
Двумерное распределение в excel
В статье описывается способ построения двумерного распределения в электронных таблицах с использованием инструмента «Сводная таблица»в MicrosoftExcel. Двухмерное распределение представляет собой распределение единиц совокупности по двум переменным. Построение и дальнейшее изучение такого распределения позволяет решать описательные и аналитические задачи. В рамках первых изучается структура совокупности по двум переменным, в рамках вторых - связи между переменными. В рамках настоящей статьи описан не только способ построения двумерного распределения с использованием данного инструмента, но и его дополнительные возможности: группировка данных, дополнительные вычисления, построение диаграмм.Материалы данной статьи представляют методическую и практическую ценность для преподавателей, занимающихся вопросами повышения эффективности обучения в области основ анализа данных с информационных технологий, и осуществляющие реализацию образовательного процесса в вузах и на курсах повышения квалификаций.

1. Овчинникова И.Г., Варфоломеева Т.Н., Гусева Е.Н. Учебно-методическое пособие для подготовки к вступительным экзаменам по информатике. -Магнитогорск, 2002. -С. 119
2. Овчинникова И.Г., Варфоломеева Т.Н., Корнещук Н.Г. Учебное пособие для подготовки к централизованному тестированию по информатике. -Магнитогорск, 2002. -С.205
3. Курзаева Л.В. Дистанционный курс «Основы математической обработки информации»: электронный учебно-методический комплекс // Хроники объединенного фонда электронных ресурсов Наука и образование. - 2014. -Т. 1. - № 12 (67). - С. 117
4. Курзаева Л.В. Введение в теорию систем и системный анализ: учеб. пособие/Л.В. Курзаева. -Магнитогорск: МаГУ, 2015. -211 с.
5. Курзаева Л.В. Введение в анализ данных с использованием информационных технологий: учеб. -метод. Пособие/Л.В. Курзаева, И.Г. Овчинникова. -Магнитогорск:МаГУ, 2012. -60 с.
Работа с рядами данных – один из основных навыков специалистов, занимающихся аналитической деятельностью.
Двухмерное распределение – это распределение единиц совокупности по двум переменным. Его анализ позволяет решать как описательные, так и аналитические задачи. Говоря об описательных задачах, мы имеем в виду, что мы можем охарактеризовать структуру совокупности по двум переменным. Аналитические задачи предполагают установление связи между переменными.
Схематично двухмерное распределение может быть представлено следующим образом (табл. 1).
fij – обозначения внутриклеточных частот, т.е. значение количества совместно встречающихся в совокупности i-го значения Y и j-го значения X.
ni – маргиналы (итоговые частоты) поY показывают, сколько раз в совокупности встречается i-е значениеY.
nj – маргиналы (итоговые частоты) поX, показывают, сколько раз в совокупности встречается j-е значение X.
N – объем изучаемой совокупности.
Рассмотрим этапы построения сводных таблиц на следующем примере. В ходе опроса 38 респондентов были получены данные относительно их возраста и семейного положения.
Общий вид таблицы двух признаков
Шаг 1. Выбор источника данных для сводной таблицы и вида создаваемого отчета (рис. 1).
Рис. 1. Шаг 1 Мастера сводных диаграмм MSExcel
Рис. 2. Шаг 2 Мастера сводных диаграмм MSExcel
Шаг 2. Укажите диапазон данных, подлежащих учету при построении сводной таблицы (диапазон данных задается вместе с заголовками столбцов) как на рис. 2.
Шаг 3. Укажите место, где будет размещаться сводная таблица и нажмите кнопку Готово.
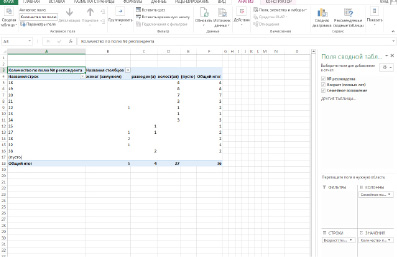
Шаг 4. В появившийся макет сводной таблицы перетащите элементы из Списка полей сводной таблицы (рис. 3).
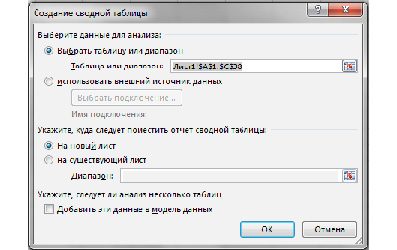
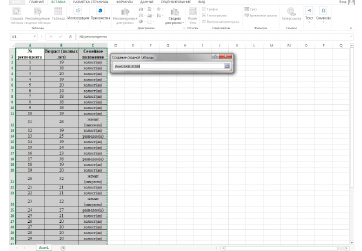
Рис. 3. Работа с макетом сводной таблицы
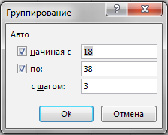
Рис. 4.Окно «Группирование»
Рис. 5. Результаты группировки

Шаг 5. Вычисление поля сводной таблицы осуществляется по умолчанию посредством суммирования. Но так как в данных у нас находятся номера респондентов, то вычисление должно осуществляться посредством счета количества респондентов (т.е. внутриклеточных частот). Для этого в панели полей сводной таблицы нужно выбрать опцию Параметры полей значений. В открывшимся окне выберите операцию Количество и нажмите кнопку ОК.
В рассматриваемом примере признак «Ваш возраст (полных лет)» можно для удобства дальнейшего анализа представить в виде интервалов. Для этого, вызвав контекстное меню нажатием правой кнопки мыши по серому полю «Ваш возраст (полных лет)» в сводной таблице, нужно выбрать опцию Группировать.
В появившемся окне необходимо установить запрашиваемые параметры – начальное и конечное значения группировки и шаг.
Тогда исходная таблица примет вид, как на рис. 5. Сводные таблицы предлагают большие возможности для дополнительных расчетов в Microsoft Office. Так, например, можно изменить параметры поля значений на процент от суммы по столбцу, или построить диаграмму.
Одномерное нормальное распределение в экселе строится тривиально.
А вот многомерное? Хотя бы от 2-х переменных.
Даже не знаю, как подступиться к проблеме.
А если проще задачу сформулировать?
Имеется n значений Ф от х и Ф от У, Х и у - независимые.
Распределения нормальные.
Как средствами экселя построить зависимость Ф от Х и У?
Заранее благодарю за любую помощь.
П. С. А от 4-х независимых переменных?
Одномерное нормальное распределение в экселе строится тривиально.
А вот многомерное? Хотя бы от 2-х переменных.
Даже не знаю, как подступиться к проблеме.
А если проще задачу сформулировать?
Имеется n значений Ф от х и Ф от У, Х и у - независимые.
Распределения нормальные.
Как средствами экселя построить зависимость Ф от Х и У?
Заранее благодарю за любую помощь.
П. С. А от 4-х независимых переменных?
Одномерное нормальное распределение в экселе строится тривиально.
А вот многомерное? Хотя бы от 2-х переменных.
Даже не знаю, как подступиться к проблеме.
А если проще задачу сформулировать?
Имеется n значений Ф от х и Ф от У, Х и у - независимые.
Распределения нормальные.
Как средствами экселя построить зависимость Ф от Х и У?
Заранее благодарю за любую помощь.
П. С. А от 4-х независимых переменных?
заранее благодарен. Автор - leon-44
Дата добавления - 30.10.2014 в 08:31
Не совсем понятно - вам нужна функция распределения или плотность?
Плотность распределения для двумерного случая прилагаю.
Не совсем понятно - вам нужна функция распределения или плотность?
Плотность распределения для двумерного случая прилагаю. buchlotnik
Плотность распределения для двумерного случая прилагаю. Автор - buchlotnik
Дата добавления - 30.10.2014 в 10:53
Не совсем понятно - вам нужна функция распределения или плотность?
Плотность распределения для двумерного случая прилагаю.
Функция нужна.
но.
Файл - гениальный.
Не совсем понятно - вам нужна функция распределения или плотность?
Плотность распределения для двумерного случая прилагаю.
Функция нужна.
но.
Файл - гениальный.
Не совсем понятно - вам нужна функция распределения или плотность?
Плотность распределения для двумерного случая прилагаю.
Функция нужна.
но.
Файл - гениальный.
Сэнкс. Автор - leon-44
Дата добавления - 30.10.2014 в 11:45
Огромное спасибо.
А логнормальное двумерное можете? А то сам попытался - у меня бяка получилась. Ваша формула:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*(($A2-$I$2)^2/$K$2^2+(B2-$J$2)^2/$L$2^2-2*$M$2*($A2-$I$2)*(B2-$J$2)/($K$2*$L$2)))
Моя попытка превратить в логнормальное двумерное:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*((LN($A2)-LN($I$2)))^2/$K$2^2+(LN(B2)-LN($J$2))^2/$L$2^2-2*$M$2*(LN($A2)-LN($I$2))*(LN(B2)-LN($J$2))/($K$2*$L$2))
Сорри, если по незнанию нарушил правила, прикрепив картинку.
Высветилось напоминание - файлы других форматов можно как приложения к файлу-примеру.
Конечно, это иллюстрация, но иллюстрация является приложение, ИМХО.
[moder]Прочитайте правила форума! Создайте новую тему с исправлением всех нарушений![/moder]
Огромное спасибо.
А логнормальное двумерное можете? А то сам попытался - у меня бяка получилась. Ваша формула:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*(($A2-$I$2)^2/$K$2^2+(B2-$J$2)^2/$L$2^2-2*$M$2*($A2-$I$2)*(B2-$J$2)/($K$2*$L$2)))
Моя попытка превратить в логнормальное двумерное:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*((LN($A2)-LN($I$2)))^2/$K$2^2+(LN(B2)-LN($J$2))^2/$L$2^2-2*$M$2*(LN($A2)-LN($I$2))*(LN(B2)-LN($J$2))/($K$2*$L$2))
Сорри, если по незнанию нарушил правила, прикрепив картинку.
Высветилось напоминание - файлы других форматов можно как приложения к файлу-примеру.
Конечно, это иллюстрация, но иллюстрация является приложение, ИМХО.
[moder]Прочитайте правила форума! Создайте новую тему с исправлением всех нарушений![/moder] leon-44
Огромное спасибо.
А логнормальное двумерное можете? А то сам попытался - у меня бяка получилась. Ваша формула:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*(($A2-$I$2)^2/$K$2^2+(B2-$J$2)^2/$L$2^2-2*$M$2*($A2-$I$2)*(B2-$J$2)/($K$2*$L$2)))
Моя попытка превратить в логнормальное двумерное:
=1/(2*ПИ()*$K$2*$L$2*КОРЕНЬ(1-$M$2^2))*EXP(-1/(2*(1-$M$2^2))*((LN($A2)-LN($I$2)))^2/$K$2^2+(LN(B2)-LN($J$2))^2/$L$2^2-2*$M$2*(LN($A2)-LN($I$2))*(LN(B2)-LN($J$2))/($K$2*$L$2))
Сорри, если по незнанию нарушил правила, прикрепив картинку.
Высветилось напоминание - файлы других форматов можно как приложения к файлу-примеру.
Конечно, это иллюстрация, но иллюстрация является приложение, ИМХО.
[moder]Прочитайте правила форума! Создайте новую тему с исправлением всех нарушений![/moder] Автор - leon-44
Дата добавления - 23.05.2015 в 09:53
Приветствую всех!
Огромное спасибо buchlotnik'у за помощь в этой теме.
Попытался самостоятельно формулу в экселе модернизировать для логнормального двумерного распределения - получилась ерунда.
Плиз, помогите чайнику. Если возможно - то и другие виды двумерных распределений средствами экселя (биномиальное, Пуассона. )
Где в формуле я начудил?
Исходная формула для нормального распределения отличная, на всем интервале кэф корреляции между наблюдаемыми значениями и расчетными более 0,88. Но вид распределения - скорее, логнормальный - старт от (0;0). Вот исходная формула для нормального распределения:
Приветствую всех!
Огромное спасибо buchlotnik'у за помощь в этой теме.
Попытался самостоятельно формулу в экселе модернизировать для логнормального двумерного распределения - получилась ерунда.
Плиз, помогите чайнику. Если возможно - то и другие виды двумерных распределений средствами экселя (биномиальное, Пуассона. )
Где в формуле я начудил?
Исходная формула для нормального распределения отличная, на всем интервале кэф корреляции между наблюдаемыми значениями и расчетными более 0,88. Но вид распределения - скорее, логнормальный - старт от (0;0). Вот исходная формула для нормального распределения:
Плиз, помогите чайнику. Если возможно - то и другие виды двумерных распределений средствами экселя (биномиальное, Пуассона. )
Где в формуле я начудил?
Исходная формула для нормального распределения отличная, на всем интервале кэф корреляции между наблюдаемыми значениями и расчетными более 0,88. Но вид распределения - скорее, логнормальный - старт от (0;0). Вот исходная формула для нормального распределения:
Есть идея. Поскольку на всем диапазоне значений Х,У кэф корреляции ~0.01, считать, что корреляции нет, и просто перемножить значения вероятностей и плотностей вероятностей от Х и от У.
Есть идея. Поскольку на всем диапазоне значений Х,У кэф корреляции ~0.01, считать, что корреляции нет, и просто перемножить значения вероятностей и плотностей вероятностей от Х и от У. leon-44
Гистограмма - это инструмент, позволяющий визуально оценить величину и характер разброса данных в выборке. С помощью диаграммы MS EXCEL создадим двумерную гистограмму для сравнения 2-х наборов данных.
О построении одномерной гистограммы (frequency histogram) подробно изложено в статье Гистограмма распределения в MS EXCEL .

Часто для сравнения двух наборов данных используют двумерную гистограмму (англ. Bivariate Histogram или BiHistogram). Это бывает полезно, например, при проверке гипотез о разнице средних значений 2-х распределений ( z-тест и t-тест ).

В MS EXCEL имеется диаграмма типа Гистограмма с группировкой , которая обычно используется для построения Гистограмм выборок . Подробнее о построении диаграмм можно прочитать в статье Основные типы диаграммы и Основы построения диаграмм в MS EXCEL .
Для генерации значений выборок будем использовать формулу (см. файл примера ): =НОРМ.ОБР(СЛЧИС();K$6;КОРЕНЬ(K$7))
Таким образом, сгенерируем 2 выборки , имеющих нормальное распределение . Подробнее о генерации случайных чисел, имеющих нормальное распределение , см. статью Нормальное распределение. Непрерывные распределения в MS EXCEL .
Как и в одномерной гистограмме , для вычисления частот (высоты столбиков гистограммы ) будем использовать функцию ЧАСТОТА() , которую нужно вводить как формулу массива .

Некоторые карманы гистограммы не содержат значения. Поэтому, соответствующие подписи данных будут равны 0, которые для красоты нужно убрать с диаграммы . Это можно сделать изменив Формат подписей данных .

Тем же способом можно избавиться от отрицательных значений нижней «перевернутой» гистограммы . Подробнее см. статью про пользовательский формат числовых данных .
Гистограмма распределения - это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции ЧАСТОТА() и диаграммы.
Гистограмма (frequency histogram) – это столбиковая диаграмма MS EXCEL , в каждый столбик представляет собой интервал значений (корзину, карман, class interval, bin, cell), а его высота пропорциональна количеству значений в ней (частоте наблюдений).
Гистограмма поможет визуально оценить распределение набора данных, если:
- в наборе данных как минимум 50 значений;
- ширина интервалов одинакова.
Построим гистограмму для набора данных, в котором содержатся значения непрерывной случайной величины . Набор данных (50 значений), а также рассмотренные примеры, можно взять на листе Гистограмма AT в файле примера. Данные содержатся в диапазоне А8:А57 .
Примечание : Для удобства написания формул для диапазона А8:А57 создан Именованный диапазон Исходные_данные.
Построение гистограммы с помощью надстройки Пакет анализа

Вызвав диалоговое окно надстройки Пакет анализа , выберите пункт Гистограмма и нажмите ОК.
В появившемся окне необходимо как минимум указать: входной интервал и левую верхнюю ячейку выходного интервала . После нажатия кнопки ОК будут:
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Перед тем как анализировать полученный результат - отсортируйте исходный массив данных .
Как видно из рисунка, первый интервал включает только одно минимальное значение 113 (точнее, включены все значения меньшие или равные минимальному). Если бы в массиве было 2 или более значения 113, то в первый интервал попало бы соответствующее количество чисел (2 или более).
Второй интервал (отмечен на картинке серым) включает значения больше 113 и меньше или равные 216,428571428571. Можно проверить, что таких значений 11. Предпоследний интервал, от 630,142857142857 (не включая) до 733,571428571429 (включая) содержит 0 значений, т.к. в этом диапазоне значений нет. Последний интервал (со странным названием Еще ) содержит значения больше 733,571428571429 (не включая). Таких значений всего одно - максимальное значение в массиве (837).
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так: =(МАКС( Исходные_данные )-МИН( Исходные_данные ))/7 где Исходные_данные – именованный диапазон , содержащий наши данные.
Почему 7? Дело в том, что количество интервалов гистограммы (карманов) зависит от количества данных и для его определения часто используется формула √n, где n – это количество данных в выборке. В нашем случае √n=√50=7,07 (всего 7 полноценных карманов, т.к. первый карман включает только значения равные минимальному).
Примечание : Похоже, что инструмент Гистограмма для подсчета общего количества интервалов (с учетом первого) использует формулу =ЦЕЛОЕ(КОРЕНЬ(СЧЕТ( Исходные_данные )))+1
Попробуйте, например, сравнить количество интервалов для диапазонов длиной 35 и 36 значений – оно будет отличаться на 1, а у 36 и 48 – будет одинаковым, т.к. функция ЦЕЛОЕ() округляет до ближайшего меньшего целого (ЦЕЛОЕ(КОРЕНЬ(35))=5 , а ЦЕЛОЕ(КОРЕНЬ(36))=6) .

Если установить галочку напротив поля Парето (отсортированная гистограмма) , то к таблице с частотами будет добавлена таблица с отсортированными по убыванию частотами.

Если установить галочку напротив поля Интегральный процент , то к таблице с частотами будет добавлен столбец с нарастающим итогом в % от общего количества значений в массиве.

Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка ).

Для нашего набора данных установим размер кармана равным 100 и первый карман возьмем равным 150.

В результате получим практически такую же по форме гистограмму , что и раньше, но с более красивыми границами интервалов.
Как видно из рисунков выше, надстройка Пакет анализа не осуществляет никакого дополнительного форматирования диаграммы . Соответственно, вид такой гистограммы оставляет желать лучшего (столбцы диаграммы обычно располагают вплотную для непрерывных величин, кроме того подписи интервалов не информативны). О том, как придать диаграмме более презентабельный вид, покажем в следующем разделе при построении гистограммы с помощью функции ЧАСТОТА() без использовании надстройки Пакет анализа .
Построение гистограммы распределения без использования надстройки Пакет анализа
Порядок действий при построении гистограммы в этом случае следующий:
- определить количество интервалов у гистограммы;
- определить ширину интервала (с учетом округления);
- определить границу первого интервала;
- сформировать таблицу интервалов и рассчитать количество значений, попадающих в каждый интервал (частоту);
- построить гистограмму.
СОВЕТ : Часто рекомендуют, чтобы границы интервала были на один порядок точнее самих данных и оканчивались на 5. Например, если данные в массиве определены с точностью до десятых: 1,2; 2,3; 5,0; 6,1; 2,1, …, то границы интервалов должны быть округлены до сотых: 1,25-1,35; 1,35-1,45; … Для небольших наборов данных вид гистограммы сильно зависит количества интервалов и их ширины. Это приводит к тому, что сам метод гистограмм, как инструмент описательной статистики , может быть применен только для наборов данных состоящих, как минимум, из 50, а лучше из 100 значений.
В наших расчетах для определения количества интервалов мы будем пользоваться формулой =ЦЕЛОЕ(КОРЕНЬ(n))+1 .
Примечание : Кроме использованного выше правила (число карманов = √n), используется ряд других эмпирических правил, например, правило Стёрджеса (Sturges): число карманов =1+log2(n). Это обусловлено тем, что например, для n=5000, количество интервалов по формуле √n будет равно 70, а правило Стёрджеса рекомендует более приемлемое количество - 13.
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() - Подсчет ЧИСЛОвых значений в MS EXCEL .
В MS EXCEL имеется диаграмма типа Гистограмма с группировкой , которая обычно используется для построения Гистограмм распределения .

В итоге можно добиться вот такого результата.
Примечание : О построении и настройке макета диаграмм см. статью Основы построения диаграмм в MS EXCEL .

Одной из разновидностей гистограмм является график накопленной частоты (cumulative frequency plot).
На этом графике каждый столбец представляет собой число значений исходного массива, меньших или равных правой границе соответствующего интервала. Это очень удобно, т.к., например, из графика сразу видно, что 90% значений (45 из 50) меньше чем 495.
СОВЕТ : О построении двумерной гистограммы см. статью Двумерная гистограмма в MS EXCEL .
Примечание : Альтернативой графику накопленной частоты может служить Кривая процентилей , которая рассмотрена в статье про Процентили .
Примечание : Когда количество значений в выборке недостаточно для построения полноценной гистограммы может быть полезна Блочная диаграмма (иногда она называется Диаграмма размаха или Ящик с усами ).
Читайте также: