Bdd тестирование 1с это
BDD for 1S:Enterprise (snipets generator and runner)
Порядок установки под Windows
-
- для работы с иходными файлами 1С с помощью проекта precommit1C - утилита должна быть доступной в переменной Path окружения Windows
Клонируйте данный репозиторий с помощью ms-git
Описание простого использования
- пишем feature файлы в формате Gherkin (обычно используется редактор Notepad++ или связанный проект vanessa-bdd-editor
Классический вариант использования (без интерактивного режима)
Фактически классический вариант использования представляет собой следующий рутинный порядок
- зафиксировали требования к информационной системе
- создали автоматизированные сценарии проверки в виде epf файлов
- наполнили шаги сценариев (сниппеты) кодом проверки поведения
- запустили сценарии проверки поведения и убедились, что они НЕ работают
- разработали функционал
- запустили сценарии проверки поведения
- убедились что сценарии проверки работают и отчет о проверки показывает "Зелёный" статус
Использования в режиме проверки поведения пользовательского интерфейса
для команд уже имеющих функционал, или производящих доработку типовых конфигураций в режиме Taxi действует упрощенный порядок использования
- зафиксировали требования к информационной системе
- создали автоматизированные сценарии проверки в виде epf файлов
- разработали управляемые формы или рабочие столы конфигурации в режиме прототипирования
- запустили запись интерактивных действий пользователя в режиме менеджера тестирования
- получившимся кодом наполнили обработки проверки поведения
- дополнили код проверки, кодом проверки данных если это необходимо
- разработали основной функционал
- запустили сценарии проверки поведения
- убедились что сценарии проверки работают и отчет о проверки показывает "Зелёный" статус
Кто пишет feature файлы ?
Обратите внимание, что фактически feature файлы могут писать все участники команды:
- менеджер проекта - если обнаружил что заказчику необходимо новое поведение
- бизнес или системный аналитик - на основе собранных требований и технических заданий
- ведущий разработки - если обнаружил, что требования недостаточно структурированы
- архитектор или эксперт 1С - если текущие сценарии некорректно спроектированы с точки зрения метаданных
Для редактирования feature файлов используется проект По автоматизации сбора требований - на текущий момент имеет статус pre-alpha
Если вы не уверены в правильности ожидаемого поведения, используйте для этого системы тэгов, как то:
- "@Draft@" - черновик требования
- "@Предварительно" - начальные заметки
и подобные им обозначения
Файл профиля запуска обработки
Для запуска в консольном режиме используется понятие профиль консольного запуска. Профиль консольного запуска предназначен для удобной передачи параметров. Профиль запуска представляет собой текстовый файл в формате JSON.
Текущие параметры запуска:
- Каталог фич - каталог где собраны требования заказчика описанные на языке Gherkin
- ВыполнитьСценарии - признак того, что необходимо запустить выполнение сценариев
- ДелатьОтчетВФорматеАллюр - признак того, что необходимо формировать HTML отчёт о результатах проверки
- КаталогOutputAllureБазовый - адрес каталога для где будет формироваться HTML отчёт
- ЗавершитьРаботуСистемы - признак того, что окончанию работы необходимо завершить работу 1С предприятия
- ВыгружатьСтатусВыполненияСценариевВФайл - признак, что необходимо формировать файл с финальным статусом проверки
- ПутьКФайлуДляВыгрузкиСтатуасВыполненияСценариев - по данному пути будет сформирован файл со статусом проверки (обычно используется на серверах сборки для автоматизированного указания статуса сборки)
- СписокТеговИсключение - массив текстовых тэгов, для исключения из проверки (используется например для черновиков сценариев и требований)
Пример подобного JSON файла профиля:
Профиль запуска предназначен для простого консольного запуска, пример подобной командной строки выглядит так:
Заметки для желающих поучаствовать в доработке
- мы используем подход git-flow для реализации функциональности
- мы используем precommit1c для фиксации исходников Epf обработки в git
- мы используем принцип самопроверки через feature файлы, поэтому перед разработкой новой функциональности мы также - разрабатываем feature файлы, генерируем шаблоны сценариев и наполняем их кодом для проверки. Поэтому к доработкам без feature файлов мы относимся "холодно".
- основная лицензия продукта - BSD v3
- лицензии стороннего кода - Apache License, Freeware, etc
платная подддержка содержит в себе
- обучение навыкам работы с BDD при разработке на 1С
- обучение навыкам написания на языке Gherkin
- обучение навыкам написания сценариев проверки поведения
Я расскажу вам про магию BDD. Сначала будет немного теории, а потом я покажу, как это применимо к 1С на практике. BDD расшифровывается как Behavior Driven Development, разработка через поведение системы. Это означает, что мы выстраиваем весь наш процесс разработки, исходя из ожидаемого поведения.
Проблемы коммуникации между бизнесом и IT

В первую очередь давайте обозначим те проблемы, которые мы можем решить с помощью BDD, а потом перейдем к практике того, как их нужно решать.
Итак, давайте поговорим про взаимоотношения бизнеса и IT.
Первая проблема, которая очевидная всем это то, что мы с бизнесом говорим на разных языках.
Это известная проблема, что бизнес мыслит и говорит в одних терминах, а IT мыслит и говорит в других. Мы технари - они бизнесмены. Все вы прекрасно знаете, как бывает трудно понять заказчика. Иногда даже приходит мысль, что для понимания друг друга, нам нужен другой, общий язык. Что-то типа эсперанто, только для бизнеса и IT.
Методика BDD разрешает эту проблему.

Вторая проблема, это то, что бизнес никогда не знает, полностью ли соответствует ли написанное ПО его требованиям, или нет.
Да, пусть мы с бизнесом согласовали требования к будущей системе. Но вы прекрасно знаете, что в современном динамичном мире, требования постоянно уточняются, дополняются. У бизнеса появляются новые идеи, а IT приходится вновь и вновь перекраивать систему. Если ПО разрабатывается большое и сложное, то в полный рост встаёт проблема, а как понять, эта программа сейчас делает именно то, что нужно бизнесу? Как IT продемонстрировать результат своей работы, чтобы заказчик был уверен, что он получит то, что хочет.
Эту задачу мы тоже можем решить с помощью BDD.

Следующая проблема заключается в том, что в процессе разработки каждый последующий цикл становится все дольше и дольше, а значит, дороже и дороже.
Эта проблема тесно связана с предыдущей. Когда бизнес постоянно растёт и изменяется - вмести с ним изменяются и требования к ПО. Это все понимают. Со стороны IT это проявляется, как постоянная доработка, переделывание, рефакторинг уже существующих подсистем.
Как защитить уже работающий функционал? Как проверить, что при суровом рефакторинге, мы ничего не сломали? Даже какая-нибудь простая задача, например, разделить функционал одного документа на два, может вылиться в чистый хаос, ведь надо убедится, что все связанные части системы, такие как регистры, отчетность - не поплыли из-за этих изменений.
Эту проблему мы тоже можем решить с помощью BDD.
Что предлагает BDD для того, чтобы решить эти проблемы теоретически?

Давайте обозначим, как все это будет происходить:
- Проблема коммуникации с заказчиком (то, что мы с ним говорим на разных языках) в BDD решается с помощью специального «объединяющего языка», который называется Gherkin. На нем описываются требования, которые понятны и бизнесу, и IT.
- Проблема того, что бизнес не знает, до конца ли соответствует ПО его требованиям, может быть решена, если мы дадим заказчику в руки инструмент, позволяющий по нажатию одной кнопки посмотреть, как в его системе в данный момент работает интересующая его функциональность.
- А что касается того, что каждый новый цикл разработки становится все дольше и дольше – для этого существуют практикиContinuesIntegration иContinuesDelivery.
Процесс разработки по методике BDD
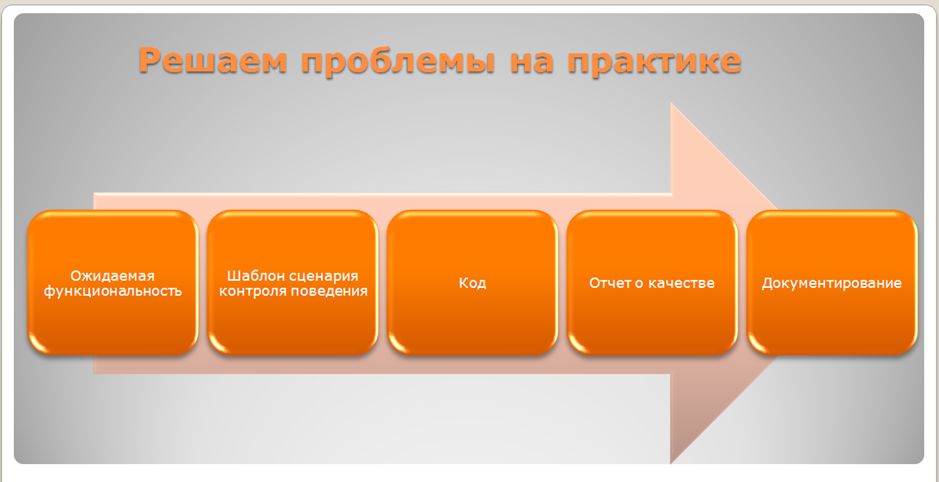
Методика BDD позволяет нам по-новому рассмотреть процесс разработки. Кубики, из которых строится эта методика, остаются все теми же. Но BDD позволяет взглянуть на них по-новому:
- Мы пишем требования – это очевидно, мы же должны как-то писать требования. Но они пишутся на определенном языке.
- Потом магическим образом, по одной кнопке из требований мы получаем сценарии тестирования.
- Потом мы пишем код – извините, но код писать все равно придется.
- А дальше мы по одному нажатию мыши получаем отчет о качестве в разных форматах.
- И параллельно с этим происходит документирование. С точки зрения BDD документация – это тоже код. Но это уже космос, мы сейчас об этом говорить не будем.
Описание требований в BDD

Теперь перейдем к практике.
Если вы будете гуглить BDD в интернете, то найдете примеры типа: «как сложить 2+2», или «как умножить два числа» и т.д. А я вам приведу конкретный пример для типовой бухгалтерии – «Зачет аванса».
Итак, мы уже говорили, что в BDD требования пишутся на определенном языке, который называется Gherkin. Этот язык еще называют Given When Then – это английская терминология.
Как это работает? Мы описываем наши требования с помощью простых конструкций на простом декларативном языке, который имеет всего несколько ключевых слов.
Давайте рассмотрим конкретный пример – «Зачет аванса».
- Итак, на самом верху, в начале текста у нас содержится ключевое слово «Функционал». Здесь мы в свободной форме описываем, что нам нужно. Например:
- Функционал: Распределение поступающей оплаты по документам реализации и зачет аванса контрагента.
- Как бухгалтер (это действие будет делать бухгалтер), я хочу, чтобы при фиксации оплаты от контрагента происходил зачет аванса для того, чтобы получить корректные проводки.
- Допустим, есть контрагент, имеющий долг 900 рублей, когда по нему фиксируется оплата на 2000 рублей, тогда на 62 счете формируется две проводки.
Так выглядит реальный кейс, реальный пример для типовой конфигурации.
Соответственно, я хотел бы обратить внимание, что данный текст, как сценарий работы, понятен как IT-специалистам, так и бизнес-пользователям – здесь ничего особенного для них нет.
Генерация сценариев поведения из текстов требований
![]()
Идем дальше. Мы говорили, что у нас по одной кнопке будут генерироваться сценарии тестирования. Для этого мы будем использовать инструмент Vanessa-behavior. О нем чуть подробнее:
- Это инструмент из семействаVanessaStack.
- Это опенсорс-продукт, в разработке и доработке которого может принять участие любой из вас.
- Он free for commercial use (бесплатный для использования).
- По сути, это – генератор сценариев тестирования и «запускалка» (так называемый feature-плейер): мы загружаем в него свои требования, нажимаем на кнопку, и они начинают у нас магически воспроизводиться.
![]()
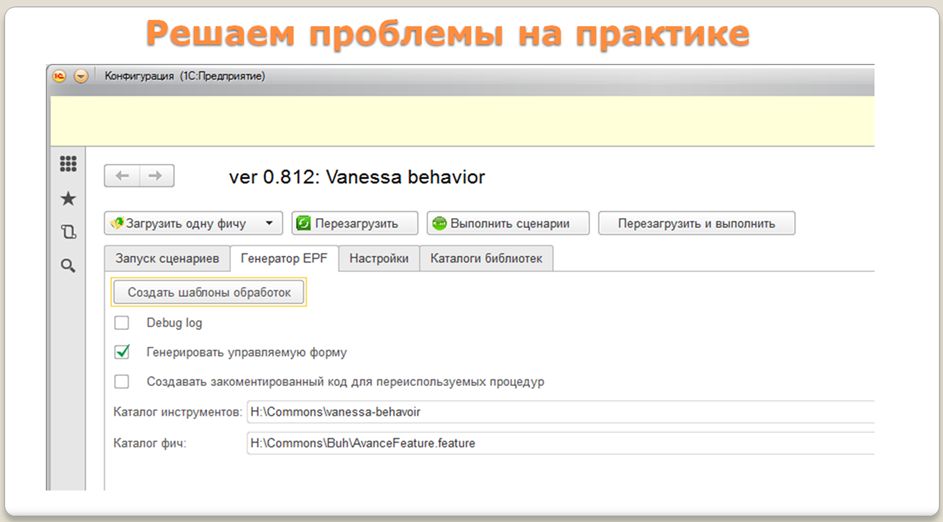
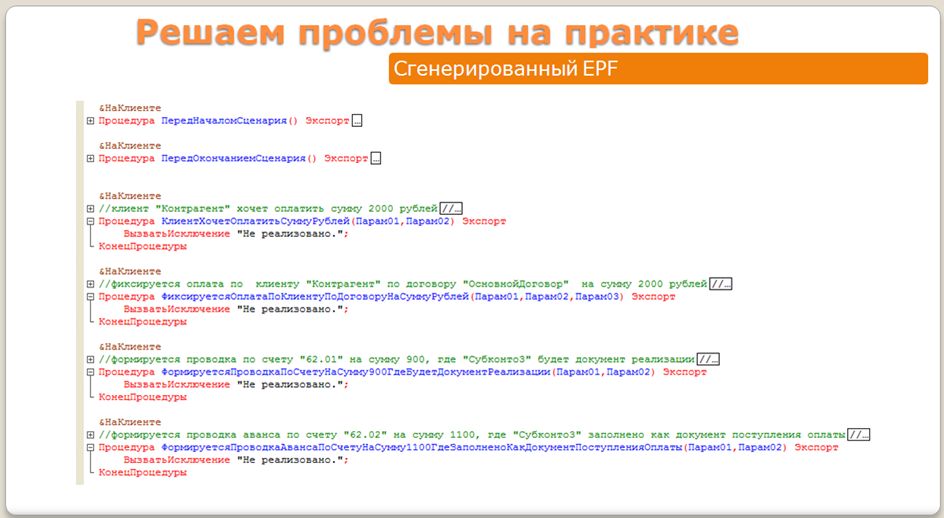
Давайте посмотрим на код, который получился в результате обработки нашего требования (того самого кейса с зачетом аванса).
Каждый описанный шаг нашей «фичи» превратился в процедуру, которая по умолчанию содержит в себе код:
ВызватьИсключение"Не реализовано"
Так сделано специально, потому каждый шаг в BDD – это аналог теста из TDD. И у каждого шага может быть три состояния:«Выполнено», «Не выполнено» и «В ожидании реализации».Таким образом, мы в BDD всегда знаем, какой процент требований у нас сейчас реализован, поскольку мы всегда получаем отчет о том, приступал ли вообще программист к реализации конкретного требования или нет.
Обратите внимание на то, что генерируется именно epf-файл – не просто код, а готовая epf-обработка, которую мы сразу можем загрузить в конфигуратор, чтобы там с ней дальше работать.
Автоматическое воспроизведение шагов сценария поведения
![]()
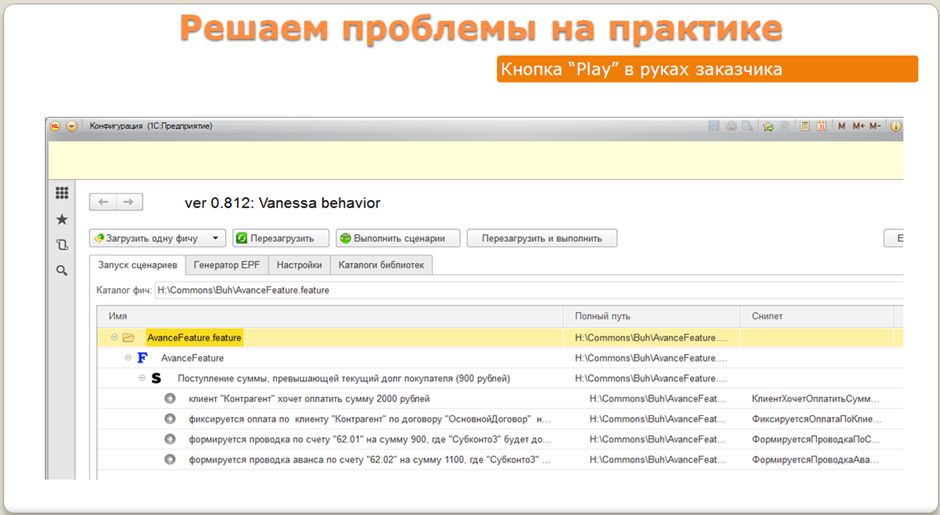
Мы говорили о том, что дадим заказчику «волшебную кнопку», с помощью которой он сможет проверить реализованную функциональность. В нашем инструменте Vanessa Behavior есть такая кнопка – она называется «Выполнить сценарии».
С ее помощью IT-специалисты могут производить демонстрацию функциональности заказчику: они загружают фичу в feature-плеер, нажимают кнопку, и начинают появляться окошки, где автоматически вводятся данные, проводятся документы и пр. Вообще говоря, бизнес-заказчик может провести это демо и сам для себя, он может загрузить фичу, нажать кнопку и также убедиться, что все работает. Например, вы можете ему прислать свои изменения и попросить: «Проверьте, пожалуйста», - «Хорошо, проверяю». Это может работать и так.
Использование готовых шагов сценария из каталога библиотек
![]()
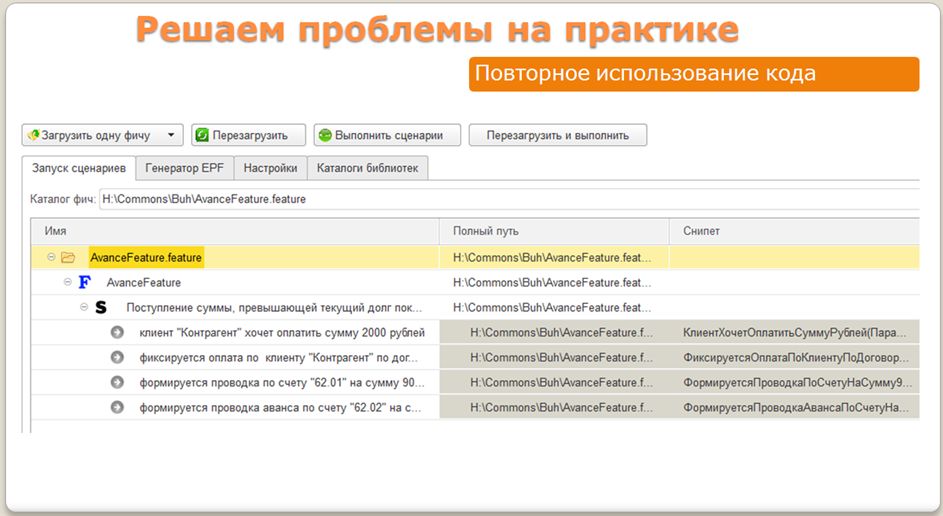
В BDD является нормой такой термин, как «повторное использование кода». Что это такое?
Представьте себе: мы описываем шаги сценария для нашей «фичи», генерируем по ним epf-обработку, загружаем ее в feature-плеер и видим, что часть из этих шагов сразу закрасилась в серый цвет – это означает, что такой шаг уже реализован в одной из библиотек. Обратите внимание, мы с вами просто написали сценарий, даже еще ничего не программировали,просто в блокноте написали, а этот сценарий уже сразу может работать – будут исполняться его шаги, проводиться документы и т.д.
В BDD это является нормой. Это связано с тем, что происходит переиспользование готовых шагов, которые кто-то до нас уже реализовал.
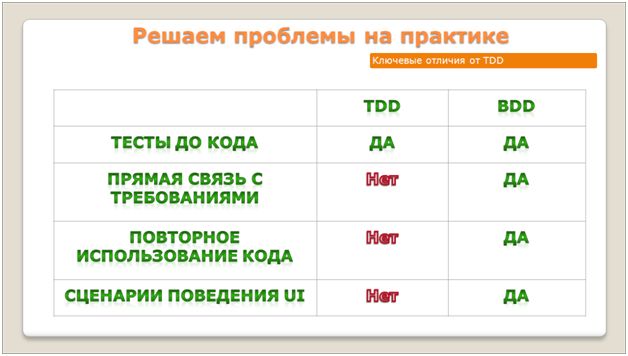
Отличия BDD и TDD
![]()
Методика BDD выросла как развитие подхода TDD (разработка через тестирование). Как это получилось? Люди при внедрении разработки через тестирование в различных системах столкнулись с определенными проблемами. Соответственно, как ответ на эти проблемы – Ден Норт сформулировал подход BDD.
Я хотел бы подчеркнуть ключевые отличия – почему для 1С BDD подходит лучше, чем TDD. Смотрите:
- И там, и там сценарии тестирования пишутся до кода. В TDD это происходит нативно, он так устроен, а BDD – это продолжение TDD, работает точно так же.
- Прямая связь с требованиями. Здесь я имею в виду, что мы по одной кнопке получаем сценарий тестирования. В TDD такого нет. В BDD это есть.
- Повторное использование кода – нативно в TDD этого нет. Там вы должны постоянно думать о том, как избежать дублирования в тестах, придумывать для этого какие-то общие модулии т.д. В BDD это работает само собой.
- Сценарии поведенияUI. Тот, кто внедрял TDD, понимает, что писать UI-тесты для 1С на чистом TDD очень сложно. Это низкоуровневая методика, она немного не для этого. Низкоуровневые тесты для 1С – очень редкая задача: мы не пишем dll в 1С, мы автоматизируем бизнес, описываем поведение системы. Заказчик хочет получить не процедуру в модуле, а чтобы система вела себя определенным образом. Соответственно, BDD – это разработка через поведение системы. Поэтому оно на 1С так хорошо и ложится.
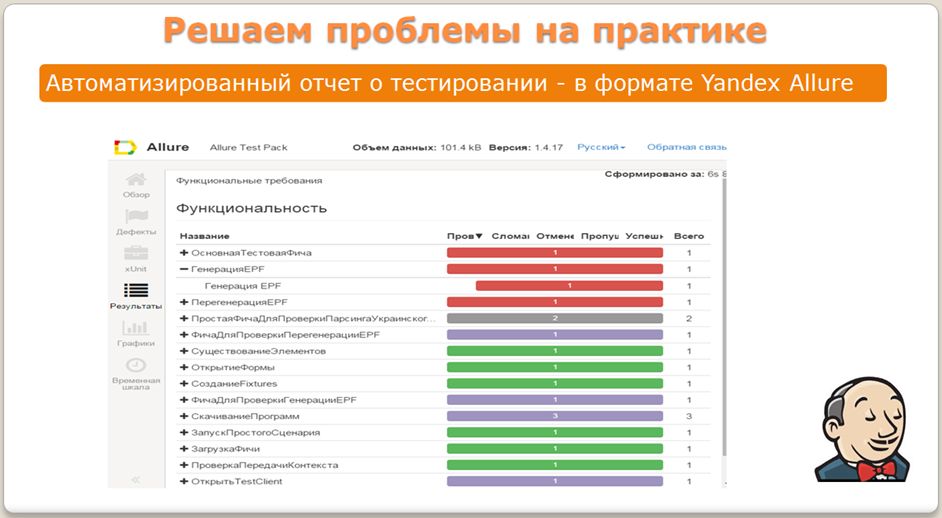
Автоматизированный отчет о тестировании в формате Yandex Allure
![]()
Мы говорили, что можно по нажатию одной кнопки получить отчет о качестве. Для этого нам понадобится билд-сервер (он же CI-сервер, Continues Integration сервер). Им может быть, например, Jenkins. Почему Jenkins? Потому что он бесплатный, вы можете его кластеризовать и масштабировать как захотите. Например, можете настроить его так, чтобы после каждого изменения в хранилище он выгружал вашу конфигурацию в отдельную базу и прогонял на ней тесты. Скажем, ваш программист поместил изменения в хранилище, Jenkins их себе затянул, поднял базу, запустил все сценарии на выполнение и выдал вам отчет на email.
Здесь на скриншоте как раз можно увидеть отчет для Jenkins в формате Yandex Allure. Спасибо ребятам из Яндекса, которые его разрабатывают. Его функционал также доступен в виде плагина для Jenkins. Соответственно, для того, чтобы получить такой отчет из Jenkins, вам надо всего лишь сделать пару кликов мышкой.
Окупается ли разработка через тестирование
Очень часто задают вопрос: окупается ли разработка через тестирование? Как могут вернуться затраты, которые мы понесем на обучение команды, на софт, железо?
Давайте посчитаем, что нужно для того, чтобы запустить BDD:
- Jenkins – бесплатный.
- Vanessa Behavior – бесплатный.
- Отчет Yandex Allure – бесплатный.
- Безусловно, нам нужно «железо», но дело в том, что для работы билд-сервера хватает компьютера уровня обычной рабочей станции пользователя. Можно даже несколько таких станций поставить, кластеризовать, и у вас получится кластер Jenkins – с мастер-нодами, со slave-нодами – все по-взрослому.
- Остается только обучить людей. Но это – «камень преткновения», потому что вначале программистам будет трудно, им надо перестраивать свой процесс разработки.
Так почему же все это должно окупиться? Откуда возьмется профит? Почему у нас вернутся инвестиции?
Здесь ключевая «фишка» в «техническом долге». Известно, что до 20 процентов своего времени каждую неделю программист должен отдавать на возвращение «технических долгов». Что такое «технический долг»? Это когда мы некачественно выполняем свою работу: где-то «костыль», где-то мы написали «НайтиПоКоду», где-то в архитектуре что-то сделали не так, как надо, потому что нас бизнес «теребил», и нужно было закончить быстрее. Это называется «технический долг» – мы сами себя немного «подставляем» в будущем, создавая проблемы, которые нам же потом придется разгребать (или тем, кто будет сопровождать систему).
Так вот, запуск инженерных практик позволяет поднять качество разработки. А за счет повышения качества разработки мы отдаем свои «технические долги» и НЕ накапливаем новые.
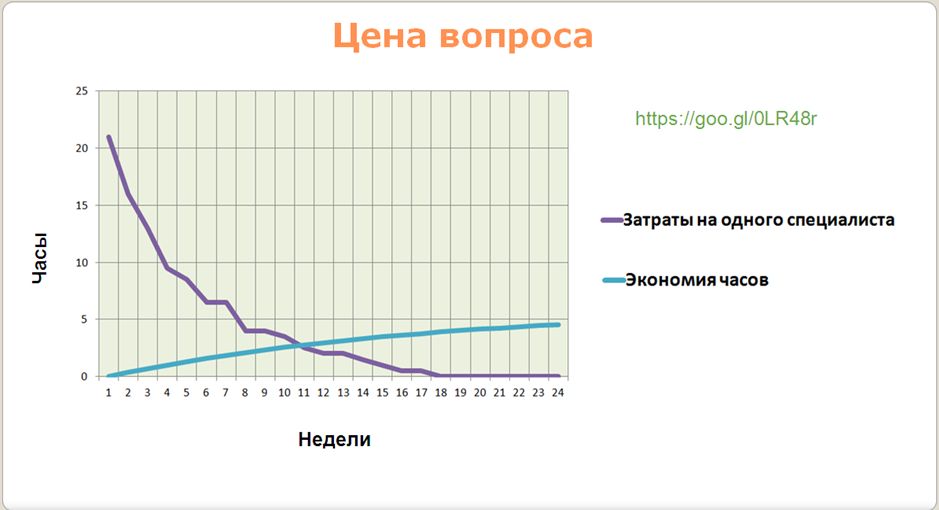
![]()
Согласно расчетам, которые мы проводили на наших проектах:
- Срок обученияIT-специалистов таким практикам – где-то 3 месяца, после этого затраты на обучение уже сводятся к нулю.
- А срок окупаемости – до года, может быть, даже быстрее (9 месяцев и т.д.)
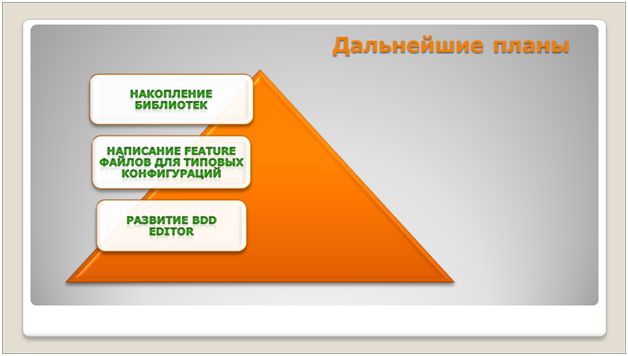
Планы по развитию
![]()
Планы по развитию нашего инструмента – Vanessa Behavior:
- Мы будем накапливать библиотеки, чтобы еще больше увеличить процент повторно используемого кода. В идеале хотелось бы, чтобы шаги сценариев тестирования появлялись сразу на этапе написания требований, чтобы программисту не приходилось их описывать с нуля. Нам для этого нужны библиотеки, и мы это будем развивать.
- Написаниеfeature-файлов для типовых конфигураций. Мы работаем с Бухгалтерией, с перепиленным УПП, ЗУП, некоторыми другими конфигурациями. Поэтому мы собираемся накапливать feature-файлы, покрывающие их типовой функционал, а также тот функционал, который мы сами дорабатываем.
- РазвитиеBDDEditor. В процессе внедрения практик BDD выяснилось, что хочется писать feature-файлы еще удобнее, еще быстрее – не просто в Word их писать, а сразу мышкой набрасывать. Для этого мы разрабатываем специальный инструмент – BDD Editor. Он позволит сделать это еще лучше,еще эффективнее.
Ссылки по проекту
Ссылки по проекту:
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2015 CONNECTION 15-17 октября 2015 года.
TDD
BDD
Написание кода тестов до написания кода программы
Прямая связь кода с требованиями с помощью Gherkin
Сценарное тестирование через интерфейс пользователя
Повторное использование кода тестов в других сценариях
Прямая связь кода с требованиями с помощью Gherkin
Код Gherkin(Дано, Когда, Тогда, И)
Код 1С (имена вызываемых процедур)
Дано: Контрагент (покупатель) «Иванов А.В.» оплачивает сумму 1000 рублей. Долг контрагента 500 рублей.
Когда: Фиксируется оплата от контрагента «Иванов А.В.» по договору «Основной» на сумму 1000 рублей
Тогда: Формируется проводка по счету «ВзаиморасчетыСКонтрагентами» на сумму 500 рублей (погашение долга)
И: Формируется проводка по счету «АвансыПолученные» на сумму 500 рублей (фиксируется аванс).
Каждой строке кода на языке Gherkin сопоставляется одна процедура на языке 1С. Сразу должны возникнуть вопросы. Почему только одна процедура и зачем вообще, что то связывать?
Что бы ответить на этот вопрос, давайте вернемся к первому пункту таблицы сравнения BDD и TDD.
Написание кода тестов до написания кода программы в BDD.
Как я уже упоминал, концепция написания кода тестов до написания кода программы в ВDD, реализована немного иначе, чем в TDD. В Test Driven Development, для нас важно только проверить логику программного кода, а в Вehavior Driven Development важно проверить конечные процессы в системе (хотя параллельно проверять логику кода никто не мешает). Данные процессы, как уже известно, описываются с помощью Gherkin. В технике BDD это неотъемлемая часть написания теста, а так же формулирования требований, написания документации и тд.
Но тесты на языке Gherkin невозможно выполнить, это не язык программирования. Но зато их можно связать с кодом на языке программирования. Важно чтобы эта была реальная связь, то есть код на Gherkin должен полностью соответствовать коду на реальном языке программирования. Чем детальнее эта связь (чем больше строк в коде Gherkin), тем более развернутым получается тест. Теперь о том, зачем нам развернутый тест.
Основных причины две, первая: «В любом месте реального кода программы может возникнуть ошибка, и мы должны быстро понять - где и почему». Представим, что мы сделали следующую связь:
Код Gherkin(Дано, Когда, Тогда, И)
Код 1С (имена вызываемых процедур)
Дано: Контрагент (покупатель) «Иванов А.В.» оплачивает сумму 1000 рублей. Долг контрагента 500 рублей.
Когда: Фиксируется оплата от контрагента «Иванов А.В.» по договору «Основной» на сумму 1000 рублей
Тогда: Формируется проводка по счету «ВзаиморасчетыСКонтрагентами» на сумму 500 рублей (погашение долга)
И: Формируется проводка по счету «АвансыПолученные» на сумму 500 рублей (фиксируется аванс).
Если у нас возникнет ошибка в процедуре ВыполнитьТест(), то мы как программисты найдем причину. Но нам, скорее всего, понадобится анализ кода, запуск отладчика и тд. А все это наше время. Другое дело, если ошибка возникнет в процедуре «ПроверитьПоводкиПоСчетамАвансовКонтрагентов()», которая сопоставлена в строке Gherkin «И: Формируется проводка по счету «АвансыПолученные» на сумму 500 рублей (фиксируется аванс).». Скорее всего, мы просто заглянем в движения документа и увидим там другую сумму или вообще отсутствие проводок.
Вторая причина, и самая важная: «Мы планируем писать тест до написания программы». И выглядит это следующим образом: у нас уже есть логика на Gherkin, у нас уже есть имена процедур: ПроверитьНаличиеДолгаКонтрагентаПоВзаиморасчетам(), СоздатьПровестиДокументПКО(). Нам остается только зайти в «тело» одноименных процедур и написать там код. Конечно часть процедур нам может не понадобиться в реальной программе. Например «ПроверитьПроводкиПоСчетам() будет нагружать систему, да и если с проводками будет проблема, скорее всего бухгалтер это заметит. А вот другие процедуры, которые будут создавать и проводить документы, мы реально можем использовать. Причем, мы их поместим в общие модули, эти модули отнесем к соответствующим подсистемам и будем вызывать так же, как вызываем их в тестах. Красота и порядок.
Теперь давайте разберемся какие процедуры, с какими строками связывать. В начале раздела, посвященного синтаксису языка Gherkin, указан шаблон истории. Связь реального кода осуществляется только со строками, в которых указаны ключевые слова: «Дано, Когда, Тогда» и детализируются связи с помощью ключевого слова «И».
Напротив ключевого слова «Дано» в квадратных скобках указано «[Ситуация или условие]». Это значит, что на этом этапе проверяются параметры, выполняются запросы к базе данных, сравниваются значения. Это необходимые условия, которые должны быть уже выполнены до начала расчета и создания данных в информационной системе.
Напротив ключевого слова «Когда» в квадратных скобках указано «[Событие или действие]». Это непосредственно расчет и создание данных.
И наконец, напротив ключевого слова «Тогда» в квадратных скобках указано «[Проверка результата]». Это такие же проверки, как и после слова «Дано», только проверяем мы то, что было сделано после ключевого слова «Когда».
Сценарное тестирование через интерфейс пользователя
Сценарное тестирование - это тестирование по предварительно написанному сценарию. Код на языке Gherkin это сценарий, а также отчасти документация и требования.
Но только отчасти, потому что читая такую документацию, пользователь может застрять на первом же «Когда: Фиксируется оплата от контрагента «Иванов А.В.» по договору «Основной» на сумму 1000 рублей». Конечно, эту строку можно развернуть подробнее:
Когда: Создается документ ПКО
И: заполняется реквизит контрагент
И: Заполняется реквизит договор…
Но такие сочинения могут занимать не одну страницу и не один час времени. С одной стороны мы хотим, что бы подготовка таких тестов занимала как можно меньше времени, с другой была как можно более прозрачной и всеобъемлющей. Вопрос - как этого достичь.
Приведу еще пример: В документе ПКО, в модуле формы, в обработчике «ПриИзмененииКонтрагента()» есть проверка, что данный контрагент является физлицом. Такие проверки желательно делать перед записью в модуле объекта, но реальный процесс разработки может диктовать иное. Коля и Вася в какой-то момент времени одновременно дорабатывали один и тот же документ, модуль объекта был захвачен Колей, а Васе нужно было срочно доделать работу. Или задача стояла таким образом: «Выбираемое значение должно проверяться сразу». В результате наш тест этого вообще не выявит, потому что мы создаем документ ПКО программно, не открывая его форму. Мы можем при написании теста программно открывать форму и вообще эмулировать все действия реального пользователя, но объем кода в тесте увеличится в разы. Мы подошли вплотную к проблеме «надо тестировать, но надо разрабатывать, а не тестировать».
В данной ситуации, если мы хотим проверить работу приложения, нам необходимо тестировать интерфейс. Вообще условно разделяют две категории тестирования: на уровне кода и тестирование интерфейса. Причем тестирование интерфейса, это не только пользовательский интерфейс, но и различные сервисы типа Web-сервисов, которые вообще не имеют графического интерфейса. Если говорить о тестировании графических интерфейсов, то идеальным решением было бы использовать специальные программные средства и инструменты.
Основная цель таких продуктов – это ускорить и упорядочить процесс написания тестов. Этот процесс должен стать максимально прозрачным и простым. В сфере автоматизации тестирования через графический интерфейс, можно выделить два основных вида инструментов:
- Которые взаимодействуют с интерфейсом приложения на уровне программного кода. Это выглядит примерно так же, если бы мы писали код открывающий формы и нажимающий кнопки, только у нас были бы генераторы этого кода. Мы бы нажимали на кнопку «Ок», а в модуле появлялась строка типа ТекущаяФорма.Кнопки.Ок.Нажать(). Но для того чтобы реализовать данную возможность, разработчик приложения должен заранее задуматься о предоставлении такого интерфейса.
- Которые взаимодействуют с интерфейсом через драйвера устройств ввода данных и используют механизмы распознания изображений. Это выглядит примерно так: программа ищет на экране конкретное изображение, если она его находит, то эмулирует клики мышки в конкретную область изображения и начитает ввод данных с клавиатуры. Данный подход не зависит от того, предоставил ли разработчик приложения такую возможность или нет. Но недостатком является то, что могут возникать ошибки при распознавании изображений, есть зависимость от разрешения экрана (оно должно быть неизменным) и скорость работы таких тестов ниже, так как на распознавание изображений уходит определенное время.
В поисках решения я обратился ко второму виду инструментов, которые имеют общепринятое название «Image-based testing». Здесь оказался хороший выбор от навороченных и дорогих, типа «TestComplete», до простых и полностью бесплатных типа «SikuliX». Многие из этих продуктов сами имеют программный интерфейс, начиная от взаимодействия через командную строку, до встроенных интерпретаторов типа «Python». Основная идея для искателей решений данной проблемы, это обеспечить взаимодействие этих продуктов с платформой 1С, чем я уже занялся и в ближайшее время надеюсь предоставить результаты. Так же надеюсь, что возможно кто-то это уже сделал и поделится своими идеями.
Ну а если для вас управляемый интерфейс это родное или вы уже придумали как быстро взаимодействовать с обычными формами, обратите внимание на продукт под названием «Vanessa Behavior». Он бесплатный и очень быстро развивается. Есть хороший видео обзор Повторное использование кода тестов в других сценариях
Данный пункт – это высший пилотаж, но к нему по любому приходят все, кто всерьез занимается автоматизацией тестирования. Основная идея – использовать этапы одного теста в других тестах. То есть мы собираем некую библиотеку, в которой хранятся часто используемые действия, скажем по созданию и заполнению конкретных видов документов, формированию отчетов, проверке движений и тд.
Опять же, если говорить о готовых решениях, то в «Vanessa Behavior» это тоже реализовано. На мой взгляд, данный проект весьма перспективен и заслуживает поддержки.
Всем спасибо за внимание!
Глоссарий
Software development methodology (SDM) – Так же известны как software development life cycle, software development process, software process. Методологии деления процесса разработки программного обеспечения на отдельные фазы или этапы, каждый из которых содержит меры улучшающие планирование и управление процессом разработки в целом. В качестве примеров можно привести: «Каскадную модель» (waterfall model), Прототипное программирование (prototyping), СпираL9;льная модель (spiral model), быстрая разработка приложений(rapid application development), экстемальное программирование (extreme programming), различные agile-методы (agile methodology) и тд. (Wikipedia)
Agile software development. - Гибкая методология разработки (agile-методы)— серия подходов к разработке программного обеспечения, ориентированных на использование итеративной разработки, динамическое формирование требований и обеспечение их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля. Существует несколько методик, относящихся к классу гибких методологий разработки, в частности «экстремальное программирование», «DSDM», «Scrum», «FDD». (Wikipedia)
Domain-driven design (DDD).
Предметно - ориентированное проектирование. Это набор принципов и схем, направленных на создание оптимальных систем объектов. Сводится к созданию программных абстракций, которые называются моделями предметных областей. В эти модели входит бизнес-логика, устанавливающая связь между реальными условиями области применения продукта и кодом. Предметно-ориентированное проектирование не является какой-либо конкретной технологией или методологией. Это набор правил, которые позволяют принимать правильные проектные решения. Данный подход позволяет значительно ускорить процесс проектирования программного обеспечения в незнакомой предметной области. Есть книга - Эрик Эванс (Eric Evans) «Проблемно-ориентированное проектирование». (Wikipedia)
Feature-driven development (FDD). – Разработка управляемая функциональностью. Итеративная методология разработки программного обеспечения, одна из гибких методологий разработки (agile). FDD представляет собой попытку объединить наиболее признанные в индустрии разработки программного обеспечения методики, принимающие за основу важную для заказчика функциональность (свойства) разрабатываемого программного обеспечения. Основной целью данной методологии является разработка реального, работающего программного обеспечения систематически, в поставленные сроки. (Wikipedia)
Test-driven development (TDD). – Разработка через тестирование. Техника разработки программного обеспечения, которая основывается на повторении очень коротких циклов разработки: сначала пишется тест, покрывающий желаемое изменение, затем пишется код, который позволит пройти тест, и под конец проводится рефакторинг нового кода к соответствующим стандартам. Кент Бек, считающийся изобретателем этой техники, утверждал в 2003 году, что разработка через тестирование поощряет простой дизайн и внушает уверенность (inspires confidence). В 1999 году при своём появлении разработка через тестирование была тесно связана с концепцией «сначала тест» (test-first), применяемой в «экстремальном программировании» (agile методология), однако позже выделилась как независимая методология. (Wikipedia)
behavior-driven development (BDD). - Разработка основанная на функционировании. Процесс разработки программного обеспечения, который возник из TDD. Объединяет главные техники и принципы TDD, идеи из DDD и OOAD (техника объектно ориентированного анализа и проектирования). BDD главным образом является идеологией о том, как разработке программного обеспечения быть одновременно понятной бизнесу и техническим специалистам. В ней используются специализированные программные инструментарии для разработки программного обеспечения. И не смотря на то, что эти инструментарии используются в основном в BDD проектах, они так же могут быть использованы для поддержки TDD. (Wikipedia)
Благодаря классному дядьке Кенту Беку (Kent Beck) родилась замечательная методология test-driven development. Не смотря на необычность подхода, переворачивающего привычный процесс написания кода с ног на голову (тест на функционал создается до реализации), сейчас уже можно сказать, что разработка через тестирование стала стандартом де-факто. Практически в любых вакансиях фигурирует требование к знанию и опыту использования методики TDD и соответствующих инструментов. Почему, казалось бы, ломающая привычную парадигму мышления методология прижилась и стандартизировалась? Потому что “Жизнь слишком коротка для ручного тестирования”, а писать авто-тесты на существующий код иногда просто не возможно, ведь код, написанный в обычной парадигме, как правило совершенно тесто-не-пригодный.
Стоит отметить, что за время своего существования методология успела обзавестись ответвлением (fork) в виде BDD. Дэн Норт (Dan North) в своей статье (Introducing BDD) указал на сложности внедрения TDD среди разработчиков и для решения обозначенных проблем предложил практику, которая называется behaviour-driven development. Основной фишкой BDD можно назвать микс из TDD и DDD, которая в начале выражалась в правильном именовании тестовых методов (названия тестовых методов должны быть предложениями). Апогеем BDD, на текущий момент, можно считать рождение языка Gherkin и инструментария, который его использует (Cucumber, RSpec и т.п.).
К чему я веду и при чем тут 1С?
-
— вполне себе зрелый проект, позволюящий разрабатывать в стиле TDD. — спецификации на языке Gherkin и т.п., пока что не в релизном состоянии.
Прежде чем ответить на этот вопрос, я хочу коснуться темы хорошо написанных утверждений в тестах. Утверждения обозначают ожидаемое поведение нашего кода. Одного взгляда на утверждения должно быть достаточно, чтобы понять, какое поведение тест пытается до нас донести. К сожалению, классические утверждения не позволяют этого достичь. Зачастую нам приходится долго вчитываться и расшифровывать замысел автора теста.
К счастью, в последнее время появилась тенденция к применению текучих интерфейсов (fluent interface), что очень положительно сказывается на наглядности и интуитивной понятности кода. Инструментарий для тестирования так же не остался в стороне.оявились текучие утверждения, называемые так же утверждениями в стиле BDD. Они позволяют формулировать утверждения в более естественной, удобной и выразительной манере.
Впервые я столкнулся с подобным подходом в NUnit в модели утверждений на основе ограничений (Constraint-Based Assert Model).
Много позже я познакомился со связкой mocha.js + chai.js, которая у меня вызвала полнейший восторг.Так вот, мой ответ на вопрос “Как лично я могу помочь миру 1С разработки перейти на передовые методологии?” — текучие утверждения… для начала.
Разработка текучих утверждений для платформы 1С
Как заправский разработчик через тестирование, я начал разработку с теста. Первый тестовый метод содержал всего 1 строку:
- Что(ПроверяемоеЗначение) — сохраняет в контексте объекта-утверждения проверяемое значение;
- Равно(ОжидаемоеЗначение) — проверяет на равенство ранее сохраненное значение с переданным ожидаемым значением. В случае неравенства выбрасывается исключение с описанием ошибки утверждения.
Далее я задумался над тем, что делать с утверждением НеРавно. Должно ли быть такое утверждение? В классических утверждениях так и есть, почти каждое утверждение имеет своего антипода (Равно/НеРавно, Заполнено/НеЗаполнено и т.д.). Но только не в текучих утверждениях! Так родился тест №2:
Выглядит красиво, но не реализуемо на языке 1С. Еще попытка:
По прежнему красиво и казалось бы реализуемо. Нужно всего лишь взвести флаг отрицания в контексте объекта-утверждения, и затем любое следующее по цепи утверждение проверять с учетом этого флага. По сути нужен был XOR, на языке 1С это выглядит вот так:
Но платформа отказалась компилировать объект с методом Не(). Дело в том, что Не — зарезервированное слово, ограничение на его использование распространяется в т.ч. и на имя метода. Мозговой штурм с коллегами не позволили красиво обойти эту проблему, поэтому финальный вариант с отрицанием выглядит так:
Если кто-то предложит лучшее решение обозначенной проблемы, я буду очень признателен. Вариант замены русских букв на латиницу не предлагать!В итоге родился следующий API
Не_() — отрицает любое утверждение следующее по цепи.
ЭтоИстина() — утверждает, что проверяемое значение является Истиной.
ЭтоЛожь() — утверждает, что проверяемое значение является Ложью.
Равно(ОжидаемоеЗначение) — утверждает, что проверяемое значение равно ожидаемому.
Больше(МеньшееЗначение) — утверждает, что проверяемое значение больше, чем переданное в утверждение.
БольшеИлиРавно(МеньшееИлиРавноеЗначение) / Минимум(МинимальноеЗначение) — утверждает, что проверяемое значение больше или равно переданному в утверждение.
МеньшеИлиРавно(БольшееИлиРавноеЗначение) / Максимум(МаксимальноеЗначение) — утверждает, что проверяемое значение меньше или равно переданному в утверждение.
Меньше(БольшееЗначение) — утверждает, что проверяемое значение меньше, чем переданное в утверждение.
Заполнено() — утверждает, что проверяемое значение отличается от значения по умолчанию того же типа.
Существует() — утверждает, что проверяемое значение не Null и не Неопределено.
ЭтоНеопределено() — утверждает, что проверяемое значение это Неопределено.
ЭтоNull() — утверждает, что проверяемое значение это Null.
ИмеетТип(Тип) — утверждает, что проверяемое значение имеет переданный в утверждение тип или имя типа.
Между(НачальноеЗначение, КонечноеЗначение) — утверждает, что проверяемое значение находится между переданными в утверждение значениями.
Содержит(ИскомоеЗначение) — утверждает, что проверяемое значение содержит переданное в утверждение. Применяется для строк и коллекций.
ИмеетДлину(ОжидаемаяДлина) — утверджает, что проверяемое значение имеет длину переданную в утверждение. Применяется для строк и коллекций.
Примеры использования
Пример немного сложнее:
Послесловие
Разработка доступна на github. Как, наверное, заметил читатель с пытливым умом, ссылка ведет на нечто большее, чем просто на библиотеку утверждений. Но это уже материал для следующей статьи.![]()
![]()
![]()
![]()
Что пишут в блогах
![Подписаться]()
Конференции
Heisenbug 2022 Spring
Большая техническая конференция по тестированию
Online — с 30 мая по 1 июня. Offline-день — 21 июняПрофессиональная конференция по автоматизации в тестировании и рядом
27 и 28 июня, Москва, Radisson Slavyanskaya.Что пишут в блогах (EN)
Разделы портала
Онлайн-тренинги
Перевод: Анна Радионова
Существует много видов ПО тестов. Практики BDD можно применять в любых аспектах тестирования, но BDD фреймворки используются далеко не во всех типах тестов. Поведенческие сценарии, по сути, являются функциональными тестами - они проверяют, что тестируемый продукт работает корректно. Для тестирования производительности могут использоваться инструменты, в то время как BDD фреймворки не предназначены для этих целей. Задача данной статьи, в основном, состоит в описании роли BDD автоматизации в Пирамиде Тестирования. Прочитайте статью BDD 101: Manual Testing для того, чтобы понимать как BDD применяется при ручном тестировании. (Всю информацию по BDD можно найти на странице Automation Panda BDD page)
Пирамида Тестирования
Пирамида Тестирования представляет собой подход к разработке тестов, который разделяет тесты на три слоя: юнит, интеграционные и end-to-end.
■ Юнит-тесты - это тесты белого ящика, которые проверяют отдельные части кода, такие как функции, методы и классы. Они должны быть написаны на том же языке, что и тестируемый продукт и храниться в том же репозитории. Они часто прогоняются как часть сборки, чтобы сразу же увидеть успешно ли завершается тест или нет.
■ Интеграционные тесты - это тесты черного ящика, которые проверяют, что интеграционные точки между компонентами продукта работают корректно. Тестируемый продукт должен быть в активной фазе и развернут на тестовом окружении. Тесты сервиса часто являются именно тестами интеграционного уровня.
■ End-to-end тесты - это тесты черного ящика, которые проверяют пути выполнения системы. Их можно рассматривать как многошаговые интеграционные тесты. Тесты для веб-интерфейса часто являются именно end-to-end тестами.
Ниже представлено графическое отображение Пирамиды Тестирования:
Пирамида Тестирования
Сложность тестов отображена по возрастанию: юнит-тесты самые простые и выполняются очень быстро, в то время как end-to-end тесты требуют тщательной настройки, продуманности логики и их прогон длится долгое время. В идеале лучше, чтобы большая часть тестов находилась в нижней части схемы, а в верхней ее части их было меньше. Реализовать тестовое покрытие и изолировать тесты проще на более низкоуровневом этапе, чтобы на более высоком уровне были внедрены более трудозатратные, хрупкие тесты. Перенос тестов в нижнюю часть пирамиды также может свидетельствовать о более широком тестовом покрытии и меньшем времени выполнения. Различные слои тестирования оптимизируют риски и делают его эффективным.
Behavior-Driven юнит-тестирование
Тестовые BDD фреймворки не предназначены для написания юнит-тестов. Юнит-тесты являются низкоуровневыми, программными тестами для проверки отдельных функций или методов. Можно написать Gherkin тест в целях юнит-тестирования, но по факту это перебор. Гораздо лучше использовать уже существующие юнит-тест фреймворки как, например, JUnit, NUnit и pytest.
Тем не менее, BDD практики могут применяться для юнит-тестов. Каждый юнит-тест должен быть направлен на основную составляющую: один вызов, единичная вариация, определенная комбинация ввода; на поведение. В дальнейшем при разработке спецификация поведения фичи четко отделяет юнит тесты от тестов более высокого уровня. Разработчик функционала также ответственен за написание юнит-тестов, в то время как за интеграционные и end-to-end тесты несет ответственность другой инженер. Спецификация поведения является, своего рода, джентльменским соглашением о том, что юнит-тесты будут являться отдельной сущностью.
Интеграционное и End-to-End тестирование
Тестовые BDD фреймворки наиболее ярко проявляют себя на интеграционных и end-to-end уровнях тестирования.
Поведенческие спецификации однозначно и лаконично описывают, на что именно ориентирован тест-кейс. Шаги могут быть написаны на интеграционном или end-to-end уровне. Тесты сервиса могут быть написаны с помощью поведенческих спецификаций, как, например в Karate. End-to-end тесты фактически представляют собой многошаговые интеграционные тесты. Обратите внимание на следующий пример, который, на первый взгляд, кажется базовой моделью взаимодействия с пользователем, но, по сути, является объемным end-to-end тестом:
Given a user is logged into the social media site
When the user writes a new post
Then the user's home feed displays the new post
And the all friends' home feeds display the new postПростая публикация в социальной сети включает процессы взаимодействия с интерфейсом, вызовы сервисов бекенда и внесение изменений в базу данных в режиме реального времени. Описан полный путь прохождения в системе. Автоматизированные шаги могут покрывать эти уровни явно или неявно, но они совершенно точно покрыты тестом.
Длительные End-to-End тесты
Термины часто понимаются разными людьми по-разному. Когда люди говорят “end-to-end тесты,” они подразумевают продолжительные последовательные тесты: тесты, которые покрывают различное поведение продукта одно за другим. Это утверждение заставляет содрогнуться приверженцев BDD, т.к это противоречит основному правилу BDD: один сценарий, одно поведение. Конечно, с помощью BDD фреймворков можно составлять длительные end-to-end тесты, но нужно хорошо подумать, стоит ли это делать и как именно.
Существует пять основных принципов написания длительных end-to-end сценариев в BDD:
Читайте также: