8b2f0604bbe9a22be689.jpg)
Первые четыре байта (e, f в первой строке, 0, 1 во второй строке) представляют количество байтов, занятых заголовком информации о битовой карте, то есть 0x00000028, что при преобразовании в десятичное число равно 40;
Последние четыре байта (2, 3, 4, 5 во второй строке) - это ширина растрового изображения в пикселях, то есть 0x00000100, которое преобразуется в десятичное число 256, что согласуется с реальной ситуацией.
Последние четыре байта (6, 7, 8, 9 во второй строке) - это высота растрового изображения в пикселях, то есть 0x000000c0, которое преобразуется в десятичное 192, что согласуется с реальной ситуацией.
Последние два байта (a, b во второй строке) - это уровень целевого устройства, который должен быть 1, а его значение - 0x0001, что соответствует.
Последние два байта (c, d во второй строке) - это количество битов, необходимых для каждого пикселя, и их значение равно 0x0008, что соответствует фактической битовой глубине.
Последние четыре байта (e, f во второй строке, 0, 1 в третьей строке) указывают тип сжатия битовой карты, и его значение равно 0x00000000, то есть без сжатия.
Последние четыре байта (2, 3, 4, 5 в третьей строке) - это размер растрового изображения, в байтах, значение 0x0000c000, преобразованное в десятичное число 49152, по сути, для вычисления размера массива пикселей, вычислить способ:
b i S i z e I m a g e = Фигура Нравиться из ширина степень ∗ высоко степень ∗ Кусочек глубокий степень / 8 biSizeImage = ширина изображения * высота * битовая глубина / 8 b i S i z e I m a g e = Фигура Нравиться из ширина степень ∗ высоко степень ∗ Кусочек глубокий степень / 8
в изображении grey8.bmp
b i S i z e I m a g e = 256 ∗ 192 ∗ 8 / 8 = 49152 biSizeImage=256*192*8/8=49152 b i S i z e I m a g e = 2 5 6 ∗ 1 9 2 ∗ 8 / 8 = 4 9 1 5 2
Последние четыре байта (6, 7, 8, 9 в третьей строке) представляют горизонтальное разрешение растрового изображения, и его значение равно 0x00002e23.
Последние четыре байта (a, b, c, d в третьей строке) представляют разрешение битовой карты по вертикали, и его значение равно 0x00002e23.
Последние четыре байта (e, f в третьей строке, 0, 1 в четвертой строке) представляют количество цветов в таблице цветов, фактически используемых растровым изображением, и его значение - 0x00000000, обычно равное 0.
Последние четыре байта (2, 3, 4, 5 в четвертой строке) представляют количество важных цветов в процессе отображения растрового изображения, и его значение равно 0x00000000, как правило, равному 0.
3.3 Таблица цветов
Когда битовая глубина равна 24, таблица цветов отсутствует, а за заголовком информации о растровом изображении следует массив пикселей;
Когда битовая глубина не 24, есть таблица цветов, а есть 2 Битовая глубина Каждый элемент таблицы цветов занимает 4 байта.
В желтом поле, как показано на рисунке ниже, находится 256 элементов таблицы цветов с общим размером 256 * 4 байта (показана только его часть):

Поскольку каждый элемент таблицы цветов занимает 4 байта, мы делим элемент таблицы цветов на один элемент таблицы цветов, то есть черный ящик, в единицах по 4 байта.
Поскольку grey8.bmp является изображением в градациях серого, элементы его таблицы цветов основаны на правилах.
В записи таблицы цветов три компонента RGB равны, а четвертый компонент равен 0; во всей таблице цветов значение первых трех компонентов записи таблицы цветов увеличивается на 1 от 0 до 255. Фактически, rgb (0,0,0) представляет черный, rgb (255,255,255) представляет белый, rgb (x, x, x) (x не равно 0 или 255, x является целым числом от 0 до 255) представляет разные градусов серого.
Когда файл BMP представляет собой псевдоцветное изображение, его битовая глубина составляет 8 бит, но нет правила, которому следует следовать. Например, первый элемент таблицы цветов - это rgb (1,22,3,0), второй элемент таблицы цветов - это rgb (10,89,90,0) и т. Д. Это не черный, белый и серый цвета, а другие цвета. Однако они могут отображать только до 256 цветов, что намного меньше, чем 16 миллионов цветов полноцветных изображений. Поэтому такие изображения называются псевдоцветными изображениями.
3.4 Массив пикселей
После таблицы цветов (или заголовка информации о растровом изображении) идет массив пикселей. В этом примере битовая глубина равна 8, поэтому один байт представляет один пиксель. Как определить цвет этого пикселя? Диапазон одного байта составляет [0,255], теперь вы должны понять! Найдите соответствующий элемент таблицы цветов в соответствии со значением этого байта, и цвет, соответствующий этому элементу таблицы цветов, является цветом этого пикселя. Вот как это работает для BMP с таблицами цветов.
Для изображения с истинным цветом его битовая глубина равна 24, и один пиксель, естественно, соответствует трем цветовым компонентам R, G и B, поэтому нет необходимости в таблице цветов, а для изображения с истинным цветом, если есть таблица цветов, то есть более чем 16 миллионов элементов таблицы цветов, весь файл будет очень большим.
Три, эксперимент с кодом
3.1 Экспериментальная среда
- Операционная система: Windows 10
- Компилятор: Dev-cpp, Visual Studio 2017
3.2 Содержание эксперимента
Измените элементы таблицы цветов изображения в градациях серого gray8_test.bmp ниже на случайные значения и превратите исходное изображение в оттенках серого в псевдоцветное изображение.
3.3 Другая информация
Три структуры BITMAPFILEHEADER, BITMAPINFOHEADER и RGBQUAD находятся вwindows.hОпределено в
3.4 Код ключа
Поскольку код имеет подробные комментарии, он не будет здесь подробно объяснен.
- Прочтите соответствующую информацию:
- Используйте функцию случайных чисел для изменения элементов таблицы цветов
- Запишите прочитанную информацию в целевой файл
- Чтение и запись информации о пикселях, обратите внимание на четырехбайтовое выравнивание
3.5 Внимание! ! !
- Откройте файл в двоичном виде! ! ! ! ! ! !
- Обратите внимание, что количество байтов, занимаемых строкой пикселей, кратно 4. При чтении файла считайте больше 0 байтов, добавленных позже; при записи файла запишите еще 0 байтов, которые необходимо заполнить. В противном случае изображение может быть неупорядоченным.
3.6 Результаты
С помощью нашей программы генерируются следующие картинки, которые довольно красивы!
3.7 Полный код
Четыре, расширенный эксперимент
Примечания: Формула преобразования из RGB в шкалу серого: Серый = R * 0,299 + G * 0,587 + B * 0,114
Пять, справочные материалы
[2] Мультимедийные материалы по базовому курсу
[3] Введение в Википедии о «растровом изображении», «векторной диаграмме» и «формате BMP»
Читайте также: