
Что определяет формат записи данных в файл
Компьютер был создан, чтобы хранить и воспроизводить большое количество информации. Операционная система распознает информацию в двоичном коде, который обычный человек прочесть не сможет. Поэтому в качестве посредника между человеком и компьютером был создан файл — «контейнер» для разного рода информации.
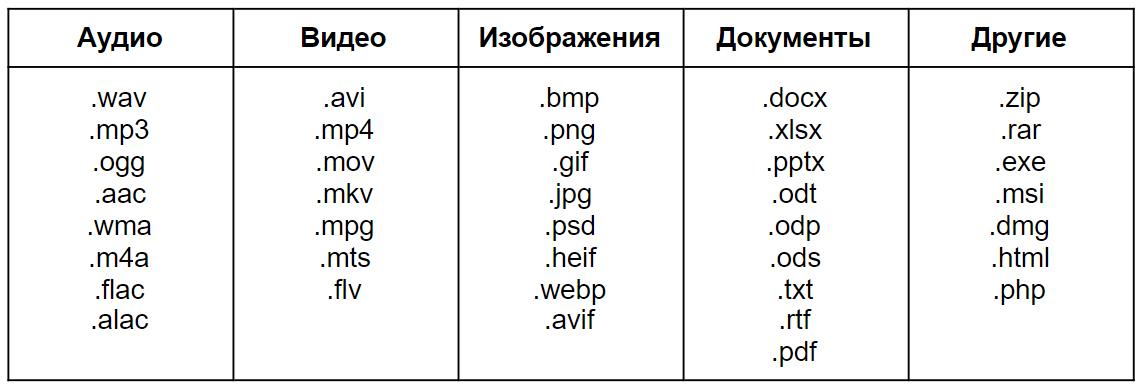
Тип файла зависит от его содержания. Чаще всего обычному пользователю достаточно файлов в формате текст, звук, видео, изображение, таблица. Но существуют и другие форматы, понятные специалистам программирования. Например, HTML файлы, системные или файлы образа диска. После того, как происходит кодирование, система распознает файлы, чтобы определить, какая программа сможет их прочитать. Формат — это более общее понятие, чем расширение или тип файла. Например, в графическом формате существует несколько типов файлов: GIF, JPEG, TIFF и много других.
Расширения файлов
Расширение файла всегда указывается в его названии после точки и состоит из трех букв. Например, работая с файлом Word, мы можем увидеть расширение doc или docx. Благодаря расширению операционная система понимает, какой программой можно воздействовать на файл — открыть, редактировать и т.п.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
Если расширение не указано в названии файла, значит это заложено в настройках операционной системы, которые можно поменять.
Как правило, расширение пользователю показывается графически — картинкой, которой обозначен файл. Если на месте иконки отображается чистый белый лист, значит файл не распознается. В этом случае система предложит выбрать программу для работы с файлом вручную из списка установленных.
Особенности пользовательских файлов
Текстовые документы
Файлы этого типа входят в группу наиболее используемых. Для работы с текстовыми документами в операционной системе Windows установлено приложение Word. Расширения для работы с текстом в этой программе — doc, docx, txt, rtf. Выбор зависит от назначения файла. Например, в файлах типа doc, docx, rtf можно работать с исходным текстом, добавлять таблицы, рисунки, схемы и т.д. Отформатированные тексты можно распечатывать на принтере. Для упрощенной записи без форматирования используется расширение txt в приложении «Блокнот».
Приложение Word не единственная программа для чтения и работы с текстами. Документы можно читать и редактировать в программах OpenOffice, LibreOffice. Они близки к Word, но отличаются интерфейсом и некоторыми возможностями.
Сканированные документы можно читать с помощью программ WinDjView (расширение djvu), Acrobat Reader, Foxit Reader (расширение pdf). Файлы в формате pdf можно редактировать в соответствующем приложении и включать в него векторные или растровые изображения.
Тексты для интернет-страниц создаются в формате HTML.
Рисунки
Расширений для файлов с графическими изображениями больше, чем для текстовых документов. Их можно разделить на две группы: растровые и векторные.
Растровые изображения
Растровые изображения более востребованы обычными пользователями из-за простоты в использовании. К ним относятся такие расширения, как BMP, GIF, JPEG, PNG, PSD (файлы для работы в программе Photo Shop), TIFF и другие. Отличаются они не только программным обеспечением, которое может с ними работать, но и некоторыми свойствами:
- BMP — не подвержены сжатию;
- GIF — позволяют создать анимацию небольшого объема;
- JPEG — наиболее подходящий формат для передачи и хранения цифровых фотографий, так как файлы этого расширения можно подвергать сжатию;
- TIFF — расширение свойственно изображениям высокого качества.
Векторные изображения
Векторная графика используется для профессиональной работы с изображениями. Векторные рисунки сохраняют свои пропорции при любом изменении. Файлы этого формата используют дизайнеры и иллюстраторы разных направлений. Расширения векторных изображений: AI ( Adobe Illustrator ), CDR ( Corel Draw ), EPS ( Encapsulated PostScript format ), SWF ( Adobe Flash) и другие. Все они созданы для обработки в специальных программах — графических редакторах.
Аудиофайлы
Аудиофайлы содержат цифровую запись звука. Форматы звуковых файлов отличаются по свойствам сжатия, цели использования, объему.
Современному пользователю знакомы аудиофайлы с расширениями aac, wma, ac3, ogg, m4a, ape, flac, mp3:
- AAC — аналогичен mp3, но в отличие от него при преобразовании меньше теряет в качестве. Наиболее популярное приложение для работы с файлами ААС — Winamp.
- WMA — чаще можно встретить в сети Интернет, создан для проигрывателя Windows Media Audio компанией Microsoft.
- WAV — аудиоформат, более предназначенный для записи качественного несжатого звука. Непригоден для передачи и хранения, так как занимает большой объем памяти.
- FLAC — аудиофайлы в этом расширении обладают высоким качеством, могут подвергаться сильному сжатию. Прослушивание файлов требует специальных плееров на компьютере, не подходят для передачи.
- MP3 — один из наиболее распространенных форматов. Совместим со многими аудиоустройствами, но по сравнению с flac качество звучания у таких файлов низкое. Еще один минус — mp3-файлы не годятся для редактирования.
Видеофайлы
Видеофайлы могут отличаться по нескольким параметрам: разрешение, ширина потока, частота кадров, качество изображения и глубина цвета. Разные расширения видеофайлов отличаются уровнем качества по каждому из этих параметров. Среди популярных форматов на сегодняшний день файлы типа mp4, avi, mkv, wmv, flv, mpeg, swf:
- AVI — распространенное расширение для просмотра видео. Не подходит для воспроизведения объемного звука.
- MKV — имеет широкий функционал. Например, в файлах этого типа есть возможность воспроизведению меню. Требует установки специальных программ для воспроизведения на компьютере.
- MPEG — несколько форматов видеофайлов, среди которых самым востребованным и универсальным является MPEG4. Расширение имеет высокий стандарт сжатия и подходит для использования как на ПК, так и в сети.
- FLV — предназначено для воспроизведения и хранения видеороликов в интернете.
Другие распространенные форматы файлов
Для сжатия и передачи файлов используются специальные приложения-архиваторы, которые упаковывают файлы в один контейнер. После этого файл становится меньшим по объему и получает расширение архиватора. Самые распространенные расширения rar, zip.
Если пользователь устанавливает новую программу, то она будет иметь формат exe. Считывая такое расширение, система получает команду установить приложение.
Для работы с таблицами нужны файлы в формате xls, xlsx. Они входят в офисный пакет Windows.
Еще одно популярное расширение файлов — ppt, pptx. Оно позволяет создавать и редактировать презентации.
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Для удобства обращения информация в запоминающих устройствах хранится в виде файлов.
Файл – именованная область внешней памяти, выделенная для хранения массива данных. Данные, содержащиеся в файлах, имеют самый разнообразный характер: программы на алгоритмическом или машинном языке; исходные данные для работы программ или результаты выполнения программ; произвольные тексты; графические изображения и т. п.
Каталог ( папка , директория ) – именованная совокупность байтов на носителе информации, содержащая название подкаталогов и файлов, используется в файловой системе для упрощения организации файлов.
Файловой системой называется функциональная часть операционной системы, обеспечивающая выполнение операций над файлами. Примерами файловых систем являются FAT (FAT – File Allocation Table, таблица размещения файлов), NTFS, UDF (используется на компакт-дисках).
Существуют три основные версии FAT: FAT12, FAT16 и FAT32. Они отличаются разрядностью записей в дисковой структуре, т.е. количеством бит, отведённых для хранения номера кластера. FAT12 применяется в основном для дискет (до 4 кбайт), FAT16 – для дисков малого объёма, FAT32 – для FLASH-накопителей большой емкости (до 32 Гбайт).
Рассмотрим структуру файловой системы на примере FAT32.
Файловая структура FAT32
Устройства внешней памяти в системе FAT32 имеют не байтовую, а блочную адресацию. Запись информации в устройство внешней памяти осуществляется блоками или секторами.
Сектор – минимальная адресуемая единица хранения информации на внешних запоминающих устройствах. Как правило, размер сектора фиксирован и составляет 512 байт. Для увеличения адресного пространства устройств внешней памяти сектора объединяют в группы, называемые кластерами.
Кластер – объединение нескольких секторов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами. Основным свойством кластера является его размер, измеряемый в количестве секторов или количестве байт.

Файловая система FAT32 имеет следующую структуру.
Нумерация кластеров, используемых для записи файлов, ведется с 2. Как правило, кластер №2 используется корневым каталогом, а начиная с кластера №3 хранится массив данных. Сектора, используемые для хранения информации, представленной выше корневого каталога, в кластеры не объединяются.
Минимальный размер файла, занимаемый на диске, соответствует 1 кластеру.
Загрузочный сектор начинается следующей информацией:
- EB 58 90 – безусловный переход и сигнатура;
- 4D 53 44 4F 53 35 2E 30 MSDOS5.0;
- 00 02 – количество байт в секторе (обычно 512);
- 1 байт – количество секторов в кластере;
- 2 байта – количество резервных секторов.
Кроме того, загрузочный сектор содержит следующую важную информацию:
- 0x10 (1 байт) – количество таблиц FAT (обычно 2);
- 0x20 (4 байта) – количество секторов на диске;
- 0x2С (4 байта) – номер кластера корневого каталога;
- 0x47 (11 байт) – метка тома;
- 0x1FE (2 байта) – сигнатура загрузочного сектора ( 55 AA ).
Сектор информации файловой системы содержит:
- 0x00 (4 байта) – сигнатура ( 52 52 61 41 );
- 0x1E4 (4 байта) – сигнатура ( 72 72 41 61 );
- 0x1E8 (4 байта) – количество свободных кластеров, -1 если не известно;
- 0x1EС (4 байта) – номер последнего записанного кластера;
- 0x1FE (2 байта) – сигнатура ( 55 AA ).
Таблица FAT содержит информацию о состоянии каждого кластера на диске. Младшие 2 байт таблицы FAT хранят F8 FF FF 0F FF FF FF FF (что соответствует состоянию кластеров 0 и 1, физически отсутствующих). Далее состояние каждого кластера содержит номер кластера, в котором продолжается текущий файл или следующую информацию:
- 00 00 00 00 – кластер свободен;
- FF FF FF 0F – конец текущего файла.
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
- 1 байт – атрибут файла:
- 1 байт – зарезервирован;
- 1 байт – время создания (миллисекунды) (число от 0 до 199);
- 2 байта – время создания (с точностью до 2с):
- 2 байта – дата создания:
- 2 байта – дата последнего доступа;
- 2 байта – старшие 2 байта начального кластера;
- 2 байта – время последней модификации;
- 2 байта – дата последней модификации;
- 2 байта – младшие 2 байта начального кластера;
- 4 байта – размер файла (в байтах).
В случае работы с длинными именами файлов (включая русские имена) кодировка имени файла производится в системе кодировки UTF-16. При этого для кодирования каждого символа отводится 2 байта. При этом имя файла записывается в виде следующей структуры:
- 1 байт последовательности;
- 10 байт содержат младшие 5 символов имени файла;
- 1 байт атрибут;
- 1 байт резервный;
- 1 байт – контрольная сумма имени DOS;
- 12 байт содержат младшие 3 символа имени файла;
- 2 байта – номер первого кластера;
- остальные символы длинного имени.
Далее следует запись, включающая имя файла в формате 8.3 в обычном формате.
Работа с файлами в языке Си
Для программиста открытый файл представляется как последовательность считываемых или записываемых данных. При открытии файла с ним связывается поток ввода-вывода . Выводимая информация записывается в поток, вводимая информация считывается из потока.
Когда поток открывается для ввода-вывода, он связывается со стандартной структурой типа FILE , которая определена в stdio.h . Структура FILE содержит необходимую информацию о файле.
Открытие файла осуществляется с помощью функции fopen() , которая возвращает указатель на структуру типа FILE , который можно использовать для последующих операций с файлом.
name – имя открываемого файла (включая путь),
type — указатель на строку символов, определяющих способ доступа к файлу:
- "r" — открыть файл для чтения (файл должен существовать);
- "w" — открыть пустой файл для записи; если файл существует, то его содержимое теряется;
- "a" — открыть файл для записи в конец (для добавления); файл создается, если он не существует;
- "r+" — открыть файл для чтения и записи (файл должен существовать);
- "w+" — открыть пустой файл для чтения и записи; если файл существует, то его содержимое теряется;
- "a+" — открыть файл для чтения и дополнения, если файл не существует, то он создаётся.
Возвращаемое значение — указатель на открытый поток. Если обнаружена ошибка, то возвращается значение NULL .
Функция fclose() закрывает поток или потоки, связанные с открытыми при помощи функции fopen() файлами. Закрываемый поток определяется аргументом функции fclose() .
Возвращаемое значение: значение 0, если поток успешно закрыт; константа EOF , если произошла ошибка.
Чтение символа из файла:
Аргументом функции является указатель на поток типа FILE . Функция возвращает код считанного символа. Если достигнут конец файла или возникла ошибка, возвращается константа EOF .
Запись символа в файл:
Аргументами функции являются символ и указатель на поток типа FILE . Функция возвращает код считанного символа.
Функции fscanf() и fprintf() аналогичны функциям scanf() и printf() , но работают с файлами данных, и имеют первый аргумент — указатель на файл.
Функции fgets() и fputs() предназначены для ввода-вывода строк, они являются аналогами функций gets() и puts() для работы с файлами.
Символы читаются из потока до тех пор, пока не будет прочитан символ новой строки ‘\n’ , который включается в строку, или пока не наступит конец потока EOF или не будет прочитано максимальное количество символов. Результат помещается в указатель на строку и заканчивается нуль- символом ‘\0’ . Функция возвращает адрес строки.
Копирует строку в поток с текущей позиции. Завершающий нуль- символ не копируется.
Пример Ввести число и сохранить его в файле s1.txt. Считать число из файла s1.txt, увеличить его на 3 и сохранить в файле s2.txt.

Результат выполнения — 2 файла
Работа с файлами в C++ описана здесь.
Добрый день. Подскажите пожалуйста, возможно ли в С++ читать содержимое только файлов имеющих в своём имени только цифры? Например читать: 56.txt, 78.txt,99.txt и т.д. И не читать hellou.txt. Если да какие библиотеки и функции нужно использовать? В интернете по обработке имен файлов мало инфы.
Возможно сделать проверку имени файла на соответствие формату. Но само имя файла задаётся пользователем.
Здравствуйте, я сделал посимвольный вывод текстового файла. Как можно реализовать запрет переноса слов в консоли?
Считать количество выведенных символов в строке и длину следующего слова. Если количество символов +длина слова больше 80, то нужно перенести строчку и начать вывод с новой строки. При этом пост вольный вывод не получится - придется использовать буфер (массив) для хранения следующего слова.
Работа с файлами с использованием конструкций языка Си была рассмотрена здесь.
Для программиста открытый файл представляется как последовательность считываемых или записываемых данных. При открытии файла с ним связывается поток ввода-вывода . Выводимая информация записывается в поток, вводимая информация считывается из потока.
Для работы с файлами необходимо подключить заголовочный файл . В нем определены несколько классов и подключены заголовочные файлы
Файловый ввод-вывод аналогичен стандартному вводу-выводу, единственное отличие – это то, что ввод-вывод выполнятся не на экран, а в файл.
Если ввод-вывод на стандартные устройства выполняется с помощью объектов cin и cout , то для организации файлового ввода-вывода достаточно создать собственные объекты, которые можно использовать аналогично этим операторам.
При работе с файлом можно выделить следующие этапы:
- создать объект класса fstream (возможно, ofstream или ifstream );
- связать объект класса fstream с файлом, который будет использоваться для операций ввода-вывода;
- осуществить операции ввода-вывода в файл;
- закрыть файл.

В результате будет создан файл
Режимы открытия файлов устанавливают характер использования файлов. Для установки режима в классе ios предусмотрены константы, которые определяют режим открытия файлов.
| Константа | Описание |
| ios::in | открыть файл для чтения |
| ios::out | открыть файл для записи |
| ios::ate | при открытии переместить указатель в конец файла |
| ios::app | открыть файл для записи в конец файла |
| ios::trunc | удалить содержимое файла, если он существует |
| ios::binary | открытие файла в двоичном режиме |
Режимы открытия файлов можно устанавливать непосредственно при создании объекта или при вызове метода open() .
Режимы открытия файлов можно комбинировать с помощью поразрядной логической операции ИЛИ | , например:
ios::out | ios::in - открытие файла для записи и чтения.
Произвольный доступ к файлу
Система ввода-вывода С++ позволяет осуществлять произвольный доступ с использованием методов seekg() и seekp() .
Смещение определяет область значений в пределах файла ( long int ).
Система ввода-вывода С++ обрабатывает два указателя, ассоциированные с каждым файлом:
- get pointer g - определяет, где именно в файле будет производиться следующая операция ввода;
- put pointer p - определяет, где именно в файле будет производиться следующая операция вывода.
Позиция смещения определяется как
| Позиция | Значение |
| ios::beg | Начало файла |
| ios::cur | Текущее положение |
| ios::end | Конец файла |
Всякий раз, когда осуществляются операции ввода или вывода, соответствующий указатель автоматически перемещается.
С помощью методов seekg() и seekp() можно получить доступ к файлу в произвольном месте.
Можно определить текущую позицию файлового указателя, используя следующие функции:
- streampos tellg() - позиция для ввода
- streampos tellp() - позиция для вывода
В результате выполнения первой части программы будет создан файл
Вторая часть программы выведет в консоль
Ещё один пример. Допустим, нам нужно заполнять таблицу
Причем каждая вновь введенная строка должна размещаться в таблице непосредственно под "шапкой".
Алгоритм решения задачи следующий:
- формируем очередную строку для вывода
- открываем файл для чтения, считываем из него данные и сохраняем их в массив строк
- закрываем файл
- открываем файл для записи
- выводим "шапку" таблицы
- выводим новую строку
- выводим все сохраненные строки обратно в файл, начиная со строки после шапки
fstream inOut;
inOut.open( "file.txt" , ios::in); // открываем файл для ввода
// Считываем из файла имеющиеся данные
int count = 0;
while (inOut.getline(line[count], 100)) count++;
inOut.close(); // закрываем файл
Результат выполнения:

Полученный файл данных:
Здравствуйте Елена. Скажите, а можно ли как то узнать наступивший конец файла. Например, если количество строк в файле неизвестно, а нужно организовать цикл по их считыванию и прервать его по окончанию файла.
ifstream test( "U:\\prog struct17\\list.txt" ); // полное имя файла
if (!test) cout return 0;
while (!test.eof())< //пока не конец.
. >
Елена, здравствуйте! Помогите, пожалуйста. Есть код, работающий, но вывод делает в консоль, а так как вывод очень большой, то все результаты там не помещаются, только малая последняя часть. Подскажите, пожалуйста, где и что изменить, чтоб вывод записывало в файл. Если можно очень подробно или прям конкретным примером, я со всем этим только только столкнулась, поэтому пока не особо соображаю(( Вот мой код
import static java.lang.System.out;
import java.util.Arrays;
class Combinations
private static final int M = 12;
private static final int N = 24;
private static int [] generateCombinations( int [] arr)
if (arr == null)
arr = new int [M];
for ( int i = 0; i < M; i++)
arr[i] = i + 1;
return arr;
>
for ( int i = M - 1; i >= 0; i--)
if (arr[i] < N - M + i + 1)
arr[i]++;
for ( int j = i; j < M - 1; j++)
arr[j + 1] = arr[j] + 1;
return arr;
>
return null;
>
public static void main(String args[])
int [] arr = null;
while ((arr = generateCombinations(arr)) != null)
out.println(Arrays.toString(arr));
>
>
Думаю, что "в правильную". Можно попробовать взять, например, среднее арифметическое для каждой точки из двух файлов. Но это нужно анализировать при отладке.
Елена, здравствуйте. Подскажите, пожалуйста, как можно сделать так, чтобы из первой строки файла считывался размер массива, а из второй - его элементы, количество которых равно значению из первой строки. Не нашла у вас на сайте ничего про построчный ввод из файла. Заранее спасибо.
Ввод из файла осуществляется аналогично консольному вводу. После считывания порции данных указатель позиции файла автоматически перемещается на ее конец.
Да, но у вас в статьях нет ничего про, к примеру, getline. По вашим статьям я изучаю практически все, очень понятно и доходчиво написано, но этот блок то ли я не могу найти, то ли его нет. Подскажите, у вас на сайте есть статья, где более подробно описывается файловый ввод и вывод?
Здравствуйте, попыталась сделать вывод данных в файл, но почему то только создался документ, а данных там нет. Что не так?
ofstream fout( "file.txt" , ios::out);
fout.open( "file.txt" , ios::out);
for ( int i = 0; i < SIZE; i++)
for ( int j = 0; j < SIZE; j++)
printf( "%5d " , a[i][j]);
printf( "\n" );
Можно ли как-то скопировать половину строки ? Выше вы копировали от середины и до конца, но мне нужно наоборот- от начала до середины ( или 10-го символа)
Не совсем правильно сформулировала , от определённого индекса до определённого индекса. То есть, у нас есть строка(char sr[50]="blablablabla";) Я хочу скопировать с третього индекса по 10.
int main( int argc, char * argv[]) system( "chcp 1251" );
system( "cls" );
char line[LINES][150];
char str[30];
char s[] = "| | | | " ;
cout cin.getline(str, 30);
for ( int i = 0; str[i] != '\0'; i++)
s[i + 0] = str[i];
cout cin.getline(str, 30);
for ( int i = 0; str[i] != '\0'; i++)
s[i + 33] = str[i];
cout cin.getline(str, 30);
for ( int i = 0; str[i] != '\0'; i++)
s[i + 61] = str[i];
cout cin.getline(str, 30);
for ( int i = 0; str[i] != '\0'; i++)
s[i + 97] = str[i];
Почему файл объявлен как поток вывода, а открывается для ввода? Чему равен count? Где тут люди? Почему при вводе нет цикла?
Здравствуйте, подскажите как считать данные из файла, сохранённых в следующем виде: Check Type | Check name | Cost check | 12 |Full |50000 | 38 |Half |25000 | 156 |Special |79000 | и записать данные в структуру. Например: Поле "Struct->CheckType" имеет значение "12" Поле "Struct->CheckName" имеет значение "Full" Поле "Struct->CostCheck" имеет значение "50000"
Считывать по строкам, далее строку разделять по символу | и присваивать значения полям структуры. Если поля структуры целочисленные, то предусмотреть ещё перевод из строки в число.
Здравствуйте. Возникла проблема, когда пытался переделать ваш код под себя. Выдается очень странный баг, хотя программа компилируется. Я добавил возможность использования программы повторно, без перезапуска консоли, через цикл while. И немного изменил шапку и ее ввод. В общем вот код. Если получится найти причину, буду очень благодарен.
fstream abonent;
abonent.open( "file.txt" , ios::in);
int count = 0;
while (abonent.getline(line[count], 100)) count++;
abonent.close();
Пока вижу 2 бага, не знаю, какой Вы имеете в виду. 1. Когда вводим данные второго и последующих лиц, программа "глотает" Имя. 2. Если, допустим, фамилия второго человека окажется короче, чем у первого, то она будет дополнена "остатком" предыдущей фамилии.
Считать всю строку. Найти ее длину с помощью strlen() и сместить курсор на "минус" половину этого значения от текущей позиции.
Спасибо за статью. Познавательно. Пробую использовать данный вывод в файл, но возникла проблема: Файл создается и очищается (проверено) но запись в файл не происходит, и после выполнения данного кода
std::string textoutbuf = "yjjfhjshdsjhf dkcfjdhj jfcjh 111111" ;
textoutbuf.push_back('\n');
//m_sock.fileLog m_sock.fileLog INT qqq = GetLastError();
m_sock.fileLog.flush(); //очистить поток
m_sock.fileLog.close();
файл всегда нулевой длины. Что уже не пробовал, читал форумы но ответа пока не нашел. Может Вы подскажете в чем может быть проблема? Спасибо.
Возможно, я чего-то не учитываю, поскольку приведен только фрагмент кода. Но такая реализация позволит получить файл с данными:
А как записать данные в файл с названием, определяемым самим пользователем? Насколько я понял, в качестве названия файла можно использовать только константу (?)
извините, я наверно вас уже заколебал, с этой 4 строчкой. Но мне надо прочитать строчку из файла и вывести ее в консоль. Т.е. В файле есть 4 строка мне ее надо прочитать и вывести на экран. inOut.open( "file.txt" ,ios::out); for ( int i=0; i <4; i++) cout<
А как происходит перебор строк? Я как понимаю, мы читаем строку в массив line[1]; Потом читаем еще раз строку, но в массив line[2]; и т.д. до line[100]. А где мы говорим, что мы не читаем одну и туже строчку то? Как встать то на строчку 5? И прочитать что в строке 5 У нас Петров Петр.
Почему если в файле "file.txt" есть информация, то данный код не просто читает он удаляет все из файла?
При считывании строки указатель позиции в файле автоматически смещается на её длину. Поэтому если мы считаем 4 строки, то окажемся на начале 5-ой. Считав её, мы получим нужную нам информацию.
Если данные из файла считываются, то они не удаляются. Удаление данных происходит только при открытии файла в режиме записи (строка 32 последнего примера в статье).
Спасибо большое за ответы. Но а как мне получить строку под номером 4? Допустим я не знаю что в файле, и я хочу прочитать только 4 строчку. line[4] выводит все четвертые буквы всех строк, но не всю строку целиком. Может как то можно получить массив строк и массив символов за раз? Например my_line_txt[4][5] - четвертая строка 5 символ.
line[4] - это и есть 4-ая строка. Первый индекс в массиве line[][] - это номер строки, второй - номер символа в строке.
Подскажите пожалуйста (нигде найти не могу) Как выводить в файл строки сверху. было То, как зверь, она завоет, То заплачет, как дитя, Надо вставить сверху строчки, что бы получилось так: Буря мглою небо кроет, Вихри снежные крутя; То, как зверь, она завоет, То заплачет, как дитя, Только не говорите что для этого отдельный файл создавать надо. )
Если использовать флаг ios::beg Да, он ставит курсор в начало файла. Но он удалит весь текст который там был. И вставить строчку не получиться. Вместо вставки происходит замена.
Я, конечно, не буду говорить, что нужно создавать отдельный файл :) Но придётся считать всю информацию из файла и где-то её сохранить. Потом открыть файл для записи. Записать недостающие строки сверху, а потом снова выгрузить сохраненное содержимое файла.
А если надо заполнить такую таблицу что бы последние введенные данные были наверху. То есть, есть шапка которую нельзя трогать. файл 1 "с шапкой" файл 2 "с новой строкой" файл 3 = файл 1+файл2; // итоговый наш файл файл 2 = получили новую строку файл 4 = скопировать все с 4 строчки и ниже из файла №3 файл 3 = встаем на четвертую строчку и добавляем файл №2 с нашей строкой файл 3 = копируем все из файла 4. Только так можно это реализовать? Как можно установить курсор на 4 строчку? ----------------------------------------------------------------------------------- | Фамилия | Имя | Отчество | дата рождения | хобби | ----------------------------------------------------------------------------------- |_________|_____|__________|_______________|________| |_________|_____|__________|_______________|________| |_________|_____|__________|_______________|________| |_________|_____|__________|_______________|________|
Как можно установить курсор на 4 строчку? И как можно скопировать все что ниже 4 строчки. Или удалить все что выше 4 строчки.

Зачем нужны разные форматы файлов
Серьезное узкое место в производительности приложений с поддержкой HDFS, таких как MapReduce и Spark — время поиска, чтения, а также записи данных. Эти проблемы усугубляются трудностями в управлении большими наборами данных, если у нас не фиксированная, а эволюционирующая схема, или присутствуют некие ограничения на хранение.
Обработка больших данных увеличивает нагрузку на подсистему хранения — Hadoop хранит данные избыточно для достижения отказоустойчивости. Кроме дисков, нагружаются процессор, сеть, система ввода-вывода и так далее. По мере роста объема данных увеличивается и стоимость их обработки и хранения.
Различные форматы файлов в Hadoop придуманы для решения именно этих проблем. Выбор подходящего формата файла может дать некоторые существенные преимущества:
- Более быстрое время чтения.
- Более быстрое время записи.
- Разделяемые файлы.
- Поддержка эволюции схем.
- Расширенная поддержка сжатия.
Формат файлов Avro
Для сериализации данных широко используют Avro — это основанный на строках, то есть строковый, формат хранения данных в Hadoop. Он хранит схему в формате JSON, облегчая ее чтение и интерпретацию любой программой. Сами данные лежат в двоичном формате, компактно и эффективно.
Ключевой особенностью Avro является надежная поддержка схем данных, которые изменяются с течением времени, то есть эволюционируют. Avro понимает изменения схемы — удаление, добавление или изменение полей.
Avro поддерживает разнообразные структуры данных. Например, можно создать запись, которая содержит массив, перечислимый тип и подзапись.

Этот формат идеально подходит для записи в посадочную (переходную) зону озера данных (озеро данных, или data lake — коллекция инстансов для хранения различных типов данных в дополнение непосредственно к источникам данных).
Так вот, для записи в посадочную зону озера данных такой формат лучше всего подходит по следующим причинам:
- Данные из этой зоны обычно считываются целиком для дальнейшей обработки нижестоящими системами — и формат на основе строк в этом случае более эффективен.
- Нижестоящие системы могут легко извлекать таблицы схем из файлов — не нужно хранить схемы отдельно во внешнем мета-хранилище.
- Любое изменение исходной схемы легко обрабатывается (эволюция схемы).
Формат файлов Parquet
Parquet — опенсорсный формат файлов для Hadoop, который хранит вложенные структуры данных в плоском столбчатом формате.
По сравнению с традиционным строчным подходом, Parquet более эффективен с точки зрения хранения и производительности.
Это особенно полезно для запросов, которые считывают определенные столбцы из широкой (со многими столбцами) таблицы. Благодаря формату файлов читаются только необходимые столбцы, так что ввод-вывод сводится к минимуму.
Небольшое отступление-пояснение: чтобы лучше понять формат файла Parquet в Hadoop, давайте посмотрим, что такое основанный на столбцах — то есть столбчатый — формат. В таком формате вместе хранятся однотипные значения каждого столбца.
Например, запись включает поля ID, Name и Department. В этом случае все значения столбца ID будут храниться вместе, как и значения столбца Name и так далее. Таблица получит примерно такой вид:
| ID | Name | Department |
| 1 | emp1 | d1 |
| 2 | emp2 | d2 |
| 3 | emp3 | d3 |
Столбчатый формат более эффективен, когда вам нужно запросить из таблицы несколько столбцов. Он прочитает только необходимые столбцы, потому что они находятся по соседству. Таким образом, операции ввода-вывода сводятся к минимуму.
Например, вам нужен только столбец NAME. В строковом формате каждую запись в наборе данных нужно загрузить, разобрать по полям, а затем извлечь данные NAME. Столбчатый формат позволяет перейти непосредственно к столбцу Name, так как все значения для этого столбца хранятся вместе. Не придется сканировать всю запись.
Таким образом, столбчатый формат повышает производительность запросов, поскольку для перехода к требуемым столбцам требуется меньше времени поиска и сокращается количество операций ввода-вывода, ведь происходит чтение только нужных столбцов.
Одна из уникальных особенностей Parquet заключается в том, что в таком формате он может хранить данные с вложенными структурами. Это означает, что в файле Parquet даже вложенные поля можно читать по отдельности без необходимости читать все поля во вложенной структуре. Для хранения вложенных структур Parquet использует алгоритм измельчения и сборки (shredding and assembly).

Чтобы понять формат файла Parquet в Hadoop, необходимо знать следующие термины:

Здесь заголовок просто содержит волшебное число PAR1 (4 байта), которое идентифицирует файл как файл формата Parquet.
В футере записано следующее:
- Метаданные файла, которые содержат стартовые координаты метаданных каждого столбца. При чтении нужно сначала прочитать метаданные файла, чтобы найти все интересующие фрагменты столбцов. Затем фрагменты столбцов следует читать последовательно. Еще метаданные включают версию формата, схему и любые дополнительные пары ключ-значение.
- Длина метаданных (4 байта).
- Волшебное число PAR1 (4 байта).
Формат файлов ORC
Оптимизированный строково-столбчатый формат файлов (Optimized Row Columnar, ORC) предлагает очень эффективный способ хранения данных и был разработан, чтобы преодолеть ограничения других форматов. Хранит данные в идеально компактном виде, позволяя пропускать ненужные детали — при этом не требует построения больших, сложных или обслуживаемых вручную индексов.
Преимущества формата ORC:
- Один файл на выходе каждой задачи, что уменьшает нагрузку на NameNode (узел имен).
- Поддержка типов данных Hive, включая DateTime, десятичные и сложные типы данных (struct, list, map и union).
- Одновременное считывание одного и того же файла разными процессами RecordReader.
- Возможность разделения файлов без сканирования на наличие маркеров.
- Оценка максимально возможного выделения памяти кучи на процессы чтения/записи по информации в футере файла.
- Метаданные сохраняются в бинарном формате сериализации Protocol Buffers, который позволяет добавлять и удалять поля.

ORC хранит коллекции строк в одном файле, а внутри коллекции строчные данные хранятся в столбчатом формате.
Файл ORC хранит группы строк, которые называются полосами (stripes) и вспомогательную информацию в футере файла. Postscript в конце файла содержит параметры сжатия и размер сжатого футера.
По умолчанию размер полосы составляет 250 МБ. За счет полос такого большого размера чтение из HDFS выполняется более эффективно: большими непрерывными блоками.
В футере файла записан список полос в файле, количество строк на полосу и тип данных каждого столбца. Там же записано результирующее значение count, min, max и sum по каждому столбцу.
Футер полосы содержит каталог местоположений потока.
Строчные данные используются при сканировании таблиц.
Индексные данные включают минимальные и максимальные значения для каждого столбца и позиции строк в каждом столбце. Индексы ORC используются только для выбора полос и групп строк, а не для ответа на запросы.
Читайте также: