
Что такое тбд в 1с
Если верить популярности запросов, то самая встречающаяся проблема, с которой сталкиваются специалисты при таком обмене, — это возвращение изменений в исходный документ.
1. Обмен данными в 1С с технической точки зрения
Для начала стоит сразу объяснить, как обмен работает с технической точки зрения.
Исходя из такой схемы работы, на тестовом контуре чаще всего ошибка заключается в том, что при копировании базы Документооборота (а чаще всего это просто копии) базы блокируют все регламентные задания в 1С, связанные с внешним миром. Чтобы не нарушать работу основной базы, и для того, чтобы обмен работал сам, необходимо разрешить использование регламентных заданий в 1С. Как только вы откроете обработку «фоновые и регламентные задания в 1С» вы увидите соответствующую кнопку. Внимание: проверьте есть ли в этой конфигурации настроенные синхронизации и выключены ли такие регламентные задания как оповещения, если синхронизации есть их стоит удалить, а регламентные задания выключить.
2. Отладка выражений на встроенном языке 1С
Порой при бесшовной интеграции документооборота приходится писать код для подстановки тех или иных значений. Приходится писать их в режиме предприятия: ни подсказок, ни автоподстановки, ни отладки там нет.
Но не все так плохо - можно подсмотреть в отладке 1С на его исполнение. Для этого в своей второй конфигурации (не ДО) необходимо найти Общий модуль «ОбщегоНазначения» а в нем функцию «ВыполнитьВБезопасномРежиме». Именно в этой функции происходит выполнение нашего кода. Если поставить, например, на возврате точку остановы, мы сможем посмотреть, какие параметры пришли и какой код выполняется. Если продвинемся на пару шагов вперед, то увидим, какой результат вышел в итоге. К тому же не запрещается на время отладки в 1С размещать что-то «подсказывающее»: где конкретно процесс оборвался, в случае сложных логических цепочек можно разместить, например, функцию ЗаписьЖурналаРегистрации.
Реквизит, который я указал не заполняются – это очень распространенная ошибка. Но в 90% случаев решается она очень просто: у реквизита, который не заполняется, необходимо проставить галку «Заполнять из данных заполнения». Если это не помогает, то тут универсального ответа нет, нужно проверять тип заполнения. Для теста можно проверить заполнение из другого реквизита и т.д.
Как передать ссылку через встроенный язык 1С?
Вот тут начинаются сложности. При передаче результата достаточно его просто вписать, но если результат ссылочный, то результатов три:
Параметры.Результат - необходимо заполнить. Можно заполнить наименованием по ссылке. Если будет пустой, то все другие результаты не сохранятся.
Параметры.РезультатID - сама ссылка на объект. Достать ее будет сложной задачей.
Параметры.РезультатТип – тип ссылки, передается строкой из XDTO – DM.
Как передаются ссылки в целом?
Всегда перед настройкой бесшовной интеграцией документооборота делайте простую синхронизацию, чтобы все элементы справочников были максимально одинаковыми, за исключением конечно нестандартных. Но бесшовная интеграция довольно универсальная в этом плане, и если необходимо что-то синхронизировать, то достаточно сделать так, чтобы наименование было одно и то же, тогда элементы не будут дублироваться, а подставляться будут те, что есть в системе.
Как включить свой реквизит в бесшовную интеграцию
1. На стороне ИС
1. В модуле менеджера справочника Правила интеграции прописать новый реквизит в метод ПолучитьРеквизитыОбъектаДО
2. При необходимости работать с данным реквизитом интерактивно на стороне ИС нужно вынести его на форму и обеспечить его заполнение в методе Справочники.ПравилаИнтеграцииС1СДокументооборотом. СоответствиеСвойствXDTOиРеквизитовФормыОбъектаДО или в процедуре ПрочитатьОбъектВФорму в форме документа БИД.
2. На стороне ДО
1. Добавить реквизит в XDTO пакет DM в DMDocument или в DM<. >Document
2. При необходимости добавить реквизит в метод ОбработкаЗапросовXDTO. СоответствиеСвойствXDTOРеквизитамПоиска
3. В ОМ ОбработкаЗапросовXDTOДокументы прописать заполнение и получение данного реквизита из объекта XDTO в методы ПолучитьДанные<. >Документа, ЗаполнитьДанные<. >Документа
Специалист компании ООО «Кодерлайн»
Вас могут заинтересовать следующие статьи:
94 [PROP_CODE] => TAGS2 [TITLE] => Вас могут заинтересовать следующие семинары: ) --> 95 [PROP_CODE] => TAGS [TITLE] => Вас могут заинтересовать следующие вебинары: ) -->
Вас могут заинтересовать следующие вебинары:
Механизм разделения данных позволяет хранить данные нескольких независимых организаций в одной информационной базе.
Это становится возможным благодаря тому, что общие реквизиты объектов конфигурации можно использовать не только как «одинаковый реквизит, который есть у всех объектов», но и как идентификатор того, что данные относятся к какой-то одной из нескольких независимых областей. Это можно объяснить на следующем примере.
Допустим в конфигурации существует общий реквизит «Организация». Это значит (упрощённо), что у каждого справочника, документа или другого объекта конфигурации также будет существовать реквизит «Организация».
При этом любой из пользователей информационной базы имеет доступ ко всем данным, которые хранятся в этой базе, независимо от того, какая организация указана, например, в том или ином документе.

Теперь укажем, что общий реквизит «Организация» будет являться разделителем.

Тогда (упрощённо) в информационной базе будет создано несколько независимых областей данных, в каждой из которых будут храниться данные только для одной конкретной организации:

Теперь, заходя в программу, пользователь будет получать доступ не ко всей информации, которая есть в информационной базе, а только к данным «своей» области, в данном случае к документам, справочникам и др. своей организации.

Возможен и другой вариант использования этого механизма, когда в информационной базе существует несколько независимых областей данных и наряду с этим существуют данные, которые доступны всем пользователям программы. Например, они содержат справочник банков, который одинаков для всех организаций.

В этом случае пользователь имеет доступ к «своей» области данных и к области неразделённых данных, которая является общей для всех пользователей.
В статье рассмотрены терминология системы контроля версий Git (СКВ), которая используется для механизма групповой разработки конфигурации среды разработки нового поколения 1C:Enterprise Development Tools (EDT). Логически данный материал продолжает тему затронутую в предыдущей статье и показывает какие преимущества дает новая среда разработки при использовании указанной СКВ.
Применимость
Весь материал актуален.

С выходом EDT под Eclipse появилась одна очень интересная и достаточно важная функция, которая, по сути, заменяет стандартное хранилище конфигураций.
Наверняка Вам знакомы основные проблемы данного решения от 1С. В частности, не слишком удобно:
- Работать по сети (сложности возникают с выделением отдельной машины и поднятием веб-сервера);
- Просматривать историю, ввиду очень длительного процесса реализации данного действия;
- Не иметь возможность регистрировать ошибки, вследствие чего программисты просто не фиксируют причины вносимых ими изменений;
- И многое другое.
С другой стороны – в современном IT мире начали активно применять облачные хранилища для совместной разработки. Суть их в следующем:
- Создается некий проект, например, обработка «выгрузка в xml»;
- Все исходные коды этого проекта сохраняются в облаке;
- Эти исходники Вы копируете на свой компьютер и работаете с ними;
- После того как Вы внесли какой-либо новый функционал, эти изменения Вы переносите обратно в облако.
Действуя по данной схеме, Вы получаете ряд преимуществ:
- Храните всех данных в облаке. В случае неудачного сохранения или сбоя диска – будут потеряны только последние изменения.
- Предоставляете доступ для изменения обработки разным людям.
- Меняете данные в одном модуле одновременно с коллегами. Например, Вам потребовалось изменить в обработке модуль формы документа и добавить новые процедуры, коллеге это тоже понадобилось сделать. В случае конфигуратора Вы бы захватили эту форму, закрыв к ней доступ всем. В нашем случае – это легко реализуется, а при слиянии данных в основные исходники просто добавятся две процедуры.
- Редактируете исходники непосредственно в браузере. Так, если у вашего коллеги возникла проблема и он не может ее решить, он просто присылает Вам ссылку на этот модуль, и Вы в браузере исправляете код. Коллега затем импортирует изменения.
- И много всего другого.
Все это следствие того, что хранилище данных в 1С – это централизованная система хранения SVN, в которой есть одно место, где помещены все данные. Модель работы с ней сводилась к блокировке, изменению и разблокировке содержимого. В этом ее отличие от такой распределенной системы хранения данных, как Git.
Для понимания ознакомьтесь с основными терминами:
Репозиторий – это хранилище файлов в системе контроля версий. Вместе с исходными файлами хранятся и все изменения, происходившие с этими файлами. Т.е. это аналог папки в 1С, где находится хранилище конфигураций. Отличие в том, что эти данные хранятся в облаке.
Коммит (commit) – это регистрация изменений в локальном хранилище. По аналогии с 1С – внесение данных в хранилище конфигураций. Но это не значит, что все изменения попадут сразу в центральную конфигурацию, если только Вы не делали изменения непосредственно в ней. Таким образом Вы фиксируете свои изменения, и, если они понадобятся Вам в другом месте, Вы сможете получить их только из локального репозитория своего компьютера или, например, с флешки, если предварительно сохранили все там (чего лучше не делать). В противном случае ваши изменения останутся только локально у Вас на компьютере.
Пуш (push) – эта команда переносит ваши данные из локального хранилища в облачное. Это аналог «Поместить в хранилище». Пока этого не будет сделано, все изменения будут сохранены только локально у Вас на компьютере.
Отслеживаемые файлы и неотслеживаемые файлы – иногда надо подключить какие-то модули для теста, и они не понадобятся в конечном решении. И вот тут происходит разделение всех данных на те, которые система отслеживает и в случае их изменений скорректирует их в облаке, и те, которые не отслеживаются, например, тестовый модуль или дополнительная форма – любой файл, который Вы создали или добавили локально. То же самое касается файлов, которые Вы заменили в самом проекте, например, методом копирования.
Ветка (branch) – это одна из копий вышестоящей ветки, с которой Вы работаете. В свою очередь все начинается с одной главной ветки, которую можно назвать «стволом». У Вас есть основное хранилище, где содержится, скажем так, релиз. Однако все изменения в релиз Вы вносить не будете, поэтому создадите ветку или несколько веток, с которыми будете работать в режиме теста. Туда Вы фиксируете изменения, и только потом эти изменения администратор переносит в master-ветку.
После переноса все участники других веток могут импортировать эти изменения себе. Таких веток и под-веток может быть несколько. Это удобно, если у Вас к примеру 20 участников. Участники разбиваются на подгруппы по 5 человек. Главный администратор переносит изменения из остальных под-веток в основную. При этом у каждой команды есть свои под-ветки третьего уровня, с которыми они работают, и локальный администратор вносит изменения в эти ветки. Таким образом, команды не мешают друг другу, а администратор эффективно отслеживает изменения в каждой подгруппе.
Схематично это выглядит так:

В данном случае объединением веток:
1-2 – занимается главный админ
2-3 – локальный админ (тимлид, руководитель команды)
3-4 – каждый программист отдельно.
Обратите внимание: на каждую новую фичу, исправление бага и т.п., если для этого надо написать более двух строк кода, создают новую ветку, вносят изменения, переносят и ветку удаляют. В мире 1С с текущими объемами конфигураций это является неподъемной задачей. С другой стороны, если ведется разработка мобильного приложения, то эти методы вполне можно использовать.
Кроме этого, если Вы опытный программист, можете пропустить третий уровень. Тогда вносить изменения Вы будете сразу на второй уровень. Обычно об этом команды договариваются заранее.
Форк (fork) – это процесс создания новой ветки путем копирования другой ветки. После создания первой ветки master, ее начинают «форкать» на другие ветки, в свою очередь те ветки «форкают» дальше. Суть форка заключается в том, что Вы копируете одну ветку на основании другой, сохраняя связь с предыдущей в виде логического древа. Если же Вы просто скопируете проект и подключите, тогда останется неясным: откуда он взялся.
Пул (pull) – команда, которая позволяет получить данные из ветки в облаке. Когда Вы «форкнули» какую-то ветку, Вы должны ее скачать к себе в локальное хранилище. Если кто-то сделал в ней изменения, то Вы таким же путем переносите эти изменения к себе.
Мерже (merge) – это слияние веток. Когда разработчик исправил баг в своей ветке, он может ее замержить (объеденить) с другой веткой, перенеся таким образом туда изменения.
Конфликты (коллизии) – это нам всем известные коллизии из 1С. Только мы с ними не могли встречаться в хранилище, но очень часто встречались при обменах, когда некую информацию изменили в обоих узлах и теперь надо решить – кто же прав. Так и тут, git постарается сам по себе все объединить, и, если вдруг возникнет ситуация, когда он не справится, он Вам на это укажет. В этом случае надо будет перенести изменения вручную, отметив, что данные перенесены.
Метки (теги) – это аналог бэкапа конфигурации. По сути, метка – это полный снимок всего проекта на конкретный момент времени, который никто никогда не мержит. Т.е. он является эталоном, который изменить не получится. Обычно метки – это предыдущие релизы или же значительные изменения в других ветвях развития.
Теперь попробуем представить некоторые варианты развития и жизни всей разработки. На эту тему есть статья (и ее перевод), картинка оттуда:
На графике изображен весь жизненный цикл разработки программы. Все начинается с ветки master. Она создается автоматически, а все остальные ветки наследуются от нее. Следующая ветка, которая создается, – develop. В ней идет разработка основного функционала программы. Именно от этой ветки и начинается отсчет версий всех будущих релизов программы.
Develop делится на несколько веток, которые нацелены на расширение функционала. Когда команда решает, что нового функционала достаточно, делается слияние его в ветку разработок (develop) и образуется новая ветка, на основании которой создают ночной билд, т.е. тестовый релиз.
С этого момента ветка с ночным релизом и ветка девелоп начинают жить параллельно, до тех пор, пока на основании ночного билда не получится выпустить релиз. И из ветки ночных билдов мы переносим в девелоп только исправленные баги.
И дальше выпускаем релиз. Потом все по циклу.
Это пример того, как люди ведут разработку с помощью новых (для нас) механизмов. Безусловно, в каждой команде существуют свои варианты и правила ведения разработок. Мы показали одну из возможных направлений работы с версиями.
Итак, пора опробовать реализацию на практике. К примеру, организуйте работу двух людей, имеющих доступ к одной главной ветке и одной под-ветке. Изначально изменения будут вноситься в эти под-ветки, а потом переноситься в центральную. Ваша задача – написать обработку, которая будет иметь три простые формы. Одна из форм станет главной и будет находится в мастер-ветке.
Каждый из программистов должен создать свою кнопку, при нажатии на которую будет открываться другая форма. Вот эти формы каждый программист создает отдельно.
В заключение напомним, что еще до выхода EDT, начиная с момента возможности выгрузки конфигурации в файлы, мы уже могли бы использовать системы контроля версий на основе git вместе с конфигуратором. Официально рекомендованный способ, как это можно сделать, описан здесь.
Также следует отметить, что если Вы по какой-либо причине работаете на старой версии платформы, то лучше использовать платформу версии 8.3.8+, т.к. начиная с нее существенно увеличена скорость загрузки/выгрузки в файлы XML.
Возникла необходимость организовать учет по двум организациям в одной ИБ. Ситуация не уникальная, но так сложилось, что наша сильно не типовая 250 гигобайтная УППшка работала довольно медленно, поэтому вместо RLS решили попробовать разделение данных. Что это такое, описано, например,
Простые смертные работают только со своей ООО, а главбух иногда смотрит данные по двум юрлицам. В режиме доступа к обеим ООО можно только читать данные, поэтому главбух должен иметь возможность интерактивно переключаться между режимами "все читать"/"писать только по одной организации" и выбирать ООО (т.е. устанавливать значение общего реквизита) для проведения, например, расчета себестоимости.
2. Реализация
Платформа 8.2.19.90, без режима совместимости. СУБД - MSSQL Server 2008 R2 Standart.
Создали общий реквизит ОрганизацияРазделитель типа "число", согласились с предложением создать параметры сеанса, заполнили состав реквизита (включили несколько справочников, все документы, регистры накопления, бухгалтерии и расчета). Разделение данных - "Независимо и совместно". Значение параметра сеанса устанавливается из стандартных настроек пользователя в процедуре УстановкаПараметровСеанса в модуле сеанса:
В интерфейсе главбуха сделали формочку с возможностью переключения между организациями и включения/выключения режима разделения:

При отключенном разделении, когда ПараметрыСеанса.ОрганизацияРазделительИспользование = Ложь, платформа отказывается записывать документы, вываливаясь с ошибками типа "ОшибкаSDBL: ожидается выражение (pos=12)", поэтому давать пользователю записывать документы в таком варианте нельзя. Для надежности, создали подписки на событие "Перед записью" для объектов, входящих в состав общего реквизита:
План действий у нас был такой: готовим конфигурацию-приемник ИБ №1, проставляем значения общего реквизита = 1, загружаем данные из ИБ №2, после загрузки для всех объектов с пустым (равным 0) значением разделителя устанавливаем ОрганизацияРазделитель = 2.
Конфигурацию подготовили, возник вопрос, как установить значение общего реквизита для документов и их движений в закрытых периодах, причем быстро и без риска того, что полетят цифры в балансе? Через объектную модель 1С записывать разделитель отдельно от объекта невозможно, поэтому пришлось нарушить лицензионное соглашение выкручиваться и писать запрос для MS SQL. Поскольку в составе общего реквизита много объектов, а таблиц в скуле по этим объектам еще больше, написали обработку, генерирующую запрос для SQL (для каждого объекта метаданных, входящего в состав разделителя, писали "update " + Имя_БД + ".dbo._" + ИмяТаблицы + " set _" + ПолеОбщийРеквизит + " = 1";)
Значение проставили, перенесли часть данных из ИБ №2, начали тестировать.
Результат разочаровал. Во-первых, проблемы с регистром бухгалтерии. При включенном разделении не видно аналитику:


Хорошо, проставляем значение разделителя через MS SQL, аналитику видим. Теперь не работают отчеты. Оказывается, проблемы с запросами к виртуальным таблицам регистра бухгалтерии "Обороты" и "ОборотыДтКт":

(Fld27033 - это как раз общий реквизит в таблице регистра бухгалтерии)
Разделитель установлен во всех таблицах, это видно на уровне СУБД, в чем может быть ошибка, не понятно. Разворачиваем типовую пустую УПП, делаем описанные выше изменения в конфигурации, вводим пару документов (в этом варианте платформа сама проставляет значение разделителя во всех таблицах регистра бухгалтерии), но ошибки воспроизводятся. Плохо, но исключаем регистры бухгалтерии из состава общего реквизита, продолжаем тестирование.
Далее, выясняется что перестал работать механизм вытеснения у регистров расчета. Планы видов расчета мы не разделяли, пробуем искать проблему в таблицах регистра расчетов и в перерасчетах. Проверяем, проставляем значение основного реквизита, делаем ТиИ - безрезультатно.
Попутно, диагностируем проблему при записи в независимые регистры сведений из формы списка. При этом данные записываются, их можно увидеть после перезапуска. Проблема воспроизводится и на тестовой базе:

Регистры сведений "починить" путем манипуляций с SQL не получилось (значение разделителя во всех таблицах установлено), поэтому просто исключили их из состава общего реквизита. После нескольких дней экспериментов, неудачными оказываются и попытки восстановить работоспособность вытеснения.
На этот момент принимаем решение выключить разделение данных и использовать-таки RLS. При установке разделения в "не использовать" натыкаемся на ошибки "Microsoft OLE DB Provider forSQL Server: CREATE UNIQUE INDEX terminated because a duplicate keywas found for index. ". Т.е., вернуться в состояние до разделения так запросто не получается. Проблема с индексами таблиц перерасчетов, настроек хранения итогов и других. Дело в том, что в таблицах хранятся идентичные строки, отличающиеся только значением общего реквизита. При удалении общего реквизита появляются неуникальные записи. Придется удалить ненужные записи напрямую в MS SQL, примерно так (для таблицы перерасчетов):
И только после чистки нескольких десятков таблиц удается выключить разделение данных. После выключения разделения никаких проблем нет.
Теплилась надежда, что на 8.3 проблемы решены. Не поленились, проверили на 8.3.4.482 (с отключенным режимом совместимости). Смотрели на практически типовой УПП-шке, с изменениями в конфигурации только по общему реквизиту. На этой тестовой базе разделение включили до ввода информации, т.е. платформа должна была корректно записывать значение разделителя во все таблицы, самостоятельно напрямую в MS SQL ничего не писали.
Проблема с запросами к виртуальным таблицам "Обороты" и "ОборотыДтКт" воспроизводится.
Проблема с вытеснением воспроизводится.
Проблема с записью в независимые регистры сведений воспроизводится.
+ проблема с выключением разделения - одним нажатием кнопки от него избавится не получится!
Таким образом, заменить RLS новым механизмом у нас не получилось. Задумывался этот механизм, по всей видимости, для облачных сервисов, и в варианте использования разделяемых данных "независимо", может быть, разделение заработает, но нам нужна общая НСИ. Остается ждать, когда 1С исправит ошибки , а еще лучше, реализует типовой механизм разделения по организациям в типовых конфигурациях.
Механизм РИБ — механизм распределенных информационных баз - это когда у вас есть главная база и подчиненная(ые). Главная база может быть только одна, подчиненных может быть много. Каждая подчиненная база может иметь свои подчиненные базы, для которых она будет главной.
Вот посмотрим на картинку из первой ссылки по запросу в Яндексе:
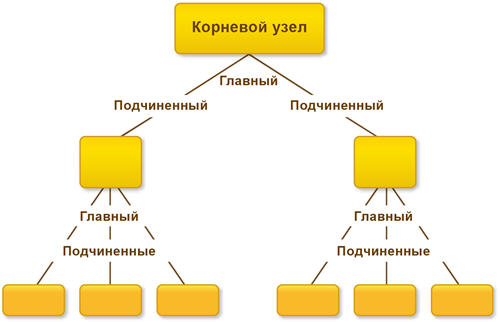
РИБ используется для обмена данными. Причем не только теми данными, с которыми работает пользователь, но и данными изменения конфигурации. То есть РИБ позволяет передавать изменения конфигурации. Но изменить конфигурацию можно только в главной базе!
Визуализируем:
У нас большая компания и много филиалов. Есть доработанная УНФ, которую мы гордо называем УБФ(Управление Большой Фирмой). Но мы решили, что хватит терпеть то, что все филиалы имеют доступ к документам всех филиалов и каждому филиалу решили сделать отдельную базу, которую синхронизировать с нашей основной базой для передачи данных. Что ж, можно. Сделали.
И внезапно мы решили изменить картинку, которая появляется при входе в базу, захотели поместить туда логотип нашей фирмы, а почему бы и нет?
Как запилить картинку во все базы всех филиалов? Ну при текущем варианте, что у всех филиалов отдельная база, только руками. Руками специалистов, которые умеют заходить в конфигуратор и знают что нужно там нажать.
А вот если бы мы сделали подчиненные базы для филиалов, то есть использовали РИБ, то и данными бы обменивались, как при обычной синхронизации, и картинка бы сама добавилась во все "базы-дочки". Однако, в конфигуратор зайти бы все-таки пришлось, но только чтобы нажать кнопочку "Обновить конфигурацию базы данных", вот картинка:

Как создать подчиненную базу, на пальцах:
я буду использовать Управление торговлей, редакция 11 (11.4.13.275), но способ, в целом, одинаковый во всех типовых конфигурациях.
1) Сначала проделаем шаги, как при настройке обычной синхронизации:

2) . поставим галочку, нажмем.


4) тут ознакомимся с описанием. Я выберу обычную настройку, но если бы мы следовали примеру выше, то нужно было бы выбрать "с фильтром" и там одним кликом выбрать нужный филиал.


6) Указываем префикс - он будет подставляться к номерам документов, чтобы можно было отличить документы дочки и основной базы.


7) в общем случае, тут ничего не надо нажимать, кроме "Записать и закрыть".

8) А вот теперь создаем нашу новую подчиненную базу:

9) указываем место, куда ее покладем.




10) Зайдем в нашу новую подчиненную базу и закончим настройки синхронизации(синхронизация уже создалась, так как использовали РИБ, но нужно указать каталог для обмена выбрав "Настройки подключения")

(обратите внимание на верхний левый угол окна программы, там название базы, он отличается от предыдущих, так как это "дочка")
Кстати, в новой базе все пользователи будут выключены, пароли сброшены, нужно включить руками:

В общем-то ВСЕ.
Подчиненная база создана!
Теперь, когда наши программисты что-нибудь улучшат, эти улучшения прилетят в подчиненные базы сами.
Вот что-то изменили в основной базе:

нам нужно перенести изменения в базы-дочки.
Для этого запускаем главную базу в режиме 1С:Предприятие, то есть в пользовательском интерфейсе, заходим в настройки синхронизации, жмем выделенную кнопку:

После того, как синхронизация закончится, заходим в базу дочку и так же жмем "Синхронизировать", база загрузит данные и напишет:


После нажатия на Далее база закроется и начнет устанавливать обновления.

Когда обновы установятся, база начнет запускаться и сообщит нам следующее:

Это означает, что не обновлена конфигурация базы данных. Та самая маленькая кнопка в конфигураторе и это именно та причина, почему придется ОДИН раз зайти в конфигуратор. Что ж, зайдем в конфигуратор базы-дочки и нажмем эту кнопку, заодно вообще посмотрим что-да-как там, мы ж там еще не были.
Откроем конфигурацию и вот что увидим
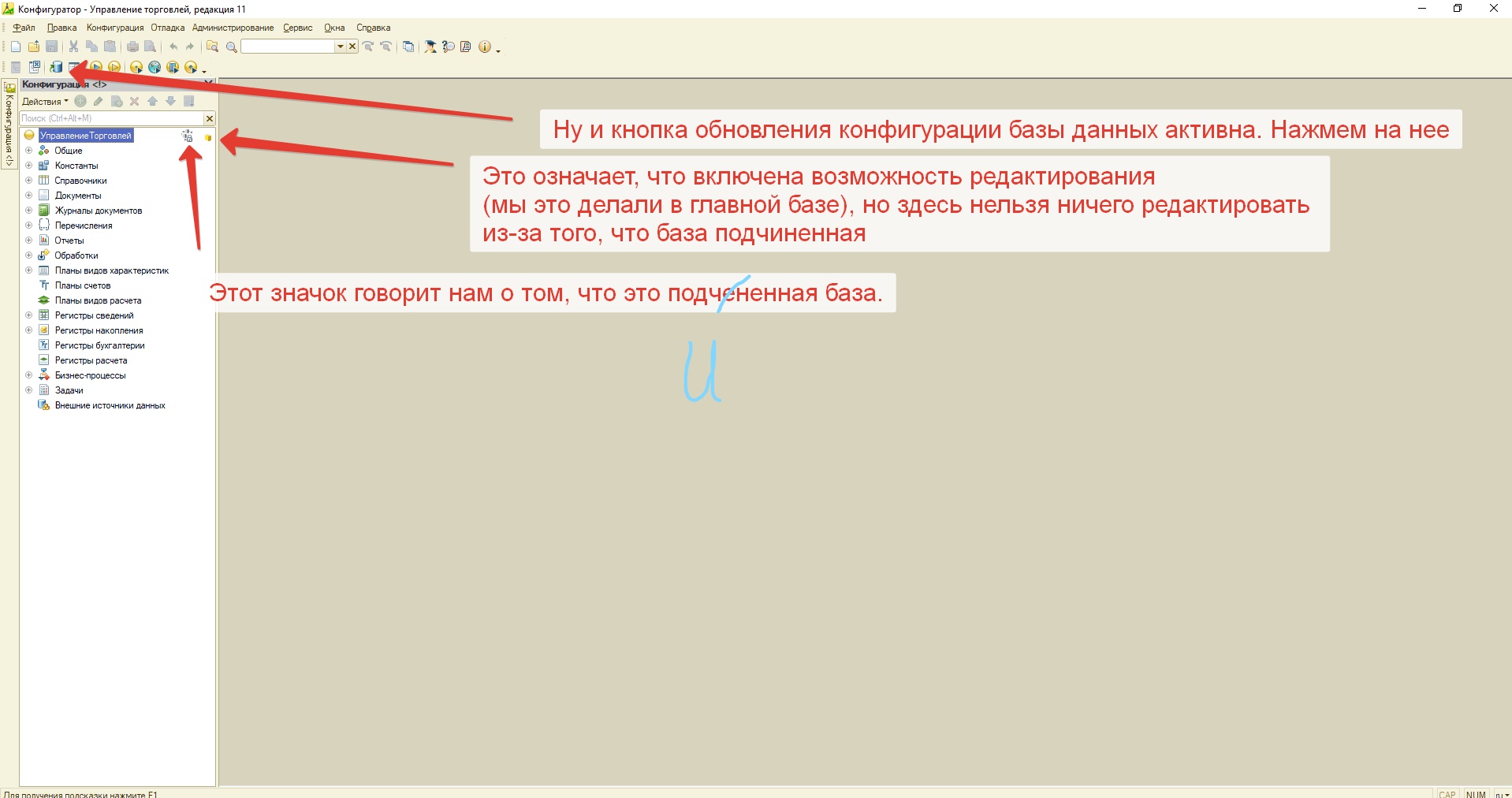
Нажмем на "Обновить конфигурацию базы данных".
Увидим список изменений, которые прилетели с обновлениями:

И вот эти обновления появились в подчиненной базе.

Теперь необходимо запустить базу в пользовательском режиме, чтобы выполнились обработчики обновления.
Несколько правил:
1) Все узлы, кроме одного, должны иметь по одному главному узлу и один узел не будет иметь главного узла - это корневой узел.
2) Конфигурация может быть изменена только в узле, не имеющем главного узла (то есть в корневом).
3) Изменения конфигурации будут передаваться от главного к подчиненным узлам.
4) Разрешение коллизий так же будет производиться исходя из отношений "главный - подчиненный" - если изменения сделаны одновременно и в главном и в подчиненном узлах, то приняты будут изменения главного узла.
5) Сделать подчиненный узел в распределенной базе можно разными способами, но создание начального образа является рекомендуемым.
А теперь то, ради чего все писалось.
Как подчиненную базу сделать обычной(нормальной, отдельной, как хотите).
Я опишу только тот способ, которым пользуюсь. Это моя шпаргалка. Но он не единственный.
1) Заходим в свойства ярлыка запуска окна 1С:Предприятие:

2) В поле "Объект" дописываем:
DESIGNER /F"Путь до базы" /N"Имя Пользователя в базе" /P"Пароль пользователя" /ResetMasterNode
В итоге у меня получится:
"C:\Program Files\1cv8\common\1cestart.exe" DESIGNER /F"C:\Users\79119\Desktop\РИБ" /N"" /P"" /ResetMasterNode
Читайте также: