
Браузер и сервер что это
Основное различие между веб-браузером и веб-сервером состоит в том, что веб-браузер запрашивает документ и службы и действует как интерфейс между клиентом и сервером, который отображает веб-контент. С другой стороны, веб-сервер принимает, одобряет и отвечает на запрос веб-браузера о веб-документе.
Сравнительная таблица
Определение веб-браузера
Веб-браузер можно рассматривать как утилиту, которую клиент использует для доступа к веб-сервисам и документам с сервера. Существуют различные типы браузеров, например, браузером по умолчанию для платформы Windows является Internet Explorer, аналогично браузеру по умолчанию для устройства Apple является Safari. Хотя есть и другие браузеры, такие как Google Chrome, Mozilla Firefox, Opera и UC.
Архитектура браузера:
Существует множество поставщиков, предлагающих несколько типов браузеров для коммерческих целей, основная работа которых заключается в отображении веб-документа. Все используемые вами браузеры используют практически одинаковую архитектуру.
Каждый браузер разделен на три части: контроллер, клиентская программа и интерпретаторы.
Определение веб-сервера
Веб- сервер - это программный продукт, работающий на компьютере, основной задачей которого является распространение веб-страниц пользователям в любое время, когда они этого требуют, и предоставляет область для хранения и организации страниц веб-сайта.
Машина, которая выполняет программное обеспечение веб-сервера, может быть удаленной машиной, расположенной на другой стороне вашей сети или даже на другом конце земного шара, или это может быть ваш собственный персональный компьютер дома. Мы также представили идею, что браузер пользователя является клиентом в этих отношениях.
Модель обработки веб-серверов
- Серверы на основепроцессов имеют несколько однопоточных процессов.
- Серверы на основепотоков имеют единый многопоточный процесс.
- Гибридные серверы используют несколько многопоточных процессов.
Основные различия между веб-браузером и веб-сервером
Заключение:
Давайте начнем серию статей по безопасности веб-приложений с объяснением того, что делают браузеры и как именно они это делают. Поскольку большинство ваших клиентов будут взаимодействовать с вашим веб-приложением через браузеры, необходимо понимать основы функционирования этих замечательных программ.

Chrome и lynx
Браузер — это движок рендеринга. Его работа заключается в том, чтобы загрузить веб-страницу и представить её в понятном для человека виде.
Хоть это и почти преступное упрощение, но пока это все, что нам нужно знать на данный момент.
- Пользователь вводит адрес в строке ввода браузера.
- Браузер загружает «документ» по этому URL и отображает его.
Например, lynx — это легкий текстовый браузер, работающий из командной строки. В основе lynx лежат те же самые принципы, которые вы найдете в любых других «мейнстримных» браузерах. Пользователь вводит веб-адрес (URL), браузер скачивает документ и отображает его — единственное отличие состоит в том, что lynx использует не движок графического рендеринга, а текстовый интерфейс, благодаря которому такие сайты, как Google, выглядят так:

Мы в целом имеем представление, что делает браузер, но давайте подробнее рассмотрим действия, которые эти гениальные приложения выполняют для нас.
Что делает браузер?
Короче говоря, работа браузера в основном состоит из
Разрешение DNS
Давайте разберем запрос построчно:
Воу, на этот раз довольно много информации, которую нужно переварить. Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Рендеринг
Последним по счёту, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия среднестатистического Васи.

Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Вендоры
4 самых популярных браузера принадлежат разным вендорам:
- Chrome от Google
- Firefox от Mozilla
- Сафари от Apple
- Edge от Microsoft
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF (подробнее об этом позже). Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.

Это говорит нам о двух вещах:
- Похоже, что Safari недостаточно заботится о безопасности своих пользователей (шучу: файлы cookie SameSite будут доступны в Safari 12, который, возможно, уже был выпущен к моменту прочтения этой статьи)
- исправление уязвимости в одном браузере не означает, что все ваши пользователи в безопасности
Ваша стратегия обеспечения безопасности в сети должна варьироваться в зависимости от того, какие возможности нам предоставляет вендор-поставщик браузера. В настоящее время большинство браузеров поддерживают один и тот же набор функций и редко отклоняются от своего общей дорожной карты, но случаи, подобные приведенному выше, все еще случаются, и это то, что мы должны учитывать при определении нашей стратегии безопасности.
В нашем случае, если мы решим, что будем нейтрализовывать атаки CSRF только с помощью файлов cookie SameSite, мы должны знать, что мы подвергаем риску наших пользователей Safari. И наши пользователи тоже должны это знать.
И последнее, но не менее важное: вы должны помнить, что вы можете решить, поддерживать ли версию браузера или нет: поддержка каждой версии браузера будет непрактичной (вспомните хпро Internet Explorer 6). Несмотря на это, уверенная поддержка нескольких последних версий основных браузеров — как правило, хорошее решение. Однако, если вы не планируете предоставлять защиту на какой-то определенной платформе, очень желательно, чтобы ваши пользователи об этом знали.
Совет для профи: вы никогда не должны поощрять своих пользователей использовать устаревшие браузеры или активно поддерживать их. Даже если вы приняли все необходимые меры предосторожности, другие веб-разработчики этого не сделали. Поощряйте пользователей использовать последнюю поддерживаемую версию одного из основных браузеров.
Вендор или стандартный баг?
Тот факт, что обычный пользователь обращается к нашему приложению благодаря помощи стороннего клиентского программного обеспечения (браузера), добавляет еще один уровень, усложняющий путь к удобному и безопасному просмотру веб-страниц: сам браузер может быть источником уязвимости безопасности.
Вендоры, как правило, предоставляют вознаграждения (также известные как баг-баунти) исследователям безопасности, которые могут искать уязвимость в самом браузере. Эти ошибки связаны не с вашим веб-приложением, а с тем, как браузер самостоятельно управляет безопасностью.
Например, программа поощрений Chrome позволяет исследователям безопасности обращаться к команде безопасности Chrome, чтобы сообщить об обнаруженных ими уязвимостях. Если факт наличия уязвимости подтвердится, будет выпущено исправление и, как правило, опубликовано уведомление о безопасности, а исследователь получит (обычно финансовое) вознаграждение от программы.
Такие компании, как Google, инвестируют достаточно солидный капитал в свои программы Bug Bounty, поскольку это позволяет компаниям привлекать множество исследователей, обещая им финансовую выгоду в случае обнаружения ими каких-либо проблем с тестируемым программным обеспечением.
В программе Bug Bounty выигрывают все: поставщику удается повысить безопасность своего программного обеспечения, а исследователям платят за их находки. Мы обсудим эти программы позже, так как я считаю, что инициативы Bug Bounty заслуживают отдельного раздела в ландшафте аспектов безопасности.
Джейк Арчибальд (Jake Archibald) — разработчик-"адвокат" в Google, который обнаружил уязвимость, затрагивающую несколько браузеров. Он задокументировал свои усилия по ее обнаружению, процесс обращения к различным вендорам, затронутым уязвимостью, и реакцию представителей вендоров в интересном блог-посте, который я рекомендую вам прочитать.
Браузер для разработчиков
В приведенном выше примере мы запросили документ по адресу localhost:8080/, и локальный сервер успешно на него ответил.
Примерно та же информация доступна в популярных браузерах посредством их DevTools.
В переводе двенадцатой части серии материалов о JavaScript и его экосистеме, который мы сегодня публикуем, речь пойдёт о сетевой подсистеме браузеров и об оптимизации производительности и безопасности сетевых операций. Автор материала говорит, что разница между хорошим и отличным JS-разработчиком заключается не только в уровне освоения языка, но и в том, насколько хорошо он разбирается в механизмах, не входящих в язык, но используемых им. Собственно говоря, работа с сетью — это один из таких механизмов.

Немного истории
49 лет назад была создана компьютерная сеть ARPAnet, объединяющая несколько научных учреждений. Это была одна из первых сетей с коммутацией пакетов, и первая сеть, в который была реализована модель TCP/IP. Двадцатью годами позже Тим Бернес-Ли предложил проект известный как Всемирная паутина. За годы, которые прошли с запуска ARPAnet, интернет прошёл долгий путь — от пары компьютеров, обменивающихся пакетами данных, до более чем 75 миллионов серверов, примерно 1.3 миллиарда веб-сайтов и 3.8 миллиарда пользователей.
Количество пользователей интернета в мире
В этом материале мы поговорим о том, какие механизмы используют браузеры для того, чтобы повысить производительность работы с сетью (эти механизмы скрыты в их недрах, вероятно, вы о них, работая с сетью в JS, даже и не думаете). Кроме того, мы обратим особое внимание на сетевой уровень браузеров и приведём здесь несколько рекомендаций, касающихся того, как разработчик может помочь браузеру повысить производительность сетевой подсистемы, которую задействуют веб-приложения.
Обзор
При разработке современных веб-браузеров особое внимание уделяется быстрой, эффективной и безопасной загрузке в них страниц веб-сайтов и веб-приложений. Работу браузеров обеспечивают сотни компонентов, выполняющихся на различных уровнях и решающих широкий спектр задач, среди которых — управление процессами, безопасное выполнение кода, декодирование и воспроизведение аудио и видео, взаимодействие с видеоподсистемой компьютера и многое другое. Всё это делает браузеры больше похожими на операционные системы, а не на обычные приложения.
Общая производительность браузера зависит от целого ряда компонентов, среди которых, если рассмотреть их укрупнённо, можно отметить подсистемы, решающие задачи разбора загружаемого кода, формирования макетов страниц, применения стилей, выполнения JavaScript и WebAssembly-кода. Конечно же, сюда входят и система визуализации информации, и реализованный в браузере сетевой стек.
Программисты часто думают, что узким местом браузера является именно его сетевая подсистема. Часто так и бывает, так как все ресурсы, прежде чем с ними можно будет что-то сделать, сначала должны быть загружены из сети. Для того чтобы сетевой уровень браузера был эффективным, ему нужны возможности, позволяющие играть роль чего-то большего, нежели роль простого средства для работы с сокетами. Сетевой уровень даёт нам очень простой механизм загрузки данных, но, на самом деле, за этой внешней простотой скрывается целая платформа с собственными критериями оптимизации, API и службами.
Сетевая подсистема браузера
Занимаясь веб-разработкой, мы можем не беспокоиться об отдельных TCP или UDP-пакетах, о форматировании запросов, о кэшировании, и обо всём остальном, что происходит в ходе взаимодействия браузера с сервером. Решением всех этих сложных задач занимается браузер, что даёт нам возможность сосредоточиться на разработке приложений. Однако, знание того, что происходит в недрах браузера, может помочь нам в деле создания более быстрых и безопасных программ.
Поговорим о том, как выглядит обычный сеанс взаимодействия пользователя с браузером. В целом, он состоит из следующих операций:
Жизненный цикл запроса
Весь процесс обмена данными по сети очень сложен, он представлен множеством уровней, каждый из которых может стать узким местом. Именно поэтому браузеры стремятся к тому, чтобы улучшить производительность на своей стороне, используя различные подходы. Это помогает снизить, до минимально возможных значений, воздействие особенностей сетей на производительность сайтов.
Управление сокетами
Прежде чем говорить об управлении сокетами, рассмотрим некоторые важные понятия:
На самом деле, современные браузеры не жалеют сил на раздельное управление запросами и сокетами. Сокеты организованы в пулы, которые сгруппированы по источнику. В каждом пуле применяются собственные лимиты соединений и ограничения, касающиеся безопасности. Запросы, выполняемые к источнику, ставятся в очередь, приоритизируются, а затем привязываются к конкретным сокетам в пуле. Если только сервер не закроет соединение намеренно, один и тот же сокет может быть автоматически переиспользован для выполнения многих запросов.
Очереди запросов и система управления сокетами
Так как открытие нового TCP-соединения требует определённых затрат системных ресурсов и некоторого времени, переиспользование соединений, само по себе, является отличным средством повышения производительности. По умолчанию браузер использует так называемый механизм «keepalive», который позволяет экономить время на открытии соединения к серверу при выполнении нового запроса. Вот средние показатели времени, необходимого для открытия нового TCP-соединения:
- Локальные запросы: 23 мс.
- Трансконтинентальные запросы: 120 мс.
- Интерконтинентальные запросы: 225 мс.
Как уже было сказано, всё это управляется браузером и не требует усилий со стороны программиста. Однако это не означает, что программист не может сделать ничего для того, чтобы помочь браузеру. Так, например, выбор подходящих шаблонов сетевого взаимодействия, частоты передачи данных, выбор протокола, настройка и оптимизация серверного стека, могут сыграть значительную роль в повышении общей производительности приложения.
Некоторые браузеры в деле оптимизации сетевых соединений идут ещё дальше. Например, Chrome может «самообучаться» по мере его использования, что ускоряет работу с веб-ресурсами. Он анализирует посещённые сайты и типичные шаблоны работы в интернете, что даёт ему возможность прогнозировать поведение пользователя и предпринимать какие-то меры ещё до того, как пользователь что-либо сделает. Самый простой пример — это предварительный рендеринг страницы в тот момент, когда пользователь наводит указатель мыши на ссылку. Если вам интересны внутренние механизмы оптимизации, применяемые в Chrome, вот — полезный материал на эту тему.
Сетевая безопасность и ограничения
У того, что браузеру позволено управлять отдельными сокетами, есть, помимо оптимизации производительности, ещё одна важная цель: благодаря такому подходу браузер может применять единообразный набор ограничений и правил, касающихся безопасности, при работе с недоверенными ресурсами приложений. Например, браузер не даёт прямого доступа к сокетам, так как это позволило бы любому потенциально опасному приложению выполнять произвольные соединения с любыми сетевыми системами. Браузер, кроме того, применяет ограничение на число соединений, что защищает сервер и клиент от чрезмерного использования сетевых ресурсов.
Браузер форматирует все исходящие запросы для защиты сервера от запросов, которые могут быть сформированы неправильно. Точно так же браузер относится и к ответам серверов, автоматически декодируя их и принимая меры для защиты пользователя от возможных угроз, исходящих со стороны сервера.
Процедура TLS-согласования
TLS (Transport Layer Security, протокол защиты транспортного уровня), это криптографический протокол, который обеспечивает безопасность передачи данных по компьютерным сетям. Он нашёл широкое использование во множестве областей, одна из которых — работа с веб-сайтами. Веб-сайты могут использовать TLS для защиты всех сеансов взаимодействия между серверами и веб-браузерами.
Вот как, в общих чертах, выглядит процедура TLS-рукопожатия:
Принцип одного источника
В соответствии с принципом одного источника (Same-origin policy), две страницы имеют один и тот же источник, если их протокол, порт (если задан) и хост совпадают.
Вот несколько примеров ресурсов, которые могут быть встроены в страницу с несоблюдением принципа одного источника:
Стоит отметить, что не существует единственной концепции «принципа единого источника». Вместо этого имеется набор связанных механизмов, которые применяют ограничения по доступу к DOM, по управлению куки-файлами и состоянием сессии, по работе с сетевыми ресурсами и с другими компонентами браузера.
Кэширование
Самый лучший, самый быстрый запрос — это запрос, который не ушёл в сеть, а был обработан локально. Прежде чем ставить запрос в очередь на выполнение, браузер автоматически проверяет свой кэш ресурсов, выполняет проверку найденных там ресурсов на предмет актуальности и возвращает локальные копии ресурсов в том случае, если они соответствуют определённому набору требований. Если же ресурсов в кэше нет, выполняется сетевой запрос, а полученные в ответ на него материалы, если их можно кэшировать, помещаются в кэш для последующего использования. В процессе работы с кэшем браузер выполняет следующие действия:
- Он автоматически оценивает директивы кэширования на ресурсах, с которыми ведётся работа.
- Он автоматически, при наличии такой возможности, перепроверяет ресурсы, срок кэширования которых истёк.
- Он самостоятельно управляет размером кэша и удаляет из него ненужные ресурсы.
Пример
Вот простой, но наглядный пример удобства отложенного управления состоянием сессии в браузере. Аутентифицированная сессия может совместно использоваться в нескольких вкладках или окнах браузера, и наоборот; завершение сессии в одной из вкладок приводит к тому, что сессия окажется недействительной и во всех остальных.
API и протоколы
Советы по оптимизации производительности и безопасности сетевых подсистем веб-приложений
Вот несколько советов, которые помогут вам повысить производительность и безопасность сетевых подсистем ваших веб-приложений.
- Всегда используйте в запросах заголовок «Connection: Keep-Alive». Браузеры, кстати, используют его по умолчанию. Проверьте, чтобы и сервер использовал тот же самый механизм.
- Используйте подходящие заголовки Cache-Control, Etag и Last-Modified при работе с ресурсами. Это позволит ускорить загрузку страниц при повторных обращениях к ним из того же браузера и сэкономить трафик.
- Потратьте время на настройку и оптимизацию сервера. В этой области, кстати, можно увидеть настоящие чудеса. Помните о том, что процесс подобной настройки очень сильно зависит от особенностей конкретного приложения и от типа передаваемых данных.
- Всегда используйте TLS. В особенности — если в вашем веб-приложении используются какие-либо механизмы аутентификации пользователя.
- Выясните, какие политики безопасности предоставляют браузеры, и используйте их в своих приложениях.
Итоги
Браузеры берут на себя большую часть сложных задач по управлению всем тем, что связано с сетевым взаимодействием. Однако это не значит, что разработчик может совершенно не обращать на всё это внимание. Тот, кто хотя бы в общих чертах знает о том, что происходит в недрах браузера, может вникнуть в необходимые детали и своими действиями помочь браузеру, а значит — сделать так, чтобы его веб-приложения работали быстрее.
Предыдущие части цикла статей:
Анонимность и конфиденциальность — это прекрасные понятия. Но в последнее время создается ощущение, что в сети оба понятия стили недостижимыми. Поэтому даже я, совсем не параноик периодически задумываюсь об инструментах, таких как VPN, Proxy и Tor. Вы наверняка слышали эти слова, а может быть даже регулярно пользуйтесь пользуетесь этими технологиями для сохранения анонимности, обхода блокировок, просмотра американского Netflix или банально для доступа к корпоративной сети.
Но как именно работают эти технологии и чем они отличаются? И правда ли что бесплатный сыр только в мышеловке? Сегодня поговорим о том как защитить себя и свои данные в глобально сети.
Proxy

Среди троицы — VPN, Proxy, Tor — самая простая технология — это именно Proxy. С неё и начнём.
Proxy переводится с английского, как представитель, уполномоченный, посредник. Иными словами, прокси-сервер — это сервер-посредник.
Технология работает также просто как и звучит. Представьте, что ваш трафик в сети — это чемодан. Вы хотите доставить этот чемодан по определенному адресу, но не хотели бы делать это сами, раскрывая свое местоположение и имя. Поэтому вы нанимаете посредника, который сам доставит чемодан по нужному адресу не раскрывая вашу личность и настоящий адрес. Просто и удобно. Более того такие посредники достаточно многофункциональны и пригодятся не только для банального обеспечения конфиденциальности в сети:
- Подменив свое местоположение при помощи Proxy, вы сможете обходить региональные блокировки. Например, именно прокси-серверы позволили Telegram так легко пережить несколько лет официальной блокировки.
- Или вы сможете получить доступ к контенту, доступному только в определенных странах. Например, к американской библиотеке Netflix, которая существенно более обширная, чем наша отечественная.
- Или сможете сэкономить на цене авиабилетов, воспользовавшись региональными ценовыми предложениями или скидками.
- Но может быть и обратная ситуация. Если нужно, при помощи прокси, администраторы сетей могут ограничить доступ к отдельным ресурсам.
- Есть и менее очевидные сценарии использования. Часто прокси-серверы кэшируют данные с популярных сайтов, поэтому загружая данные через прокси-сервер вы сможете ускорить доступ к этим ресурсам.
- Или сможете сэкономить трафик. Потому что прокси-серверы могут сжимать весь запрашиваемый контент. Именно так работают различные турбо- и экономные режимы в браузерах.
Типы Proxy
Во-первых, сама по себе технология очень ограниченная. Прокси-серверы узкоспециализированы, поэтому на каждый тип интернет-соединения нужен свой тип прокси-сервера.
Это серьёзное ограничение, поэтому еще есть отдельный тип прокси-серверов SOCKS-прокси.
Эта вариация протокола умеет работать с разными типами трафика. Но она работает медленнее, поэтому также подходит не для всех.
Безопасность Proxy
Но это половина беды. Все виды прокси объединяет главная, ключевая проблема — проблемы с безопасностью.
Пользоваться прокси-сервером — это всё равно что передавать данные посреднику в чемодане без пароля. Делать такое можно только в случае если 100% доверяете посреднику. И конечно же стоит остерегаться бесплатных прокси-серверов с сомнительной репутацией. Ведь воспользоваться непроверенным бесплатным прокси, это все равно, что доверить доставить мешок бесплатному курьеру по объявлению на автобусной остановке.
Как же здорово, что во время блокировки Telegram мы все дружно пользовались проверенными надежными прокси. Так ведь?
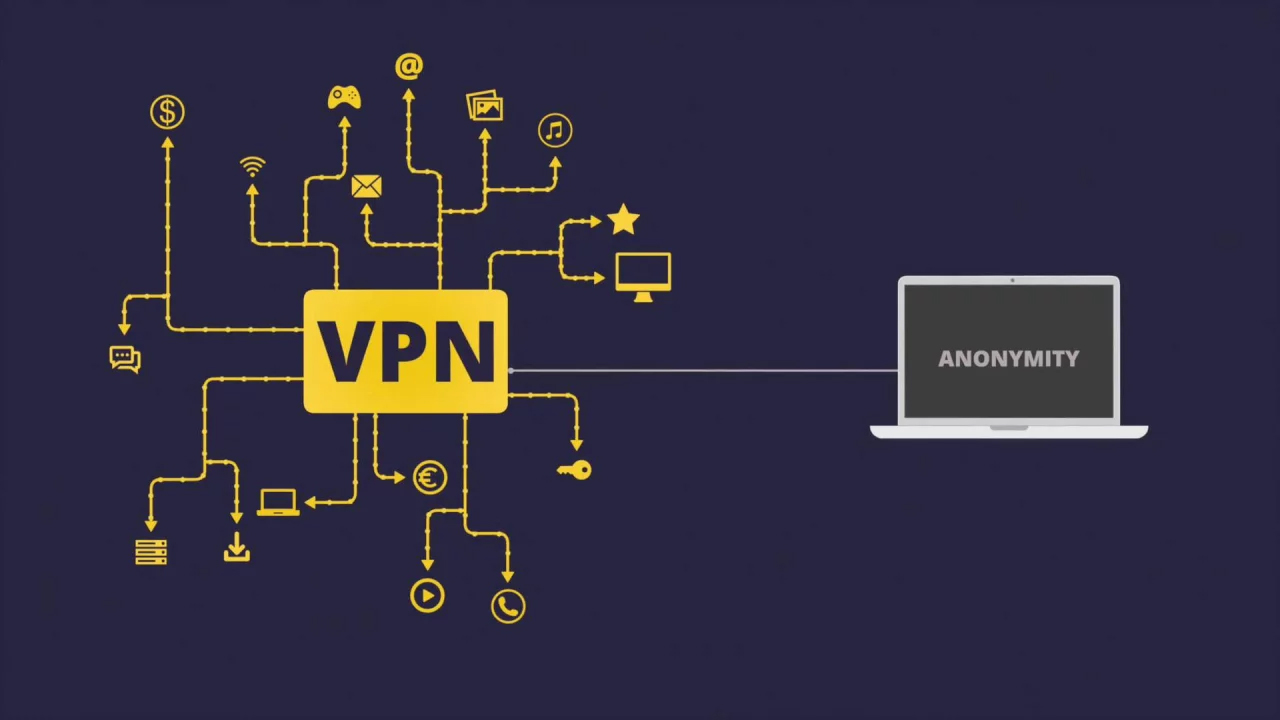
Но есть технология, которая обладает большинством достоинств прокси и лишена большинства недостатков — это VPN или Virtual Private Network — виртуальная частная сеть.
Изначально эта технология задумывалась не как средство анонимизации трафика. Ее задачей было удаленно объединять компьютеры в единую сеть. Например, для доступа к локальной сети головного офиса из регионального филиала или из дома.
Принцип работы VPN похож на прокси. Трафик точно также, прежде чем попасть в интернет, сначала попадает на промежуточный сервер. Это с одной стороны позволяет вам, например, получить доступ к заблокированным ресурсам. Потому как для интернет провайдера, вы направляете запрос на VPN сервер, а не на запрещенный сайт.
С другой стороны, это позволяет вам сохранить анонимность, так как сайт, на который вы попали думает, что запрос пришел с IP-адреса VPN-сервера, а не вашего. Но прокси-серверы, делают по сути тоже самое, так в чем же тогда разница?
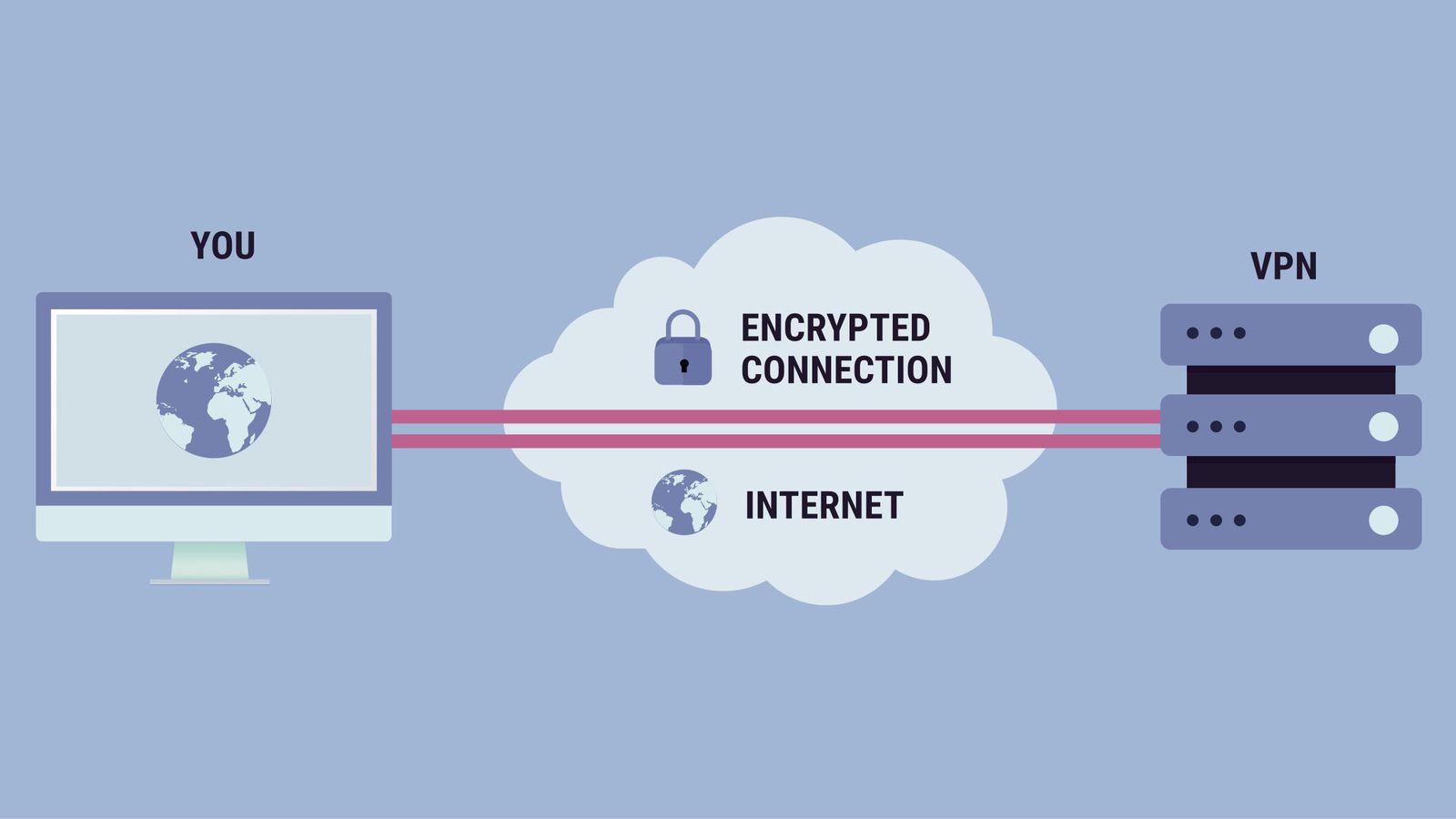
Ключевое отличие VPN от Proxy — это сквозное шифрование. Весь трафик проходящий через VPN-сервер защищен на всём пути от точки входа до точки выхода. А всё потому, что при включенном VPN между вашим устройством и VPN-сервером создается зашифрованный канал связи, который защищает все данные от хакерских атак.
Опять же если сравнивать с прокси, в первом случае мы передаем открытый чемодан с информацией посреднику, которого либо могут в любой момент обокрасть, либо он сам украдет данные. В случае VPN мы передаем данные по закрытому туннелю проникнуть в который крайне сложно. Более того VPN работает со всеми типами данных и шифрует вообще весь трафик со всех приложений, а не только трафик вашего браузера.
При этом в отличии от прокси, для работы VPN на вашем устройстве обязательно должен быть установлен VPN-клиент в виде отдельного приложения или расширения браузера.
Впрочем, поставить приложение для рядового пользователя куда проще, чем копаться в настройках прокси где-то в настройках браузера.
Бесплатные VPN-сервисы
Получается, что VPN во всем лучше прокси? Не всегда.
Дело в том, что не все VPN-сервисы одинаково полезны. Как и в случае с прокси, бесплатные VPN-сервисы не раз были пойманы в слежке за пользователями и продаже их данных.
Например, VPN-сервис Betternet, который насчитывал 38 миллионов пользователей использовал целых 14 библиотек для слежки за пользователями.
А сервис Hola продавал IP-адреса бесплатных пользователей злоумышленникам. То есть преступники могли использовать ваш IP-адрес для своих делишек.
SHADOWSOCKS

С другой стороны, не все прокси-сервисы плохие. Например, существует особый тип прокси, который называется Shadowsocks. По сути, это SOCKS-прокси на стероидах.
Тут есть и мощное шифрование, и скрытие трафика, и возможность обходить различные блокировки. Есть клиенты как для компьютера, так и для смартфона, позволяющие оставаться под защитой постоянно. А создана эта штука была нашим дружественным братским китайским народом с целью обхода великого китайского файерволла.
Отсюда и несколько приятных особенностей Shadowsocks. Например, для элегантного обхода блокировок, он умеет выборочно маскировать трафик. Вы сами выбираете что прятать, а что нет.
Например, находитесь вы в Китае и хотите проверь почту на Gmail, или свят-свят — посмотреть YouTube. Благодаря Shadowsocks, вы сможете сделать и это, и одновременно посещать сайты, доступные только из Китая.
В свою очередь, VPN-сервисы зашифровывают весь трафик, поэтому открыть сайты, доступные только в Китае, вы уже не сможете.
И, наконец, самый хардкорный способ анонимизации в сети — Tor. Что это и правда ли, что Tor такой безопасный?
Tor расшифровывается как The Onion Router и он использует так называемую луковую маршрутизацию. Твои данные — это сердцевина луковицы, а их защита — слои вокруг. Что это значит?
Для анонимизации Tor, также как прокси и VPN, пропускает трафик через промежуточные серверы. Но Только в случае с Tor их не один, а три, и называется они узлами.

А вот теперь смотрите, ваш трафик проходит через три узла:
- входной или сторожевой,
- промежуточный,
- выходной.
Во-первых, чтобы скрыть ваш IP-адрес. Каждый узел знает IP-адрес только узла, который стоит в цепочке перед. Поэтому пока ваш трафик дойдет до третьего узла, исходный IP потеяется.
Во-вторых, ваш трафик обернут в три слоя защиты. Поэтому первый и второй узел не видят вашего трафика, они только снимают слои защиты как, как кожуру с луковицы, а вот достает сердцевину и отправляет запрос в интернет только третий выходной узел.
Эти узлы разворачивают сами пользователи сети на своих компах. Чем больше пользователей, тем безопасней и тем быстрее работает сеть.
А доступ к сети осуществляется через специальный браузер Tor Browser, основанный на Firefox. Его улучшили дополнениями, запрещающими сайтам следить за тобой. Например браузер умеет отличать все скрипты на сайтах, фактически запрещая собирать любые данные пользователя, или заставляет сайты принудительно использовать шифрование. Звучит очень безопасно, но на практике, это не так.
Во-первых, Tor очень не любят правоохранительные органы, а сам факт использования Tor легко отследить. Поэтому, просто используя Tor Browser, вы уже можете привлечь лишнее внимание. Иными словами лучше использовать Tor в связке с VPN.
Во-вторых, владельцы выходных узлов очень рискуют. Ведь именно они несут ответственность за все действия, которые совершают пользователи сети.
В-третьих, те же владельцы выходных узлов видят весь ваш трафик, а значит они могут отследить вас по косвенным признакам. Именно поэтому выходные узлы больше всего любят создавать сотрудники правоохранительных органов.
Более того, из-за многослойного шифрования сеть Tor работает очень медленно, половина сайтов прост отказывается корректно работать через Tor Browser.
Итоги

Что в сухом остатке? Если вы беспокоитесь за свою безопасность в сети, то самым оптимальным способом защиты будет VPN. Но не забывайте, что использовать надо только надежные VPN-сервисы с хорошей репутацией. Часто информацию о надёжности того или иного сервиса можно найти в интернете, в специальных статьях. Также помните, что хороший VPN может стоить денег, вернее его создатели могут брать за его использования какую-либо сумму. Ведь бесплатный сыр бывает только в мышеловке.

Естественно, что все эти слова имеют прямое отношение к интернету, но что они конкретно означают в двух словах не скажешь. Как мне кажется, лучше начать по порядку, чтобы в голове не образовывался сумбур. Не бойтесь, «много букв» не будет, но каждому термину все равно придется посвятить пару абзацев. А как вы думали? Высокие технологии — это дело такое.
Что такое веб и онлайн? Чем отличается Web 2.0 от 1.0?
Очень часто слово «веб» используют еще и вместо слова «онлайн» (только сейчас, начиная писать эту заметку, поймал себя на этой мысли). Люди добавляют к своем запросу слово веб или онлайн имея в виду, что хотят найти что-то доступное через браузер (например, пишут «ватсап веб» или «вибер онлайн»).
Т.е." Web" и «онлайн» по сути тут выступают некими синонимами и означают возможность получения чего-либо через активное интернет-подключение. Почитать книгу онлайн, посмотреть фильм, послушать музыку через веб, пообщаться или поиграть через сеть — это все характеризуется словами «веб» или «онлайн». Кстати, сейчас люди все меньше покупают персональных компьютеров, но все больше мобильных гаджетов, основным преимуществом которых является постоянное подключение к сети.
Да и вообще, люди все меньше используют стационарные программы и все больше веб-приложения (онлайн-сервисы) с аналогичными характеристиками. Например, я уже писал про бесплатный онлайн аналог фотошопа, про онлайн html редакторы и прочие полезные онлайн-сервисы. А ведь когда-то этого не было. Даже трудно представить как жили люди до того, как появился интернет.
Так что же такое веб? По сути, это и есть интернет, сеть, глобальная паутина WWW и все то, о чем я уже писал в приведенной по ссылке статье. Получается, что это совокупность миллионов веб-сайтов, которые расположены на веб-серверах (аналогов обычных компьютеров, но с уклоном под выполнение определенных задач — нет монитора, много оперативной памяти и места на жестких дисках). Работают сервера в режиме 24 на 7 и доступны из любой точки мира благодаря связи через сеть интернет.
Но WEB (то, что мы называем сейчас WWW) появился значительно позже самого интернета (физической возможности соединения компьютеров в сеть). Только в конце восьмидесятых Тим Бернерс-Ли придумал и создал все необходимые для этого инструменты, а через несколько лет появился первый графический веб-браузер. Вот именно с середины девяностых и можно начинать отсчет эры всемирного веба — онлайн взаимодействия миллионов компьютеров пользователей и веб-серверов.
Принято считать, что тогда была эра так называемого «Веб 1.0», когда властвовали простенькие статичные веб-сайты (что это такое?) без всяких намеков на интерактивность. Последнее же (интерактивность — это контент формируемый посетителями) позволяли в какой-то мере реализовать лишь форумы, гостевые доски и чаты.
Причем все это было сделано довольно топорно (вычурные цвета, фон в виде текстуры), убого (помните информеры погоды или валюты чуть ли не на всех сайтах), версталось таблицами без использования CSS и Джава-скрипта.

С другой стороны все недостатки WEB 1.0 были обусловлены низкой скоростью интернет-каналов, которыми в то время обладали веб-пользователи (чаще всего это был диал-ап, со скорость загрузки в 5 мегабайт в час!). Современные навороченные сайты на таких скоростях интернета грузились бы по полчаса, а возможности браузеров и ПК того времени просто не позволили бы отобразить большую часть их функционала. В общем, все соответствовало своему времени и техническим возможностям.
Со временем веб-обозреватели (браузеры) совершенствовались, повышалась скорость интернет каналов (росла доля широкополосных подключений) и веб 1.0 начал потихоньку трансформироваться в WEB 2.0. Кроме этого, Веб 2.0 характеризуется еще и тем, что теперь очень большая часть контента сети создается самими пользователями, а не вебмастерами (владельцами сайтов).
Знаковым событием в этом плане стало появление и массовое распространение социальных сетей, блог-платформ типа Лайфджорнал, Википедии и других вики-проектов. Интерактивность веба теперь возведена во главу угла. Оборотной стороной медали стало то, что данные пользователей, которые они оставляют о себе при регистрации, могут быть похищены.
При этом остро встает вопрос кибербезопасности и конфиденциальность сети. С одной стороны, Веб 2.0 прост и удобен (уютен и понятен, ибо люди живут внутри привычного интерфейса любимой соцсети), но с другой стороны, вы сообщаете там о себе массу данных, что может в конце концов выйти боком.
Веб-поиск
Как вы понимаете, при текущих размерах веба одной из самых насущных проблем является поиск нужной информации. Это как миллиарды страниц разных книг раскиданных по всему миру, и среди них очень сложно будет отыскать что-то действительно ценное и интересное вам в данный момент, если не будет реализована возможность полноценного поиска.
На начальной стадии существования WEB-а достаточно было собрать самые актуальные веб-сайты в тематический каталог и вуаля — все под рукой. Сейчас же такой фокус не прокатит, хотя каталоги существуют и до сих пор (Яндекс каталог, дмоз, рамблер топ 100, яху и др.).
Оптимальным решением являются поисковые машины. Принцип работы поисковиков довольно прост — они сканируют все сайты интернета, изучают содержимое всех их веб-страниц и выдают в ответ на запрос пользователя веб-поиска наиболее подходящий ответ (в виде списка наиболее подходящих страниц, отсортированного по степени их релевантности запросу).
Однако, то что просто на словах, на деле осуществить очень сложно. Вы представьте только, сколько нужно задействовать веб-серверов, чтобы хранить на них копию всего интернета? А ведь эти данные еще нужно обработать и выдавать ответы на вопросы в реальном времени. Не даром самым крупным сборщиком компьютеров является компания, которая их не продает. Догадываетесь какая? Гугл, конечно же. Они все эти компьютеры (сервера) используют для реализации возможности веб-поиска. О, как!
Кстати, история становления Google весьма любопытна, равно как и история развития Яндекса (отечественного лидера поиска в рунете). Именно эти системы веб-поиска являются основными на нашем рынке. Конечно же, они несут такие расходы на обслуживание веб-серверов (миллионов компьютеров) и платят зарплату тысячам своих сотрудников не безвозмездно. Все окупается благодаря размещению в поисковой выдаче контекстной рекламы.

Это огромные деньги, и они позволяют нам с вами осуществлять веб-поиск бесплатно, пусть и с просмотром рекламы.
По поисковым системам мира и рунета у меня имеется отдельная статья, которую вы найдете по приведенной ссылке, посему не буду сильно акцентироваться на этом вопросе, а лишь приведу их список:
-
— самый популярный поисковик в рунете (русскоязычном сегменте веба) — мировой лидер поиска, но в России занимает пока лишь вторую позицию после Яндекса
- Поиск Майл.ру — серьезно уступает первым двум игрокам, но довольно часто этот веб-поиск используется посетителями сервисов, принадлежащих группе Майл.ру (одноклассники, мой мир, почта, игры и т.п.) — веб-поиск от Микрософт. У нас практически никем не используется
Веб-браузеры
Как я уже упоминал выше, именно с момента появления первого графического браузера (назывался он Мозаик и было это в далеком 1993 году) можно вести отчет веба. Раньше же это был просто интернет для узкого круга знающих людей, но после появления первого web-браузера «для людей» всемирная сеть WWW стала бешеными темпами набирать популярность.
Так что же такое браузер? Ну, это просто софтинка (программа), которая интерпретирует код гипертекстовой разметки сайтов в красивую картинку, где все блоки текста и графики размещены по своим местам и вам будет удобно всем этим добром пользоваться.

С появлением Веб 2.0 браузеры стали поддерживать такие технологии как Флеш (проигрывание видео с помощью Адобе Флеш Плеера и создание красивой навигации), Аякс (подгрузка информации на веб-страницу без ее обновления), джава скрипт (скрипты выполняемые на стороне пользователя, т.е. в браузере) и многое другое. Все это повысило интерактивность сайтов и веб-пользователям стало интересно «жить в сети».
На данный момент можно выделить несколько web-браузеров, которые пользуются наибольшей популярностью (как на стационарных компьютерах, так и на мобильных устройствах):
-
— «выскочка», который за несколько лет своего существования стал самым популярным веб-обозревателем на планете земля. В свое время я написал небольшую обзорную статью по браузере Гугла и расширениям для браузера от Гугла. — веб-браузер, который можно считать наследником того самого Мозаика, который стал причиной такой популярности Web-а. Развивается очень давно, но уступил пальму первенства детищу Гугла. Раньше главной фишкой было наличие огромного количества расширений для Фаерфокса, но сейчас все конкуренты имеют подобную возможность и полный набор нужных плагинов. С особенностями этого обозревателя вы можете бегло ознакомиться в моей статье о Firefox. — когда-то это был культовый web-браузер в рунете (платный, но доступный). Однако, несколько лет назад разработчики перестали поддерживать оригинальный движок и перешли на тот движок, что использует Гугл Хром (хромиум). Собственно, все расширения теперь от Хрома подходят и новой Опере, но лично я по-прежнему пользуюсь старушкой Опера 12, хотя многие сайты в этом браузере уже коряво отображаются. Но привычка — вторая натура.
- Яндекс Браузер — еще одна поделка на движке Хромиума, но со своими изюминками (безопасность и т.п.). Подробнее можете почитать в моей статьей про Яндекс web-браузер. Расширения к нему, естественно, подойдут и от Хрома, равно как и темы оформления.
Веб-сайты, страницы и web-сервера
В эпоху WEB 1.0 сайты были статическими, т.е. каждая вебстраница представляла из себя отдельный физический файлик, лежащий в директории сайта на веб-сервере хостинга (по сути, это компьютер подключенный к сети в режиме 24 на 7). Чтобы изменить содержимое страниц, этот файлик нужно было открыть на редактирование и потом сохранить в обновленном виде. Если у веб-сайта было сто страниц, то и файликов хранилось на хостинге столько же, а то и больше.
В эпоху WEB 2.0 все стало проще и сложнее одновременно. Появились так называемые системы управления контентом (CMS или другими словами — движки). В них веб-страницы уже не хранятся на хостинге в виде файлов, а формируются движком на лету путем подставления в нужные места шаблона (графического оформления веб-сайта) нужных фрагментов текста, которые хранятся в базах данных.
И файлы движка, и таблицы баз данных опять же хранятся и подгружаются по запросу пользователя сайта с веб-сервера, расположенного у хостера (даже сейчас есть варианты бесплатного хостинга с поддержкой php и баз данных, где можно размещать сайты на движках без оплаты и без рекламы).
Причем веб-сервер не всегда представляет из себя целый компьютер, выделенный в ваше полное распоряжение (это так называемый выделенный web-сервер). Чаще всего вы получаете в свое распоряжение (как на платном хостинге, так и на бесплатном) лишь его часть (часть жесткого диска, часть оперативной памяти и часть процессорного времени). Поэтому веб-сервером чаще называют именно программную среду, которая позволяет функционировать вашему веб-сайту.
Поднять веб-сервер можно даже на своем собственно домашнем ПК (в этом вам помогут программы локального сервера Денвер и локального web-сервера Опенсервер). Это позволит вам работать над созданием веб-сайтов без предоставления к ним доступа из интернета. А когда все отладите и настроите, можно будет уже перенести web-проект на реальный сервер, расположенный на платном или бесплатном хостинге.
Ну вот, где-то так получается. Если что не понятно, то спрашивайте — постараюсь ответить.
Эта статья относится к рубрикам:
Комментарии и отзывы (2)
Сейчас интернет кардинально изменился, помню, каким он был в девяностые годы, тогда ещё модемом подключались через телефонную линию, столько полезной информации в интернете тогда ещё не было.
В ответ на пост Антона.
Да, Вы правы. И действительно Яндекс уже стал порталов, откуда не так часто переходят на другие сайты. Это печалит веб-мастеров, ибо снижает посещаемость их сайтов и, следовательно, желание их совершенствовать и расширять. Если на найдут какого-то компромиссного решения, то интернет изменится еще сильнее (и не в лучшую сторону).
Читайте также: