
Алгоритм сжатия файлов формата jpeg
В алгоритме JPEG исходное изображение представляется двумерной матрицей размера N*N, элементами которой являются цвет или яркость пиксела. Упаковка значений матрицы выполняется за три этапа.
Высокая эффективность сжатия, которую дает этот алгоритм, основана на том факте, что в матрице частотных коэффициентов, образующейся из исходной матрицы после дискретного косинусного преобразования, низкочастотные компоненты расположены ближе к левому верхнему углу, а высокочастотные - внизу справа. Это важно потому, что большинство графических образов на экране компьютера состоит из низкочастотной информации, так что высокочастотные компоненты матрицы можно безболезненно выбросить.“Выбрасывание” выполняется путем округления частотных коэффициентов. После округления отличные от нуля значения низкочастотных компонент остаются, главным образом, в левом верхнем углу матрицы. Округленная матрица значений кодируется с учетом повторов нулей. В результате графический образ сжимается более чем на 90% , теряя очень немного в качестве изображения только на этапе округления.
Основным этапом работы алгоритма является дискретное косинусное преобразование (ДКП), представляющее собой разновидность преобразования Фурье. Оно позволяет переходить от пространственного представления изображения к его спектральному представлению и обратно. Что нужно сделать на первом этапе первом этапе ? Следует создать ДКП матрицу, используя такую формулу :
например, нам нужно сжать следующий фрагмент изображения:
затем умножаем ее на ДКП матрицу: RES = TMP*DCT
На этом этапе мы посчитаем матрицу квантования, используя этот псевдо код:
где q - это коэффициент качества, от него зависит степень потери качества сжатого изображения для q = 2 имеем матрицу квантования:
теперь нужно каждое число в матрице квантования разделить на число в соответствущей позиции в матрице RES, в результате получим:
как вы видите здесь имеется довольно много нулей, мы получим наиболее длинную последовательность нулей, если будем использовать следущий алгоритм:
итак у нас получилась последовательность:
Самым распространенным методом вторичного сжатия является метод Хаффмана и его разновидности.
Метод Хаффмана.
- Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте;
- Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагается равной сумме вероятностей составляющих его символов. В конце концов, мы построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него;
- Прослеживаем путь к каждому листу дерева помечая направление к каждому узлу (например, направо - 1, налево - 0).
Поясним создание дерева с использованием иллюстраций :
Таким образом, построено дерево
Теперь, если в тексте встречается, например, символ "d", то вместо того, чтобы выделять этому символу байт, после сжатия символ займет всего 2 бита (01).
И снова здравствуйте! Я нашел эту статью, написанную еще мае 2019-ого года. Это — продолжение серии статей о WAVE и JPEG, Вот первая. Эта публикация включит в себе информацию об алгоритме кодирования изображений и о самом формате в целом.
Щепотку истории
Столовую ложку статьи из Википедии:
JPEG (Joint Photographic Experts Group) — один из популярных растровых графических форматов, применяемый для хранения фотоизображений и подобных им изображений.
Разработан этот стандарт был Объединенной группой экспертов по фотографии еще в 1991 году для эффективного сжатия изображений.
Какой путь проходят изображения от сырого вида до JPEG
Некоторые считают, что JPEG-картинки — сжатые методом Хаффмана сырые данные, но это не так. Перед контрольным сжатием данные проходят длинный путь.
Сначала цветовую модель меняют с RGB на YCbCr. Для этого даже есть специальный алгоритм — здесь. Y не трогают, так как он отвечает за яркость, и его изменение будет заметно.
Основная часть подготовки
Теперь самая сложная и необходимая часть. Вся картинка разбивается на блоки 8x8 (используют заполнение в случае, если разрешение не кратно стороне блока).
Теперь к каждому блоку применяют ДКП (Дискретно-косинусное преобразование). В этой части из картинки вынимают все лишнее. Используя ДКП надо понять, описывает ли данный блок (8x8) какую-нибудь монотонную часть изображения: неба, стены; или он содержит сложную структуру (волосы, символы и т.д.). Логично, что 64 похожих по цвету пикселей можно описать всего 1-им, т.к. размер блока уже известен. Вот вам и сжатие: 64 к 1.
ДКП превращает блок в спектр, и там, где показания резко сменяются, коэффициент становится положительным, и чем резче переход, тем выше будет выход. Там, где коэффициент выше, на картинке изображенны четкие переходы в цвете и яркости, где он ниже — слабые (плавные) смены величин компонентов YCbCr в блоке.
Квантование
Тут уже применяются настройки сжатия. Каждый из коэффициентов в каждой из матриц 8x8 делится на определенное число. Если качество изображения после всех его модификаций вы более уменьшать не будете, то делитель должен быть единицей. Если вам важнее память, занимаемая этой фотографией, то делитель будет больше 1, и частное округляется. Так выходит, что после округления нередко получается много нулей.
Квантование делают для создания возможности еще большего сжатия. Вот как это выглядит на примере квантования графика y = sin(x):
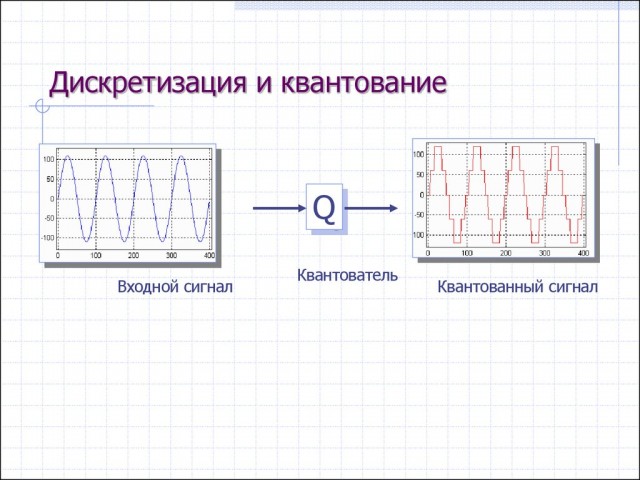
Сжатие
Сначала проходим по матрице зиг-загом:

Получаем одномерный массив с числами. Мы видим, что в нем много нулей, их можно убрать. Для этого вместо последовательности из множества нулей мы вписываем 1 нуль и после него число, обозначающее их количество в последовательности. Таким образом можно сбросить до 1/3 размера всего массива. А дальше просто сжимает этот массив методом Хаффмана и вписываем уже в сам файл.
Где используется
Везде. Как и PNG, JPEG используется в фотокамерах, OS'ях (в качестве логотипов компании, иконок приложений, thumbnail'ов) и во всех возможных сферах, где нужно эффективно хранить изображения.
Вывод
На данный момент знания о JPEG сейчас ценны лишь в образовательных целях, ведь он уже везде встроен и оптимизирован большими группами людей , но гранит науки все-же вкусный .
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.

В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
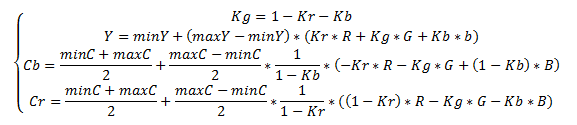
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц

Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.
JPEG - это формат сжатия изображений, который позволяет уменьшить размер файла в 20, 30, 100 раз! В посте НЕ будет описана история создания формата, его плюсы и минусы и самые тонкие технические детали. Это обзорное повествование о том, как происходит сжатие (в очень упрощенном, и от этого более понятном виде) и как работает технология.
Вообще, если бы не джипег, то интернет сейчас был бы совсем другим. Думаю, внешне он напоминал бы сайты 90-х. И мы бы не смогли запросто инстаграмить все подряд и смотреть фотки котиков на телефоне) К тому же, этот алгоритм лежит в основе сжатия видео! Так что без него не было бы ни этого ролика, ни Ютюба, ни даже фильмов онлайн без регистрации и смс!
Но чтобы понять, насколько гениальная штука джипег, нужно разобраться, как кодируются изображения без сжатия. Возьмем картинку 1000 на 1000 точек. Каждый пиксель – это смесь трех составляющих, трех цветов – красного, зеленого и синего. Одна составляющая кодируется, как правило, 8 битным числом.
Нетрудно посчитать, что такая картинка без сжатия будет весить:
8 х 3 х 1000 х 1000 = 24 000 000 бит, то есть 3 мегабайта.
Но если сохранить ее в джипеге, она может занимать, например, 90 килобайт. То есть в 33 раза меньше! Да, качество чуть-чуть теряется, но не в 30 раз ведь! Как же это работает?
Итак. Алгоритм сжатия джипега можно разбить на несколько основных этапов.
1 - Цветовое пространство
Этап первый – перевод в другое цветовое пространство, в котором разделены яркостная и цветовая составляющие. На этом шаге потерь не происходит, ведь каждый пиксель по-прежнему состоит из трех компонентов. Только теперь это яркостная компонента и две цветовых. Короче, если упростить, происходит следующее: создается Ч/Б изображение и цветовая маска к нему, вот и все!
2 - Ресемплинг
Возникает вопрос, зачем? А все дело в нашем зрении! Человеческий глаз менее чувствителен к изменениям цвета, чем к изменениям яркости. И такое предварительное разделение нужно, чтобы в цветовых каналах можно было убрать часть деталей.
Это и происходит на втором этапе – ресэмплинге. Каждые 4 цветовых пикселя объединяются в один. Да, происходит потеря некоторых деталей, но… это практически незаметно! И на таком приеме уже удается сжать файл в 2 раза!
3 - Блоки 8х8
На следующем шаге картинка разбивается на блоки 8 на 8 пикселей. Кстати, шакалы от этого становятся видны, если очень сильно сжать изображение, например, так:
4 - Дискретное косинусное преобразование
Это, пожалуй, самый важный этап. Алгоритм должен каким-то образом понять, насколько много деталей в каждом блоке. Например, если это монотонный кусок неба, его можно закодировать чуть ли не 1 байтом) А если это ваша невероятная прическа, там много переходов яркости и цвета, на это нужно потратить больше бит.
Делается такой анализ с помощью дискретного косинусного преобразования. Это разновидность преобразования Фурье, которое, кстати, и в mp3 применяется. Сложная, но очень интересная штука!
Итак, рассмотрим блок 8 на 8 пикселей. Напоминаю, что он уже разбит на яркостный и цветовые каналы, и преобразование проводится над каждым отдельно. Иными словами мы работаем уже с монохромными блоками.
Дискретное косинусное преобразование производит разложение по спектру пространственных волн. Что же это такое? Любую монохромное изображение 8 на 8 пикселей можно представить как смесь из 64 картинок, на которых посмотрите что изображено:
Вот такие вот периодические плавные переходы! Это и есть пространственные волны разной длины (по горизонтали и вертикали). Есть другая версия отображения этих пространственных волн, трехмерная. Кому как удобнее для понимания:
Если накладывать такие базовые картинки друг на друга, а точнее прибавлять или вычитать с определенным коэффициентом каждую, то мы сможем получить что угодно! Вот как это выглядит, например, для буквы А. Посмотрите, с каждым следующим наложением, шаг за шагом, добавляется все больше и больше деталей и получается реально буква А:
Все форматы делятся на три группы: без сжатия, со сжатием без потерь и со сжатием с потерями. В файле также может храниться дополнительная информация. Например, все файлы, снятые цифровыми фотоаппаратами имеют данные EXIF (модель фотоаппарата, дата и параметры съемки, разрешение и т.п.).
JPEG (Joint Photographic Experts Group — .jpg, .jpg, jfif) — пожалуй, самый известный растровый формат. Используется сжатие с потерей качества. При сильном сжатии проявляется эффект “квадратиков” (пикселей 8x8). Не поддерживает прозрачность (в отличие от TIF, PNG, GIF). Несколько лет назад был создан формат JPEG2000 (.jp2), который использует более мощный алгоритм сжатия на базе вейвлет-преобразования, однако так и не смог вытеснить прародителя.
PNG (Portable Network Graphics — .jpg) — растровый графический формат, использующий сжатие без потерь. Создан для замены формата GIF, т.е. основная сфера его применения — сеть Интернет. Имеет ряд преимущество, по сравнению с устаревающим GIF. Впрочем, PNG не умеет создавать анимированные картинки и степень сжатия ненамного превосходит предшественника.
GIF (Graphics Interchange Format — .jpg) — популярный некогда формат. Поддерживает не более 256 цветов одновременно, в отличие от PNG. Зато GIF-файлы обладают небольшим размером и поддерживают простейшую анимацию (смена кадров в одной файле).
TIFF (Tagged Image File Format — .tif или .tiff) — популярный растровый формат, поддерживающий практически все известные цветовые пространства. Вариант без сжатия практически стал стандартом в полиграфии. Возможно применение различных алгоритмов сжатия без потерь и с потерями.
PSD (.psd) — внутренний формат Adobe Photoshop. Тем не менее, в виду его распространенности, .psd “понимают” многие программы сторонних разработчиков. Несжатый формат.
RAW (.nef, .crw, .raf и другие) — графический формат данных, хранящий “сырые” данные, полученные с цифрового фотоаппарата. Единого стандарта не существует, каждый производитель фотокамер использует свой формат, поэтому не все графические пакеты имеют полную поддержку RAW. После преобразования RAW-файл обычно сохраняют в TIFF или JPEG. Профессиональные фотографы предпочитают снимать именно в RAW, так как он позволяет контролировать многие параметры постобработки фотографии. Может использовать различные варианты сжатия, поэтому по размеру обычно больше чем JPG, но меньше TIFF.
DNG (Digital Negative — .dng) — формат файлов, разработанный Adobe Systems для создания единого стандарта для файлов RAW. Однако разработчики фотокамер пока не спешат его внедрять в свои устройства.
BMP (Bitmap — .bmp, .dib и .rle) — формат, созданный Microsoft, за счет чего в свое получил широкое распространение. Максимальный размер изображения 65535×65535 пикселей. В настоящее время относится к вымирающим видам. К тому же виду относится и аналогичный формат PCX, разработанный еще в эпоху MS-DOS, и хорошо сжимающий лишь простые рисунки.
Читайте также: