
Часть программы выгрузки и загрузки по команде процессора для экономии занимаемой памяти
Чтобы обеспечить эффективный контроль использования памяти, ОС должна выполнять следующие функции:
- отображение адресного пространства процесса на конкретные области физической памяти;
- распределение памяти между конкурирующими процессами;
- контроль доступа к адресным пространствам процессов;
- выгрузка процессов (целиком или частично) во внешнюю память, когда в оперативной памяти недостаточно места;
- учет свободной и занятой памяти.
В следующих разделах лекции рассматривается ряд конкретных схем управления памятью. Каждая схема включает в себя определенную идеологию управления, а также алгоритмы и структуры данных и зависит от архитектурных особенностей используемой системы. Вначале будут рассмотрены простейшие схемы. Доминирующая на сегодня схема виртуальной памяти будет описана в последующих лекциях.
Простейшие схемы управления памятью
Первые ОС применяли очень простые методы управления памятью. Вначале каждый процесс пользователя должен был полностью поместиться в основной памяти , занимать непрерывную область памяти, а система принимала к обслуживанию дополнительные пользовательские процессы до тех пор, пока все они одновременно помещались в основной памяти . Затем появился "простой свопинг" (система по-прежнему размещает каждый процесс в основной памяти целиком, но иногда на основании некоторого критерия целиком сбрасывает образ некоторого процесса из основной памяти во внешнюю и заменяет его в основной памяти образом другого процесса). Такого рода схемы имеют не только историческую ценность. В настоящее время они применяются в учебных и научно-исследовательских модельных ОС, а также в ОС для встроенных (embedded) компьютеров.
Схема с фиксированными разделами
Самым простым способом управления оперативной памятью является ее предварительное (обычно на этапе генерации или в момент загрузки системы) разбиение на несколько разделов фиксированной величины. Поступающие процессы помещаются в тот или иной раздел. При этом происходит условное разбиение физического адресного пространства . Связывание логических и физических адресов процесса происходит на этапе его загрузки в конкретный раздел, иногда – на этапе компиляции.
Каждый раздел может иметь свою очередь процессов, а может существовать и глобальная очередь для всех разделов(см. рис. 8.4).
Эта схема была реализована в IBM OS/360 ( MFT ), DEC RSX-11 и ряде других систем.
Подсистема управления памятью оценивает размер поступившего процесса, выбирает подходящий для него раздел, осуществляет загрузку процесса в этот раздел и настройку адресов.
Рис. 8.4. Схема с фиксированными разделами: (a) – с общей очередью процессов, (b) – с отдельными очередями процессов
Очевидный недостаток этой схемы – число одновременно выполняемых процессов ограничено числом разделов.
Другим существенным недостатком является то, что предлагаемая схема сильно страдает от внутренней фрагментации – потери части памяти, выделенной процессу, но не используемой им. Фрагментация возникает потому, что процесс не полностью занимает выделенный ему раздел или потому, что некоторые разделы слишком малы для выполняемых пользовательских программ.
Один процесс в памяти
Частный случай схемы с фиксированными разделами – работа менеджера памяти однозадачной ОС. В памяти размещается один пользовательский процесс. Остается определить, где располагается пользовательская программа по отношению к ОС – в верхней части памяти, в нижней или в средней. Причем часть ОС может быть в ROM (например, BIOS, драйверы устройств). Главный фактор, влияющий на это решение, – расположение вектора прерываний, который обычно локализован в нижней части памяти, поэтому ОС также размещают в нижней. Примером такой организации может служить ОС MS-DOS.
Защита адресного пространства ОС от пользовательской программы может быть организована при помощи одного граничного регистра, содержащего адрес границы ОС.
Оверлейная структура
Так как размер логического адресного пространства процесса может быть больше, чем размер выделенного ему раздела (или больше, чем размер самого большого раздела), иногда используется техника, называемая оверлей (overlay) или организация структуры с перекрытием. Основная идея – держать в памяти только те инструкции программы, которые нужны в данный момент.
Потребность в таком способе загрузки появляется, если логическое адресное пространство системы мало, например 1 Мбайт (MS-DOS) или даже всего 64 Кбайта (PDP-11), а программа относительно велика. На современных 32-разрядных системах, где виртуальное адресное пространство измеряется гигабайтами, проблемы с нехваткой памяти решаются другими способами (см. раздел "Виртуальная память").
Рис. 8.5. Организация структуры с перекрытием. Можно поочередно загружать в память ветви A-B, A-C-D и A-C-E программы
Коды ветвей оверлейной структуры программы находятся на диске как абсолютные образы памяти и считываются драйвером оверлеев при необходимости. Для описания оверлейной структуры обычно используется специальный несложный язык (overlay description language). Совокупность файлов исполняемой программы дополняется файлом (обычно с расширением . odl ), описывающим дерево вызовов внутри программы. Для примера, приведенного на рис. 8.5, текст этого файла может выглядеть так:
Синтаксис подобного файла может распознаваться загрузчиком. Привязка к физической памяти происходит в момент очередной загрузки одной из ветвей программы.
Оверлеи могут быть полностью реализованы на пользовательском уровне в системах с простой файловой структурой. ОС при этом лишь делает несколько больше операций ввода-вывода. Типовое решение – порождение линкером специальных команд, которые включают загрузчик каждый раз, когда требуется обращение к одной из перекрывающихся ветвей программы.
Тщательное проектирование оверлейной структуры отнимает много времени и требует знания устройства программы, ее кода, данных и языка описания оверлейной структуры . По этой причине применение оверлеев ограничено компьютерами с небольшим логическим адресным пространством . Как мы увидим в дальнейшем, проблема оверлейных сегментов , контролируемых программистом, отпадает благодаря появлению систем виртуальной памяти.
Заметим, что возможность организации структур с перекрытиями во многом обусловлена свойством локальности, которое позволяет хранить в памяти только ту информацию, которая необходима в конкретный момент вычислений.
Динамическое распределение. Свопинг
Имея дело с пакетными системами , можно обходиться фиксированными разделами и не использовать ничего более сложного. В системах с разделением времени возможна ситуация, когда память не в состоянии содержать все пользовательские процессы. Приходится прибегать к свопингу (swapping) – перемещению процессов из главной памяти на диск и обратно целиком. Частичная выгрузка процессов на диск осуществляется в системах со страничной организацией (paging) и будет рассмотрена ниже.
Выгруженный процесс может быть возвращен в то же самое адресное пространство или в другое. Это ограничение диктуется методом связывания . Для схемы связывания на этапе выполнения можно загрузить процесс в другое место памяти.
Свопинг не имеет непосредственного отношения к управлению памятью, скорее он связан с подсистемой планирования процессов. Очевидно, что свопинг увеличивает время переключения контекста. Время выгрузки может быть сокращено за счет организации специально отведенного пространства на диске (раздел для свопинга). Обмен с диском при этом осуществляется блоками большего размера, то есть быстрее, чем через стандартную файловую систему. Во многих версиях Unix свопинг начинает работать только тогда, когда возникает необходимость в снижении загрузки системы.
Схема с переменными разделами
В принципе, система свопинга может базироваться на фиксированных разделах . Более эффективной, однако, представляется схема динамического распределения или схема с переменными разделами, которая может использоваться и в тех случаях, когда все процессы целиком помещаются в памяти, то есть в отсутствие свопинга. В этом случае вначале вся память свободна и не разделена заранее на разделы. Вновь поступающей задаче выделяется строго необходимое количество памяти, не более. После выгрузки процесса память временно освобождается. По истечении некоторого времени память представляет собой переменное число разделов разного размера (рис. 8.6). Смежные свободные участки могут быть объединены.
Рис. 8.6. Динамика распределения памяти между процессами (серым цветом показана неиспользуемая память)
В какой раздел помещать процесс? Наиболее распространены три стратегии.
- Стратегия первого подходящего (First fit). Процесс помещается в первый подходящий по размеру раздел.
- Стратегия наиболее подходящего ( Best fit ). Процесс помещается в тот раздел, где после его загрузки останется меньше всего свободного места.
- Стратегия наименее подходящего (Worst fit). При помещении в самый большой раздел в нем остается достаточно места для возможного размещения еще одного процесса.
Моделирование показало, что доля полезно используемой памяти в первых двух случаях больше, при этом первый способ несколько быстрее. Попутно заметим, что перечисленные стратегии широко применяются и другими компонентами ОС, например для размещения файлов на диске.
Типовой цикл работы менеджера памяти состоит в анализе запроса на выделение свободного участка (раздела), выборе его среди имеющихся в соответствии с одной из стратегий (первого подходящего, наиболее подходящего и наименее подходящего), загрузке процесса в выбранный раздел и последующих изменениях таблиц свободных и занятых областей. Аналогичная корректировка необходима и после завершения процесса. Связывание адресов может осуществляться на этапах загрузки и выполнения.
Этот метод более гибок по сравнению с методом фиксированных разделов , однако ему присуща внешняя фрагментация – наличие большого числа участков неиспользуемой памяти, не выделенной ни одному процессу. Выбор стратегии размещения процесса между первым подходящим и наиболее подходящим слабо влияет на величину фрагментации . Любопытно, что метод наиболее подходящего может оказаться наихудшим, так как он оставляет множество мелких незанятых блоков.
Статистический анализ показывает, что пропадает в среднем 1/3 памяти! Это известное правило 50% (два соседних свободных участка в отличие от двух соседних процессов могут быть объединены).
Одно из решений проблемы внешней фрагментации – организовать сжатие, то есть перемещение всех занятых (свободных) участков в сторону возрастания (убывания) адресов, так, чтобы вся свободная память образовала непрерывную область. Этот метод иногда называют схемой с перемещаемыми разделами. В идеале фрагментация после сжатия должна отсутствовать. Сжатие, однако, является дорогостоящей процедурой, алгоритм выбора оптимальной стратегии сжатия очень труден и, как правило, сжатие осуществляется в комбинации с выгрузкой и загрузкой по другим адресам.
Уже давно существует проблема размещения в памяти программ, размер которых превышает размер доступной памяти. Один из вариантов ее решения организация структур с перекрытием рассмотрен в предыдущей главе. При этом предполагалось активное участие программиста в процессе сегментации и загрузки программы. Было предложено переложить проблему на компьютер. Развитие архитектуры компьютеров привело к значительному усложнению организации памяти, соответственно, усложнились и расширились задачи операционной системы по управлению памятью. Одним из главных усовершенствований архитектуры стало появление виртуальной памяти (virtual memory). Она впервые была реализована в 1959 г. на компьютере Атлас, разработанном в Манчестерском университете, и стала популярной только спустя десятилетие.
При помощи виртуальной памяти обычно решают две задачи.
Во-первых, виртуальная память позволяет адресовать пространство, гораздо большее, чем емкость физической памяти конкретной вычислительной машины. В соответствии с принципом локальности для реальных программ обычно нет необходимости в помещении их в физическую память целиком.
Возможность выполнения программы, находящейся в памяти лишь частично имеет ряд вполне очевидных преимуществ:
1) Программа не ограничена величиной физической памяти. Упрощается разработка программ, поскольку можно задействовать большие виртуальные пространства, не заботясь о размере используемой памяти.
2) Поскольку появляется возможность частичного помещения программы (процесса) в память и гибкого перераспределения памяти между программами, можно разместить в памяти больше программ, что увеличивает загрузку процессора и пропускную способность системы.
3) Объем ввода-вывода для выгрузки части программы на диск может быть меньше, чем в варианте классического свопинга, в итоге, каждая программа будет работать быстрее.
Таким образом, возможность обеспечения (при поддержке операционной системы) для программы видимости практически неограниченной (32- или 64-разрядной) адресуемой пользовательской памяти при наличии основной памяти существенно меньших размеров очень важный аспект.
Введение виртуальной памяти позволяет решать другую задачу - обеспечение контроля доступа к отдельным сегментам памяти и в частности защиту пользовательских программ друг от друга и защиту ОС от пользовательских программ.
С целью защиты виртуальная память поддерживалась и на компьютерах с 16-разрядной адресацией, в которых объем основной памяти зачастую существенно превышал 64 Кбайта (размер виртуальной памяти). Например, 16-разрядный компьютер PDP-11/70 мог иметь до 2 Мбайт оперативной памяти. Операционная система этого компьютера, тем не менее, поддерживала виртуальную память, основным смыслом которой являлось обеспечение защиты и перераспределения основной памяти между пользовательскими процессами.
Напомним, что в системах с виртуальной памятью генерируемые программой адреса (логические адреса), называются виртуальными, и они формируют виртуальное адресное пространство. В отсутствие механизма виртуальной памяти виртуальное адресное пространство непосредственно отображается в физическое пространство.
Хотя известны и чисто программные реализации виртуальной памяти, это направление получило наиболее широкое развитие после получения соответствующей аппаратной поддержки. Идея аппаратной части механизма виртуальной памяти состоит в том, что адрес памяти, вырабатываемый командой, интерпретируется аппаратурой не как реальный адрес некоторого элемента основной памяти, а как некоторая структура, где адрес является лишь одним из компонентов наряду с атрибутами, характеризующими способ обращения по данному адресу.
Традиционно считается, что существует три модели виртуальной памяти:
Большинством современных платформ поддерживается страничная модель виртуальной памяти (Windows, Unix). Сегментная модель использовалась в OS/2 и MS-DOS.
Управление памятью – одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере – включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.


Это не значит, что ядро использует так много физической памяти – просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов:
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым – пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты – всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:

Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам – адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент отображения в память и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало места, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса – это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры – достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack(), которая, в свою очередь, вызывает acct_stack_growth(), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться – подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека – единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент отображения в память. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap() в Linux или CreateFileMapping() / MapViewOfFile() в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc(), библиотека C создаст такую анонимное отображение вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt().)
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk(). Управление кучей – дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

И вот мы добрались до самой нижней части схемы – BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers , то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10 , то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватное отображение в память (private memory mapping) – а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:

Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированного в память, есть своя область в сегменте mmap, а у динамических библиотек – дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump – вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье – это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему:
Под памятью ( memory ) в данном случае подразумевается оперативная (основная) память компьютера. В однопрограммных операционных системах основная память разделяется на две части. Одна часть для операционной системы (резидентный монитор , ядро ), а вторая – для выполняющейся в текущий момент времени программы. В многопрограммных ОС "пользовательская" часть памяти – важнейший ресурс вычислительной системы – должна быть распределена для размещения нескольких процессов, в том числе процессов ОС. Эта задача распределения выполняется операционной системой динамически специальной подсистемой управления памятью ( memory management ). Эффективное управление памятью жизненно важно для многозадачных систем. Если в памяти будет находиться небольшое число процессов, то значительную часть времени процессы будут находиться в состоянии ожидания ввода-вывода и загрузка процессора будет низкой.
В ранних ОС управление памятью сводилось просто к загрузке программы и ее данных из некоторого внешнего накопителя (перфоленты, магнитной ленты или магнитного диска) в ОЗУ . При этом память разделялась между программой и ОС. На рис. 6.3 показаны три варианта такой схемы. Первая модель раньше применялась на мэйнфреймах и мини-компьютерах. Вторая схема сейчас используется на некоторых карманных компьютерах и встроенных системах, третья модель была характерна для ранних персональных компьютеров с MS-DOS .
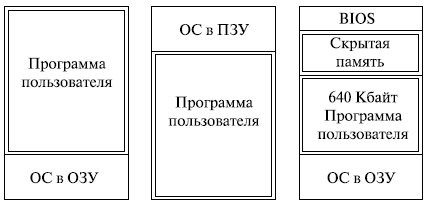
С появлением мультипрограммирования задачи ОС, связанные с распределением имеющейся памяти между несколькими одновременно выполняющимися программами, существенно усложнились.
Функциями ОС по управлению памятью в мультипрограммных системах являются:
- отслеживание (учет) свободной и занятой памяти;
- первоначальное и динамическое выделение памяти процессам приложений и самой операционной системе и освобождение памяти по завершении процессов;
- настройка адресов программы на конкретную область физической памяти;
- полное или частичное вытеснение кодов и данных процессов из ОП на диск, когда размеры ОП недостаточны для размещения всех процессов, и возвращение их в ОП;
- защита памяти, выделенной процессу, от возможных вмешательств со стороны других процессов;
- дефрагментация памяти .
Перечисленные функции особого пояснения не требуют, остановимся только на задаче преобразования адресов программы при ее загрузке в ОП.
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена, виртуальные (математические, условные, логические – все это синонимы) и физические адреса (рис. 6.4).
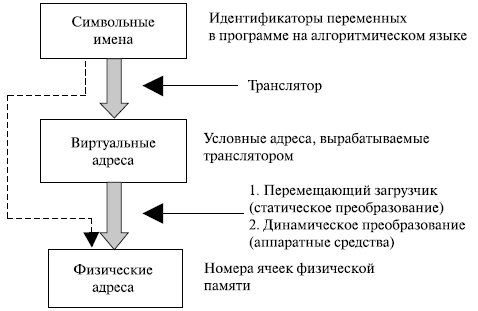
Символьные имена присваивает пользователь при написании программ на алгоритмическом языке или ассемблере. Виртуальные адреса вырабатывает транслятор , переводящий программу на машинный язык . Поскольку во время трансляции неизвестно, в какое место оперативной памяти будет загружена программа , транслятор присваивает переменным и командам виртуальные (условные) адреса, считая по умолчанию, что начальным адресом программы будет нулевой адрес .
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности будут расположены переменные и команды.
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон адресов виртуального пространства у всех процессов один и тот же и определяется разрядностью адреса процессора (для Pentium адресное пространство составляет объем, равный 2 32 байт , с диапазоном адресов от 0000.000016 до FFFF.FFFF16).
Существует два принципиально отличающихся подхода к преобразованию виртуальных адресов в физические. В первом случае такое преобразование выполняется один раз для каждого процесса во время начальной загрузки программы в память . Преобразование осуществляет перемещающий загрузчик на основании имеющихся у него данных о начальном адресе физической памяти, в которую предстоит загружать программу, а также информации, предоставляемой транслятором об адресно-зависимых элементах программы.
Второй способ заключается в том, что программа загружается в память в виртуальных адресах. Во время выполнения программы при каждом обращении к памяти операционная система преобразует виртуальные адреса в физические.
6.3. Распределение памяти
Существует ряд базовых вопросов управления памятью, которые в различных ОС решаются по -разному. Например, следует ли назначать каждому процессу одну непрерывную область физической памяти или можно выделять память участками? Должны ли сегменты программы, загруженные в память , находиться на одном месте в течение всего периода выполнения процесса или их можно время от времени сдвигать? Что делать, если сегменты программы не помещаются в имеющуюся память ? Как сократить затраты ресурсов системы на управление памятью ? Имеется и ряд других не менее интересных проблем управления памятью [5, 10, 13, 17].
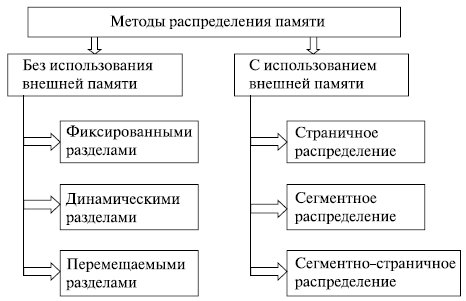
Ниже приводится классификация методов распределения памяти, в которой выделено два класса методов – с перемещением сегментов процессов между ОП и ВП (диском) и без перемещения, т.е. без привлечения внешней памяти (рис. 6.5). Данная классификация учитывает только основные признаки методов. Для каждого метода может быть использовано несколько различных алгоритмов его реализации.
На рис. 6.6 показаны два примера фиксированного распределения. Одна возможность состоит в использовании разделов одинакового размера. В этом случае любой процесс, размер которого не превышает размера раздела, может быть загружен в любой доступный раздел. Если все разделы заняты и нет ни одного процесса в состоянии готовности или работы, ОС может выгрузить процесс из любого раздела и загрузить другой процесс, обеспечивая тем самым процессор работой.

При использовании разделов с одинаковым размером имеются две проблемы.
- Программа может быть слишком велика для размещения в разделе. В этом случае программист должен разрабатывать программу, использующую оверлеи, чтобы в любой момент времени требовался только один раздел памяти. Когда требуется модуль, отсутствующий в данный момент в ОП, пользовательская программа должна сама его загрузить в раздел памяти программы. Таким образом, в данном случае управление памятью во многом возлагается на программиста.
- Использование ОП крайне неэффективно. Любая программа, независимо от ее размера, занимает раздел целиком. При этом могут оставаться неиспользованные участки памяти большого размера. Этот феномен появления неиспользованной памяти называется внутренней фрагментацией (internal fragmentation).
Бороться с этими трудностями (хотя и не устранить полностью) можно посредством использования разделов разных размеров. В этом случае программа размером до 8 Мбайт может обойтись без оверлеев, а разделы малого размера позволяют уменьшить внутреннюю фрагментацию при загрузке небольших программ.
В том случае, когда разделы имеют одинаковый раздел, размещение процессов тривиально – в любой свободный раздел. Если все разделы заняты процессами, которые не готовы к немедленной работе, любой из них может быть выгружен для освобождения памяти для нового процесса.
Когда разделы имеют разные размеры, есть два возможных подхода к назначению процессов разделам памяти. Простейший путь состоит в том, чтобы каждый процесс размещался в наименьшем разделе, способном вместить данный процесс (в этом случае в задании пользователя указывался размер требуемой памяти). При таком подходе для каждого раздела требуется очередь планировщика, в которой хранятся выгруженные из памяти процессы, предназначенные для данного раздела памяти. Достоинство такого способа в возможности распределения процессов между разделами ОП так, чтобы минимизировать внутреннюю фрагментацию.
Недостаток заключается в том, что отдельные очереди для разделов могут привести к неоптимальному распределению памяти системы в целом. Например, если в некоторый момент времени нет ни одного процесса размером от 7 до 12 Мбайт, то раздел размером 12 Мбайт будет пустовать, в то время как он мог бы использоваться меньшими процессами. Поэтому более предпочтительным является использование одной очереди для всех процессов. В момент, когда требуется загрузить процесс в ОП, выбирается наименьший доступный раздел, способный вместить данный процесс.
В целом можно отметить, что схемы с фиксированными разделами относительно просты, предъявляют минимальные требования к операционной системе; накладные расходы работы процессора на распределение памяти невелики. Однако у этих схем имеются серьезные недостатки.
- Количество разделов, определенное в момент генерации системы, ограничивает количество активных процессов (т.е. уровень мультипрограммирования).
- Поскольку размеры разделов устанавливаются заранее во время генерации системы, небольшие задания приводят к неэффективному использованию памяти. В средах, где заранее известны потребности в памяти всех задач, применение рассмотренной схемы может быть оправдано, но в большинстве случаев эффективность этой технологии крайне низка.
Для преодоления сложностей, связанных с фиксированным распределением, был разработан альтернативный подход, известный как динамическое распределение. В свое время этот подход был применен фирмой IBM в операционной системе для мэйнфреймов в OS/MVT ( мультипрограммирование с переменным числом задач – Multiprogramming With a Variable number of Tasks). Позже этот же подход к распределению памяти использован в ОС ЕС ЭВМ [12] .
При динамическом распределении образуется перемененное количество разделов переменной длины. При размещении процесса в основной памяти для него выделяется строго необходимое количество памяти. В качестве примера рассмотрим использование 64 Мбайт (рис. 6.7) основной памяти. Изначально вся память пуста, за исключением области, задействованной ОС. Первые три процесса загружаются в память , начиная с адреса, где заканчивается ОС, и используют столько памяти, сколько требуется данному процессу. После этого в конце ОП остается свободный участок памяти, слишком малый для размещения четвертого процесса. В некоторый момент времени все процессы в памяти оказываются неактивными, и операционная система выгружает второй процесс, после чего остается достаточно памяти для загрузки нового, четвертого процесса.

Поскольку процесс 4 меньше процесса 2, появляется еще свободный участок памяти. После того как в некоторый момент времени все процессы оказались неактивными, но стал готовым к работе процесс 2, свободного места в памяти для него не находится, а ОС вынуждена выгрузить процесс 1, чтобы освободить необходимое место и разместить процесс 2 в ОП. Как показывает данный пример, этот метод хорошо начинает работу, но плохо продолжает. В конечном счете, он приводит к наличию множества мелких свободных участков памяти, в которых нет возможности разместить какой-либо новый процесс. Это явление называется внешней фрагментацией ( external fragmentation ), что отражает тот факт, что сильно фрагментированной становится память , внешняя по отношению ко всем разделам.
Один из методов преодоления внешней фрагментации – уплотнение ( compaction ) процессов в ОП. Осуществляется это перемещением всех занятых участков так, чтобы вся свободная память образовала единую свободную область. В дополнение к функциям, которые ОС выполняет при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется уплотнением или сжатием.
Перечислим функции операционной системы по управлению памятью в этом случае.
- Перемещение всех занятых участков в сторону старших или младших адресов при каждом завершении процесса или для вновь создаваемого процесса в случае отсутствия раздела достаточного размера.
- Коррекция таблиц свободных и занятых областей.
- Изменение адресов команд и данных, к которым обращаются процессы при их перемещении в памяти, за счет использования относительной адресации .
- Аппаратная поддержка процесса динамического преобразования относительных адресов в абсолютные адреса основной памяти.
- Защита памяти, выделяемой процессу, от взаимного влияния других процессов.
Уплотнение может выполняться либо при каждом завершении процесса, либо только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором – реже выполняется процедура сжатия.
Так как программа перемещается по оперативной памяти в ходе своего выполнения, в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов. Достоинствами распределения памяти перемещаемыми разделами являются эффективное использование оперативной памяти, исключение внутренней и внешней фрагментации, недостатком – дополнительные накладные расходы ОС.
При использовании фиксированной схемы распределения процесс всегда будет назначаться одному и тому же разделу памяти после его выгрузки и последующей загрузке в память . Это позволяет применять простейший загрузчик , который замещает при загрузке процесса все относительные ссылки абсолютными адресами памяти, определенными на основе базового адреса загруженного процесса.
Ситуация усложняется, если размеры разделов равны (или неравны) и существует единая очередь процессов, – процесс по ходу работы может занимать разные разделы . Такая же ситуация возможна и при динамическом распределении. В этих случаях расположение команд и данных, к которым обращается процесс, не является фиксированным и изменяется всякий раз при выгрузке, загрузке или перемещении процесса. Для решения этой проблемы в программах используются относительные адреса. Это означает, что все ссылки на память в загружаемом процессе даются относительно начала этой программы. Таким образом, для корректной работы программы требуется аппаратный механизм, который бы транслировал относительные адреса в физические в процессе выполнения команды, обращающейся к памяти.
Применяемый обычно способ трансляции показан на рис. 6.8. Когда процесс переходит в состояние выполнения, в специальный регистр процесса, называемый базовым, загружается начальный адрес процесса в основной памяти. Кроме того, используется "граничный" (bounds) регистр , в котором содержится адрес последней ячейки программы. Эти значения заносятся в регистры при загрузке программы в основную память . При выполнении процесса относительные адреса в командах обрабатываются процессором в два этапа. Сначала к относительному адресу прибавляется значение базового регистра для получения абсолютного адреса. Затем полученный абсолютный адрес сравнивается со значением в граничном регистре. Если полученный абсолютный адрес принадлежит данному процессу, команда может быть выполнена. В противном случае генерируется соответствующее данной ошибке прерывание .

Изучение
Термин «память» можно определить как набор данных в определенном формате. Он используется для хранения инструкций и обработанных данных. Память состоит из большого массива или группы слов или байтов, каждое из которых имеет собственное местоположение. Основным мотивом компьютерной системы является выполнение программ. Эти программы вместе с информацией, к которой они обращаются, должны находиться в основной памяти во время выполнения. ЦП извлекает инструкции из памяти в соответствии со значением счетчика программ.
Для достижения определенной степени мультипрограммирования и правильного использования памяти важно управление памятью. Существует множество методов управления памятью, отражающих различные подходы, и эффективность каждого алгоритма зависит от ситуации.
Что такое основная память
Основная память играет центральную роль в работе современного компьютера. Основная память — это большой массив слов или байтов размером от сотен тысяч до миллиардов. Основная память — это хранилище быстро доступной информации, совместно используемой ЦП и устройствами ввода-вывода. Основная память — это место, где хранятся программы и информация, когда процессор эффективно их использует. Также основная память связана с процессором, поэтому перемещение инструкций и информации в процессор и из процессора происходит очень быстро. Основная память также известна как RAM (оперативная память). Эта память является энергозависимой. ОЗУ теряет свои данные при отключении питания.

Рисунок 1: Иерархия памяти
Что такое управление памятью
В многопрограммном компьютере операционная система находится в части памяти, а остальная часть используется несколькими процессами. Задача разделения памяти между различными процессами называется управлением памятью. Управление памятью — это метод операционной системы для управления операциями между основной памятью и диском во время выполнения процесса. Основная цель управления памятью — эффективное использование памяти.
Почему требуется управление памятью
- Выделять и освобождать память до и после выполнения процесса.
- Для отслеживания используемого пространства памяти процессами.
- Чтобы свести к минимуму проблемы фрагментации.
- Для правильного использования основной памяти.
- Сохранять целостность данных при выполнении процесса.
Теперь мы обсуждаем концепцию логического адресного пространства и физического адресного пространства:
Логическое и физическое адресное пространство
Логическое адресное пространство: адрес, генерируемый ЦП, известен как «логический адрес». Он также известен как виртуальный адрес. Логическое адресное пространство можно определить как размер процесса. Логический адрес можно изменить.
Физическое адресное пространство: адрес, видимый блоком памяти (т. Е. Тот, который загружен в регистр адреса памяти), обычно известен как «Физический адрес». Физический адрес также известен как реальный адрес. Набор всех физических адресов, соответствующих этим логическим адресам, известен как физическое адресное пространство. Физический адрес вычисляется MMU. Отображение виртуальных адресов в физические во время выполнения выполняется с помощью модуля управления памятью (MMU) аппаратного устройства. Физический адрес всегда остается постоянным.
Статическая и динамическая нагрузка
Загрузка процесса в основную память выполняется загрузчиком. Есть два разных типа загрузки:
- Статическая загрузка: — При статической загрузке загружает всю программу по фиксированному адресу. Это требует больше места в памяти.
- Динамическая загрузка: — Для выполнения процесса вся программа и все данные процесса должны находиться в физической памяти. Итак, размер процесса ограничен размером физической памяти. Для правильного использования памяти используется динамическая загрузка. При динамической загрузке подпрограмма не загружается, пока не будет вызвана. Все процедуры хранятся на диске в перемещаемом формате загрузки. Одним из преимуществ динамической загрузки является то, что неиспользуемая процедура никогда не загружается. Эта загрузка полезна, когда для ее эффективной обработки требуется большой объем кода.
Статические и динамические ссылки
Для выполнения задачи связывания используется компоновщик. Компоновщик — это программа, которая берет один или несколько объектных файлов, созданных компилятором, и объединяет их в один исполняемый файл.
- Статическая компоновка: пристатической компоновке компоновщик объединяет все необходимые программные модули в единую исполняемую программу. Таким образом, нет никакой зависимости от времени выполнения. Некоторые операционные системы поддерживают только статическое связывание, в котором библиотеки системного языка обрабатываются как любой другой объектный модуль.
- Динамическое связывание: основная концепция динамического связывания аналогична динамической загрузке. При динамической компоновке «заглушка» включается для каждой соответствующей ссылки на библиотечную подпрограмму. Заглушка — это небольшой фрагмент кода. Когда заглушка выполняется, она проверяет, находится ли нужная процедура уже в памяти или нет. Если он недоступен, программа загружает подпрограмму в память.
Обмен
Когда процесс выполняется, он должен находиться в памяти. Перекачка представляет собой процесс обмена процесс временно во вторичную память из в основной памяти, которая является быстрым, по сравнению с вторичной памятью. Подкачка позволяет запускать больше процессов и может быть помещена в память одновременно. Основная часть подкачки — это время передачи, а общее время прямо пропорционально объему подкачки памяти. Обмен также известен как развертывание, развертывание, потому что, если приходит процесс с более высоким приоритетом и ему требуется обслуживание, диспетчер памяти может заменить процесс с более низким приоритетом, а затем загрузить и выполнить процесс с более высоким приоритетом. После завершения высокоприоритетной работы,процесс с более низким приоритетом поменялись обратно в памяти и продолжал в процессе исполнения.

Непрерывное распределение памяти
Основная память должна задействовать как операционную систему, так и различные клиентские процессы. Таким образом, выделение памяти становится важной задачей операционной системы. Память обычно делится на два раздела: один для резидентной операционной системы и один для пользовательских процессов. Обычно нам нужно, чтобы несколько пользовательских процессов находились в памяти одновременно. Следовательно, нам нужно подумать о том, как выделить доступную память для процессов, которые находятся во входной очереди, ожидая ввода в память. При выделении смежной памяти каждый процесс содержится в одном непрерывном сегменте памяти.

Выделение памяти
Чтобы добиться правильного использования памяти, необходимо эффективно распределять память. Один из простейших методов распределения памяти — разделить память на несколько разделов фиксированного размера, и каждый раздел содержит ровно один процесс. Таким образом, степень мультипрограммирования определяется количеством разделов.
Распределение нескольких разделов : в этом методе процесс выбирается из входной очереди и загружается в свободный раздел. Когда процесс завершается, раздел становится доступным для других процессов.
Фиксированное распределение разделов: в этом методе операционная система поддерживает таблицу, в которой указывается, какие части памяти доступны, а какие заняты процессами. Изначально вся память доступна для пользовательских процессов и считается одним большим блоком доступной памяти. Эта доступная память известна как «отверстие». Когда процесс прибывает и ему требуется память, мы ищем достаточно большую дыру, чтобы сохранить этот процесс. Если требование выполняется, мы выделяем память для процесса, в противном случае оставляя остальную доступной для удовлетворения будущих запросов. При распределении памяти иногда возникают проблемы с динамическим распределением памяти, которые касаются того, как удовлетворить запрос размера n из списка свободных отверстий. Есть несколько решений этой проблемы:
First fit:-
При первой подгонке первое доступное свободное отверстие удовлетворяет требованиям назначенного процесса.

Здесь, на этой диаграмме, блок памяти размером 40 КБ является первым доступным свободным местом, в котором может храниться процесс A (размер 25 КБ), поскольку первые два блока не имели достаточного пространства памяти.
Best fit:-
В наиболее подходящем случае выделите наименьшее отверстие, которое достаточно велико для обработки требований. Для этого мы ищем весь список, если список не упорядочен по размеру.
Здесь, в этом примере, сначала мы просматриваем полный список и обнаруживаем, что последнее отверстие 25 КБ является наиболее подходящим отверстием для процесса A (размер 25 КБ).
В этом методе использование памяти максимально по сравнению с другими методами распределения памяти.
Worst fit:- В худшем случае выделите для обработки наибольшее доступное отверстие. Этот метод дает самое большое оставшееся отверстие.
Здесь, в этом примере, процесс A (размер 25 КБ) выделяется самому большому доступному блоку памяти, который составляет 60 КБ. Неэффективное использование памяти является серьезной проблемой в худшем случае.
Фрагментация
Фрагментация определяется как когда процесс загружается и удаляется после выполнения из памяти, он создает небольшую свободную дыру. Эти дыры не могут быть назначены новым процессам, потому что дыры не объединяются или не удовлетворяют требованиям процесса к памяти. Чтобы достичь определенной степени мультипрограммирования, мы должны уменьшить потери памяти или проблему фрагментации. В операционной системе два типа фрагментации:
Внутренняя фрагментация
Внутренняя фрагментация происходит, когда блоки памяти выделяются процессу больше, чем их запрошенный размер. Из-за этого остается некоторое неиспользуемое пространство, что создает проблему внутренней фрагментации.
Пример: предположим, что для распределения памяти используется фиксированное разделение, а размер блока в памяти различается: 3 МБ, 6 МБ и 7 МБ. Теперь приходит новый процесс p4 размером 2 МБ и требует блока памяти. Он получает блок памяти размером 3 МБ, но 1 МБ блочной памяти является пустой тратой и не может быть выделен другим процессам. Это называется внутренней фрагментацией.
Внешняя фрагментация
При внешней фрагментации у нас есть свободный блок памяти, но мы не можем назначить его процессу, потому что блоки не являются смежными.
Пример: Предположим (рассмотрим пример выше) три процесса p1, p2, p3 имеют размер 2 МБ, 4 МБ и 7 МБ соответственно. Теперь им выделяются блоки памяти размером 3 МБ, 6 МБ и 7 МБ соответственно. После выделения для процесса p1 и p2 осталось 1 МБ и 2 МБ. Предположим, что приходит новый процесс p4 и требует 3-мегабайтный блок памяти, который доступен, но мы не можем его назначить, потому что свободное пространство памяти не является непрерывным. Это называется внешней фрагментацией.
И первая, и самая подходящая системы для распределения памяти, подверженной внешней фрагментации. Для преодоления проблемы внешней фрагментации используется уплотнение. В технике уплотнения все свободное пространство памяти объединяется и образует один большой блок. Таким образом, это пространство может быть эффективно использовано другими процессами.
Другое возможное решение внешней фрагментации — позволить логическому адресному пространству процессов быть несмежным, что позволяет процессу выделять физическую память там, где последняя доступна.
Paging:
Paging — это схема управления памятью, которая устраняет необходимость непрерывного выделения физической памяти. Эта схема позволяет физическому адресному пространству процесса быть несмежным.
- Логический адрес или виртуальный адрес (представлен в битах): адрес, генерируемый ЦП.
- Логическое адресное пространство или виртуальное адресное пространство (представленное словами или байтами): набор всех логических адресов, сгенерированных программой.
- Физический адрес (представлен в битах): адрес, фактически доступный в блоке памяти.
- Физическое адресное пространство (выраженное словами или байтами): набор всех физических адресов, соответствующих логическим адресам.
- Если логический адрес = 31 бит, то логическое адресное пространство = 2 31слово = 2 G слов (1 G = 2 30 )
- Если логическое адресное пространство = 128 M слов = 2 7* 2 20 слов, то логический адрес = log 2 2 27 = 27 бит
- Если физический адрес = 22 бита, то физическое адресное пространство = 2 22слова = 4 M слов (1 M = 2 20 )
- Если физическое адресное пространство = 16 M слов = 2 4* 2 20 слов, то физический адрес = log 2 2 24 = 24 бита.
Преобразование виртуального адреса в физический выполняется блоком управления памятью (MMU), который является аппаратным устройством, и это преобразование известно как метод подкачки.
- Физическое адресное пространство концептуально разделено на несколько блоков фиксированного размера, называемых кадрами.
- Логическое адресное пространство также разделено на блоки фиксированного размера, называемые страницами.
- Размер страницы = Размер кадра
- Физический адрес = 12 бит, тогда физическое адресное пространство = 4 К слов
- Логический адрес = 13 бит, затем логическое адресное пространство = 8 К слов
- Размер страницы = размер кадра = 1 тыс. Слов (предположение)

Адрес, генерируемый ЦП, делится на
- Номер страницы (p):количество битов, необходимых для представления страниц в логическом адресном пространстве или номер страницы.
- Смещение страницы (d):количество битов, необходимых для представления определенного слова на странице или размер страницы логического адресного пространства, или номер слова страницы или смещение страницы.
Физический адрес делится на
- Номер кадра (f):количество битов, необходимых для представления кадра физического адресного пространства или кадра номера кадра.
- Смещение кадра (d):количество битов, необходимых для представления конкретного слова в кадре, или размер кадра в физическом адресном пространстве, или номер слова кадра, или смещение кадра.
Аппаратная реализация таблицы страниц может быть выполнена с использованием выделенных регистров. Но использование регистра для таблицы страниц является удовлетворительным только в том случае, если таблица страниц мала. Если таблица страниц содержит большое количество записей, мы можем использовать TLB (буфер просмотра трансляции), специальный небольшой аппаратный кеш для быстрого просмотра.
- TLB — это ассоциативная высокоскоростная память.
- Каждая запись в TLB состоит из двух частей: тега и значения.
- Когда эта память используется, то элемент сравнивается со всеми тегами одновременно. Если элемент найден, то соответствующее значение возвращается.

Время доступа к основной памяти = м
Если таблица страниц хранится в основной памяти,
Эффективное время доступа = m (для таблицы страниц) + m (для конкретной страницы в таблице страниц)
Читайте также:
- Как редактировать чужие сообщения дискорд
- 1с объект метаданных не найден по полному имени внешний отчет
- Как в excel в текст вставить значение из другой ячейки
- В графическом редакторе paint нарисовано несколько овалов некоторые из них замкнуты некоторые нет
- Как восстановить оперу после удаления на телефоне