
Что означает альфа бета в прогнозе эксель
Функция ПРЕДСКАЗ в Excel позволяет с некоторой степенью точности предсказать будущие значения на основе существующих числовых значений, и возвращает соответствующие величины. Например, некоторый объект характеризуется свойством, значение которого изменяется с течением времени. Такие изменения могут быть зафиксированы опытным путем, в результате чего будет составлена таблица известных значений x и соответствующих им значений y, где x – единица измерения времени, а y – количественная характеристика свойства. С помощью функции ПРЕДСКАЗ можно предположить последующие значения y для новых значений x.
Примеры использования функции ПРЕДСКАЗ в Excel
Функция ПРЕДСКАЗ использует метод линейной регрессии, а ее уравнение имеет вид y=ax+b, где:
- Коэффициент a рассчитывается как Yср.-bXср. (Yср. и Xср. – среднее арифметическое чисел из выборок известных значений y и x соответственно).
- Коэффициент b определяется по формуле:
Пример 1. В таблице приведены данные о ценах на бензин за 23 дня текущего месяца. Согласно прогнозам специалистов, средняя стоимость 1 л бензина в текущем месяце не превысит 41,5 рубля. Спрогнозировать стоимость бензина на оставшиеся дни месяца, сравнить рассчитанное среднее значение с предсказанным специалистами.
Вид исходной таблицы данных:

Чтобы определить предполагаемую стоимость бензина на оставшиеся дни используем следующую функцию (как формулу массива):

- A26:A33 – диапазон ячеек с номерами дней месяца, для которых данные о стоимости бензина еще не определены;
- B3:B25 – диапазон ячеек, содержащих данные о стоимости бензина за последние 23 дня;
- A3:A25 – диапазон ячеек с номерами дней, для которых уже известна стоимость бензина.

Рассчитаем среднюю стоимость 1 л бензина на основании имеющихся и расчетных данных с помощью функции:

Можно сделать вывод о том, что если тенденция изменения цен на бензин сохранится, предсказания специалистов относительно средней стоимости сбудутся.
Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
Пример 2. Компания недавно представила новый продукт. С момента вывода на рынок ежедневно ведется учет количества клиентов, купивших этот продукт. Предположить, каким будет спрос на протяжении 5 последующих дней.
Вид исходной таблицы данных:

Как видно, в первые дни спрос был небольшим, затем он рос достаточно большими темпами, а на протяжении последних трех дней изменялся незначительно. Это свидетельствует о том, что основным фактором роста продаж на данный момент является не расширение базы клиентов, а развитие продаж с постоянными клиентами. В таких случаях рекомендуют использовать не линейную регрессию, а логарифмический тренд, чтобы результаты прогнозов были более точными.
Рассчитаем значения логарифмического тренда с помощью функции ПРЕДСКАЗ следующим способом:
Как видно, в качестве первого аргумента представлен массив натуральных логарифмов последующих номеров дней. Таким образом получаем функцию логарифмического тренда, которая записывается как y=aln(x)+b.

Для сравнения, произведем расчет с использованием функции линейного тренда:
И для визуального сравнительного анализа построим простой график.

Как видно, функцию линейной регрессии следует использовать в тех случаях, когда наблюдается постоянный рост какой-либо величины. В данном случае функция логарифмического тренда позволяет получить более правдоподобные данные (более наглядно при большем количестве данных).
Прогнозирование будущих значений в Excel по условию
Пример 3. В таблице Excel указаны значения независимой и зависимой переменных. Некоторые значения зависимой переменной указаны в виде отрицательных чисел. Спрогнозировать несколько последующих значений зависимой переменной, исключив из расчетов отрицательные числа.
Вид таблицы данных:

Для расчета будущих значений Y без учета отрицательных значений (-5, -20 и -35) используем формулу:
Разберем такой инвестиционный показатель как – коэффициент бета, рассчитаем его на реальном пример с помощью Excel и рассмотрим различные современные модификации.
Инфографика: Коэффициент бета
Оценка стоимости бизнеса | Финансовый анализ по МСФО | Финансовый анализ по РСБУ |
Расчет NPV, IRR в Excel | Оценка акций и облигаций |

Коэффициент бета. Определение
Коэффициент бета (англ. Beta, β, beta coefficient) – определяет меру риска акции (актива) по отношению к рынку и показывает чувствительность изменения доходности акции по отношению к изменению доходности рынка. Коэффициент бета может быть рассчитан не только для отдельной акции, но также и для инвестиционного портфеля. Коэффициент используется как мера систематического риска, и применяется в модели У.Шарпа – оценки капитальных активов CAPM (Capital Assets Price Model). В первые, коэффициент бета рассмотрел Г. Марковиц для оценки систематического риска акций, который получил называние индекс недиверсифицируемого риска. Коэффициент бета позволяет сравнивать между собой акции различных компаний по степени их риска.
Формула расчета коэффициента бета
где:
β – коэффициент бета, мера систематического риска (рыночного риска);
ri – доходность i-й акации (инвестиционного портфеля);
rm – рыночная доходность;
σ 2 m – дисперсия рыночной доходности.
Анализ уровня риска по значению коэффициента бета (β)
Коэффициент бета показывает рыночный риск акции и отражает чувствительность изменения акции по отношению к изменению доходности рынка. В таблице ниже показана оценка уровня риска по коэффициенту бета. Коэффициент бета может иметь как положительный, так и отрицательный знак, который показывает положительную или отрицательную корреляцию между акцией и рынком. Положительный знак отражает, что доходность акций и рынка изменяются в одном направлении, отрицательный – разнонаправленное движение.
Значение показателя
Уровень риска акции
Направление изменения доходности акции
Данные для построения коэффициента бета информационными компаниями
Коэффициент бета используется многими информационно-инвестиционными компаниями для оценки систематического риска: Bloomberg, Barra, Value Line и др . Для построения коэффициента бета используются месячные/недельные данные за несколько лет. В таблице показаны основные параметры оценки показателя различными информационными компаниями.
Информационные компании
Можно заметить, что Bloomberg проводит краткосрочную оценку показателя, тогда как Barra и Value Line используют месячные данные доходностей акций и рынка за последние пять лет. Долгосрочная оценка может сильно быть искажена вследствие влияния на акции компании различных кризисов и негативных факторов.
Коэффициент бета в модели оценки капитальных активов – CAPM
Формула расчета доходности акций по модели капитальных активов CAPM (Capital Assets Price Model, модель У.Шарпа) имеет следующий вид:
где:
r – будущая ожидаемая доходность акций компании;
rf – доходность по безрисковому активу;
rm – доходность рынка;
β – коэффициент бета (мера рыночного риска), отражает чувствительность изменения стоимости акций компании в зависимости от изменения доходности рынка (индекса);
Модель CAPM была создана У.Шарпом (1964) и Дж. Линтером (1965) и позволяет спрогнозировать будущее значение доходности акции (актива) на основании линейной регрессии. Модель отражает линейную взаимосвязь планируемой доходности с уровнем рыночного риска, выраженного коэффициентом бета.
Доходность по безрисковому активу, на практике, берется как доходность по государственным ценным бумагам ГКО, ОФЗ. Доходность по ним в России составляет около 12%. Доходность можно посмотреть на сайте ЦБ в разделе «Ставки рынка ГКО-ОФЗ».
Для расчета рыночной доходности используют доходность индекса или фьючерса на индекс (индекс ММВБ, РТС – для России, S&P500 – США).
Пример расчета коэффициента бета в Excel
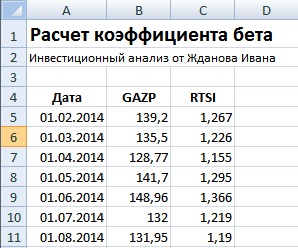
Далее необходимо рассчитать доходности по акции и индексу, для этого воспользуемся формулами:

Для расчета коэффициента бета необходимо рассчитать коэффициент линейной регрессии между доходностью акций ОАО «Газпром» и индекса РТС. Рассмотрим два варианта расчета коэффициента бета средствами Excel.
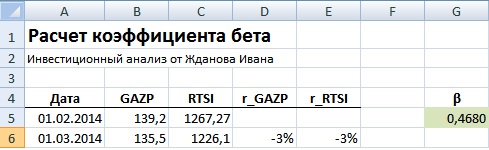
Вариант №1. Расчет через формулу Excel
Расчет через формулы Excel выглядит следующим образом:
Вариант №2. Расчет через надстройку «Анализ данных»
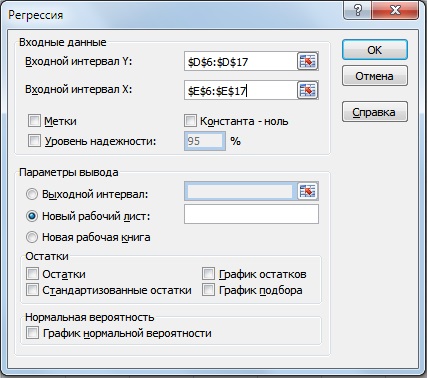
Далее мы получим отчет по регрессии на отдельном листе. В ячейке В18 показано значение коэффициента линейной регрессии, который равен коэффициенту бета = 0,46. Также проанализируем другие параметры модели, так показатель R-квадрат (коэффициент детерминированности) показывает силу взаимосвязи между доходностью акции ОАО «Газпром» и индекса РТС. Коэффициент детерминированности равен 0,4, что является довольно мало для точного прогнозирования будущей доходности по модели CAPM. Множественный R – коэффициент корреляции (0,6), который показывает наличие зависимости между акцией и рынком.
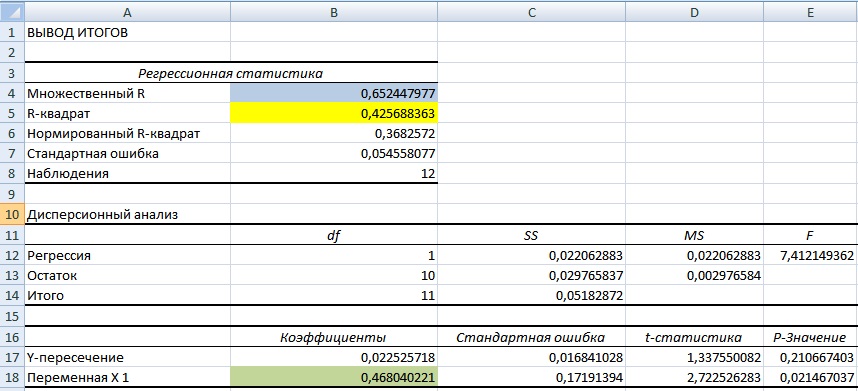
Значение 0,46 коэффициента бета для акции свидетельствует о умеренном риске и в тоже время сонаправленность изменения доходностей.
Недостатки использования коэффициента бета в модели CAPM
Рассмотрим ряд недостатков присущих данному коэффициенту:
- Сложность использования коэффициента бета для оценки низколиквидных акций. Данная ситуация характерна для развивающихся рынков капитала, в частности: России, Индии, Бразилии и т.д.
- Не возможность оценки малых компаний, не имеющих эмиссий обыкновенных акций. Большинство отечественных компаний не проходили процедуры IPO.
- Неустойчивость прогноза коэффициента бета. Использование линейной регрессии для оценки рыночного риска по ретроспективным данным не позволяет получать точные прогнозы риска. Как правило, трудно прогнозировать коэффициент бета более 1 года.
- Не возможность учета несистематических рисков компании: рыночной капитализации, исторической доходности, отраслевой принадлежности, критериев P/E и т.д., которые оказывает влияние на величину ожидаемой доходности.
Модификация коэффициента бета
Так как коэффициент, предложенный У. Шарпов не имел должной устойчивости и не мог использоваться для прогнозирования будущей доходности в модели CAPM, различными учеными были предложены модификации и корректировки данного показателя (англ. adjusted beta, modified beta).Рассмотрим скорректированные коэффициенты бета:
Модификация коэффициента бета от М.Блюма (1971)
Маршал Блюм показал, что со временем коэффициенты бета компаний стремятся к 1. Формула расчета скорректированного показателя следующая:
Использование данных весовых значений позволяет более точно спрогнозировать будущий систематический риск. Так данную модификацию используют многие информационные агентства, такие как: Bloomberg, Value Line и Merrill Lynch.
Модификация коэффициента бета от Бава-Линдсберга (1977)
В своей корректировке Линдсберг предложил рассчитывать односторонний коэффициент бета. Главный постулат заключался в том, что изменение доходности выше определенного уровня большинство инвесторов не рассматривают как риск, а риском считается только то, что ниже уровня. За минимальный уровень риска в данной модели был доходность безрискового актива.

где:
ri – доходность акции; rm – доходность рынка; rf – доходность безрискового актива.
Модификация коэффициента бета от Шоулза-Виллимса
β-1, β, β1 – коэффициенты беты для предыдущего (-1) текущего и следующего (1) периода;
ρm – коэффициент автокорреляции рыночной доходности.
Модификация коэффициента бета от Харлоу-Рао (1989)
Формула отражает одностороннюю бету, с предположением, что инвесторы рассматривают риск только как отклонение от среднерыночной доходности вниз. В отличие от модели Бава-Линдсберга за минимальный уровень риска брался уровень среднерыночной доходности.

где: μi – средняя доходность акции; μm – средняя доходность рынка;
Помимо коэффициента бета на практике используют другие показатели риска-доходности инвестиционного портфеля, ПИФа, более подробно узнать про современные показатели оценки инвестиций вы можете в моей статье: «Оценка эффективности инвестиций, инвестиционного портфеля, акций на примере в Excel«. О практике оценке риска инвестиции читайте в статье: «Методы оценки риска VaR (Value at Risk). Рыночный риск. Пример расчета в Excel «.
Коэффициент бета для акций США
Существуют сервисы позволяющие оценить коэффициент бета для множества компаний и выделить наиболее интересные. Будем применять сервис Finviz. Чтобы найти акции менее чувствительные чем колебания фондового рынка необходимо установить коэффициент бета меньше 1.
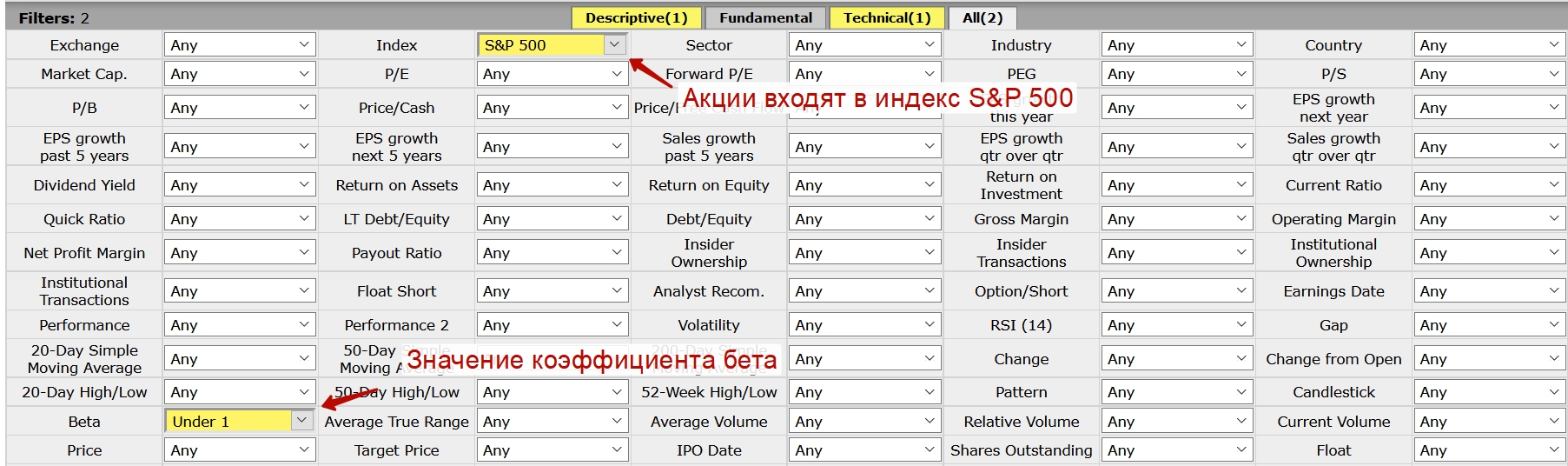
Фильтрация акций США по бета меньше «1» позволяет найти акции для консервативного инвестора, изменчивость которых ниже изменения индекса S&P 500
Где посмотреть коэффициент бета для российских акций
Проанализировать акции на бета можно по ссылке.
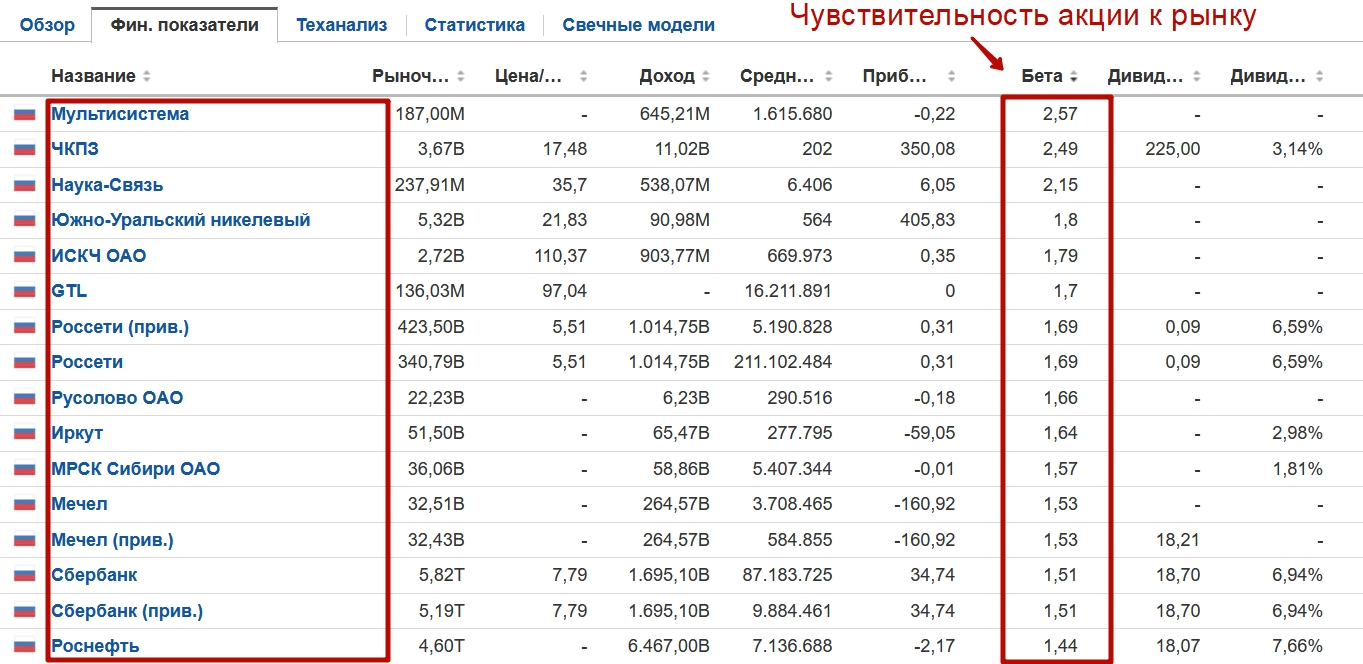
Сортировка отечественных акций по коэффициента бета. Чем выше значение тем более изменчива акция по отношению к индексу ММВБ
Высокие значения коэффициента бета при растущем рынке будут обеспечивать дополнительную прибыль, при коррекциях такие акции как правило имеют больше убытков.
Резюме
Коэффициент бета является одним из классических мер рыночного риска для оценки доходности акций, инвестиционных портфелей и ПИФов. Несмотря на сложность использования данного инструмента для оценки отечественных низколиквидных акций и неустойчивость его изменения во времени, коэффициент бета является ключевым показателем оценки инвестиционных рисков. Рассмотренные модификации коэффициента позволяют скорректировать и дать более оценку систематическому риску. С вами был Иван Жданов, спасибо за внимание.

Прогнозирование – это очень важный элемент практически любой сферы деятельности, начиная от экономики и заканчивая инженерией. Существует большое количество программного обеспечения, специализирующегося именно на этом направлении. К сожалению, далеко не все пользователи знают, что обычный табличный процессор Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. Давайте выясним, что это за инструменты, и как сделать прогноз на практике.
Процедура прогнозирования
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Способ 1: линия тренда
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.
- Строим график зависимости на основе табличных данных, состоящих из аргументов и значений функции. Для этого выделяем табличную область, а затем, находясь во вкладке «Вставка», кликаем по значку нужного вида диаграммы, который находится в блоке «Диаграммы». Затем выбираем подходящий для конкретной ситуации тип. Лучше всего выбрать точечную диаграмму. Можно выбрать и другой вид, но тогда, чтобы данные отображались корректно, придется выполнить редактирование, в частности убрать линию аргумента и выбрать другую шкалу горизонтальной оси.


- Линейная;
- Логарифмическая;
- Экспоненциальная;
- Степенная;
- Полиномиальная;
- Линейная фильтрация.
Давайте для начала выберем линейную аппроксимацию.



Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ. Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.
«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.
-
Выделяем незаполненную ячейку на листе, куда планируется выводить результат обработки. Жмем на кнопку «Вставить функцию».


В поле «Известные значения y» указываем координаты столбца «Прибыль предприятия». Это можно сделать, установив курсор в поле, а затем, зажав левую кнопку мыши и выделив соответствующий столбец на листе.
Аналогичным образом в поле «Известные значения x» вносим адрес столбца «Год» с данными за прошедший период.



Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ. Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
=ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ, а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа», но он не является обязательным и используется только при наличии постоянных факторов.

Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.
-
Производим обозначение ячейки для вывода результата и запускаем Мастер функций обычным способом. В категории «Статистические» находим и выделяем наименование «ТЕНДЕНЦИЯ». Жмем на кнопку «OK».



Способ 4: оператор РОСТ
Ещё одной функцией, с помощью которой можно производить прогнозирование в Экселе, является оператор РОСТ. Он тоже относится к статистической группе инструментов, но, в отличие от предыдущих, при расчете применяет не метод линейной зависимости, а экспоненциальной. Синтаксис этого инструмента выглядит таким образом:
=РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы у данной функции в точности повторяют аргументы оператора ТЕНДЕНЦИЯ, так что второй раз на их описании останавливаться не будем, а сразу перейдем к применению этого инструмента на практике.
-
Выделяем ячейку вывода результата и уже привычным путем вызываем Мастер функций. В списке статистических операторов ищем пункт «РОСТ», выделяем его и щелкаем по кнопке «OK».



Способ 5: оператор ЛИНЕЙН
Оператор ЛИНЕЙН при вычислении использует метод линейного приближения. Его не стоит путать с методом линейной зависимости, используемым инструментом ТЕНДЕНЦИЯ. Его синтаксис имеет такой вид:
=ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Последние два аргумента являются необязательными. С первыми же двумя мы знакомы по предыдущим способам. Но вы, наверное, заметили, что в этой функции отсутствует аргумент, указывающий на новые значения. Дело в том, что данный инструмент определяет только изменение величины выручки за единицу периода, который в нашем случае равен одному году, а вот общий итог нам предстоит подсчитать отдельно, прибавив к последнему фактическому значению прибыли результат вычисления оператора ЛИНЕЙН, умноженный на количество лет.
-
Производим выделение ячейки, в которой будет производиться вычисление и запускаем Мастер функций. Выделяем наименование «ЛИНЕЙН» в категории «Статистические» и жмем на кнопку «OK».




Как видим, прогнозируемая величина прибыли, рассчитанная методом линейного приближения, в 2019 году составит 4614,9 тыс. рублей.
Способ 6: оператор ЛГРФПРИБЛ
Последний инструмент, который мы рассмотрим, будет ЛГРФПРИБЛ. Этот оператор производит расчеты на основе метода экспоненциального приближения. Его синтаксис имеет следующую структуру:
= ЛГРФПРИБЛ (Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Как видим, все аргументы полностью повторяют соответствующие элементы предыдущей функции. Алгоритм расчета прогноза немного изменится. Функция рассчитает экспоненциальный тренд, который покажет, во сколько раз поменяется сумма выручки за один период, то есть, за год. Нам нужно будет найти разницу в прибыли между последним фактическим периодом и первым плановым, умножить её на число плановых периодов (3) и прибавить к результату сумму последнего фактического периода.
-
В списке операторов Мастера функций выделяем наименование «ЛГРФПРИБЛ». Делаем щелчок по кнопке «OK».




Прогнозируемая сумма прибыли в 2019 году, которая была рассчитана методом экспоненциального приближения, составит 4639,2 тыс. рублей, что опять не сильно отличается от результатов, полученных при вычислении предыдущими способами.
Мы выяснили, какими способами можно произвести прогнозирование в программе Эксель. Графическим путем это можно сделать через применение линии тренда, а аналитическим – используя целый ряд встроенных статистических функций. В результате обработки идентичных данных этими операторами может получиться разный итог. Но это не удивительно, так как все они используют разные методы расчета. Если колебание небольшое, то все эти варианты, применимые к конкретному случаю, можно считать относительно достоверными.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Excel, как универсальный табличный редактор, давно и неплохо справляется с большинством задач прогнозирования (см. список литературы в конце заметки). Однако, не всегда вычисления в Excel являются простыми и понятными. И вот в версии 2016 года разработчики Microsoft добавили семейство функций ПРЕДСКАЗ (FORECAST), которые позволяют в несколько кликов решать большой круг задач прогнозирования на основе экспоненциального сглаживания.
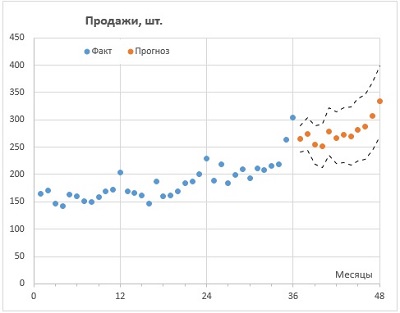
Рис. 1. Прогнозирование продаж в Excel с помощью семейства функций ПРЕДСКАЗ
Об экспоненциальном сглаживании
Экспоненциальное сглаживание также известно, как метод ETS: ошибки (Errors), тренд (Trend), сезонный фактор (Seasonal). Для составления прогноза используются все исторические данные, но коэффициенты, определяющие вклад, убывают в прошлое по экспоненте (отсюда и название). Это позволяет, с одной стороны, чутко реагировать на свежие данных, с другой стороны, сохранять информацию об историческом поведении всего временного ряда. Если данным присущ тренд, он вычисляется в каждой точке данных (а не на основе регрессии всего временного ряда). Наконец, с помощью автокорреляции в данных выявляется сезонность.
Преимущество модели в том, что она не использует никаких предположений относительно характера тренда (или его отсутствия) и периодичности сезонных колебаний (или их отсутствия). Все коэффициенты в модели подбираются на основе минимизации суммы квадратов ошибок, то есть, разности между прогнозом на исторических данных и самих данных. Если вас интересует, как это происходит, рекомендую работу Формана (см. список литературы).
Собственно, оптимизируются три коэффициента:
α – разброс относительно среднего
Разработчики Microsoft не предоставили пользователям возможность влиять на выбор коэффициентов, за исключением периода сезонности (об этом ниже).
Обзор функций семейства ПРЕДСКАЗ
В Excel представлено 5 функций:
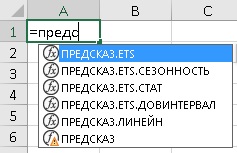
Рис. 2. Семейство функций ПРЕДСКАЗ в Excel
ПРЕДСКАЗ.ETS рассчитывает будущее значение на основе существующих (ретроспективных) данных методом экспоненциального сглаживания. Т.е., дает прогноз одним числом.
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ возвращает доверительный интервал для прогнозной величины. Доверительный интервал следует отложить по обе стороны от среднего значения. Вместе с ПРЕДСКАЗ.ETS позволяет построить «коридор» прогноза.
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ возвращает длину повторяющегося фрагмента, обнаруженного в заданном временном ряду. Например, 12, если исторические данные представляют из себя продажи за месяц.
ПРЕДСКАЗ.ETS.СТАТ возвращает восемь статистических значений, являющихся результатом прогнозирования временного ряда. Вряд ли вы будете использовать эту функцию. Она нужна для более тонкого исследования параметров прогнозной модели.
ПРЕДСКАЗ.ЛИНЕЙН вычисляет будущее значение с помощью линейной регрессии исторических данных. До версии 2016 в Excel вместо семейства функций была единственная функция ПРЕДСКАЗ, которая работала также, как и ПРЕДСКАЗ.ЛИНЕЙН. Функция ПРЕДСКАЗ оставлена для обратной совместимости, но скоро перестанет поддерживаться. Далее в заметке ПРЕДСКАЗ.ЛИНЕЙН не рассматривается, так как не относится к функциям, использующим алгоритм экспоненциального сглаживания.
ПРЕДСКАЗ.ETS
В качестве примера рассмотрим месячный пассажиропоток в аэропорту (пример от MS). Исторические данные были собраны за период с января 2009 по декабрь 2912 г.
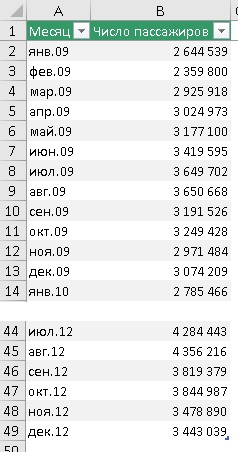
Рис. 3. Исторические данные
Продолжим временную шкалу еще на год, и создадим столбец для прогноза. Обычно прогноз располагают в отдельном столбце для того, чтобы при построении графика представить исторические и прогнозные значения разными линиями.
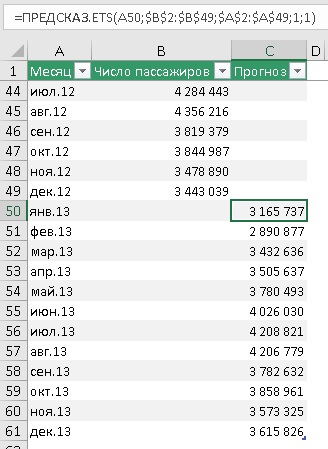
Рис. 4. Прогнозные значения на основе функции ПРЕДСКАЗ.ETS
Подробнее о формуле в ячейке С50:
Первый аргумент – целевая_дата = А50 – янв.13, т.е., в ячейке С50 ищется прогноз пассажиропотока для января 2013 г. Ссылка относительная, что позволит при протягивании функции вниз по столбцу ссылаться на новое значение: в С51 – на А51, в С52 – на А52 и т.д.
Второй аргумент – значения = $B$2:$B$49. Здесь расположены исторические данные пассажиропотока. Ссылка абсолютная, чтобы при протягивании формулы ячейки, на которые ссылаются не изменились.
Третий аргумент – временная_шкала = $A$2:$A$49. Здесь расположены даты временной шкалы или номера периодов. Важно чтобы они отстояли друг от друга на фиксированный интервал. Если интервал не будет фиксированным, Excel всё еще будет исходить из гипотезы, что интервал фиксированный, а некоторые данные пропущены. Как обрабатываются такие ситуации описано ниже. Сортировать массив по значениям временной шкалы не обязательно, так как ПРЕДСКАЗ.ETS сама отсортирует данные прежде, чем выполнить расчеты.
Четвертый аргумент – [сезонность] = 1. Это необязательный аргумент. Значение по умолчанию равно 1. Для него Excel автоматически определяет сезонность и использует положительные целые числа в качестве длины сезонного шаблона. Значение 0 предписывает не использовать фактор сезонности, в результате чего прогноз будет линейным. Если для этого параметра задано положительное целое число, алгоритм использует его в качестве длины шаблона сезонности. Например, вы знаете, что сезонность равна 4 (квартальная периодичность), но предполагаете, что она слабая, и автоматический алгоритм Excel может ее не выявить, и будет считать, что сезонности нет. Для начала я рекомендовал бы использовать значение по умолчанию.
Пятый аргумент – [заполнение_данных] = 1. Это необязательный аргумент. Хотя временная шкала требует постоянный шаг между точками данных, FORECAST.ETS поддерживает до 30% отсутствующих данных и автоматически настраивает их. 0 указывает, что алгоритм учитывает отсутствующие точки в качестве нулей. Если задано значение 1 (вариант по умолчанию), функция определяет отсутствующие значения как среднее между соседними точками.
Шестой аргумент – [агрегирование] – в нашем примере опущен. Это необязательный аргумент. Он нужен, если даты временной шкалы или номера периодов содержат дубли. Функция ПРЕДСКАЗ.ETS выполнит агрегирование точек с одинаковой меткой времени. Параметр агрегирования — это числовое значение, определяющее способ агрегирования нескольких значений с одинаковой меткой времени. Для значения по умолчанию 0 используется метод СРЗНАЧ; также доступны варианты СУММ, СЧЁТ, СЧЁТЗ, МИН, МАКС и МЕДИАНА.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» - «Диаграмма» - «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
Читайте также: