
Алгоритм сжатия файлов формата bmp и pcx
Первым был разработан формат PCX и предназначался для Paintbrush. Этот формат хранит точечные изображения в самом примитивном виде, однако он является самым малоконфликтным. Он используется во многих серьёзных программных продуктах, например, в большинстве издательских систем. Также есть в простых графических пакетах.
Формат BMP очень похож на PCX и имеет ту же идеологию и запись с разложением на битовые плоскости. В настоящий момент хранение изображений в формате BMP есть во всех графических пакетах. Растровые изображения разбиваются на строки и столбцы, и дальнейшее хранение выполняется построчно.
В этом формате можно хранить цветные и монохромные изображения. С тем, сколько разрядов и сколько цветов в картинке, проявляется разница в версиях формата.
Для обоих форматов:
1 – зелёный цвет
2 – красный цвет
Этот порядок нестандартный. Последовательно записаны биты плоскостей 0, 1, 2, 3.
1. В первых версиях всё сводилось к стандартной палитре в 256 цветов. Начиная с версий 3 – 4 палитру можно передавать вместе с файлом.
Имеет длину 128 байт.
Запись 1. Это идентификатор типа файла.
Запись 2. Версия формата. Версия 2.х – с передачей палитры, 3.х – без передачи палитры.
Запись 3. Уплотнение. Применяется RLE –метод сжатия.
Запись 4. Количество бит на пиксел.
Запись 5. Окно изображения.
Также смотри примечание.
Запись 6. Разрешение по горизонтали и вертикали (dpi).
Далее может следовать описание палитры (16×3 байт). Затем идёт число битовых плоскостей. Максимум 4, минимум 1.
Затем кодируется монохромное или цветное изображение по записанному числу: 1 – монохромное, 2 – градации серого. Другие уровни записи не допускаются. Далее следует резервная часть, которая до конца заполнена нулями.
ПРИМЕЧАНИЕ. Число строк должно быть кратно 8, а число точек в строке кратно 16. Если размер изображения не кратен, то выполняется дополнение до ближайшего кратного. При больших размерах изображения эти дополнения не влияют на размер файла. Добавленные участки заполняются нулями по всем битовым плоскостям. Уплотнение данных проводят по каждой плоскости отдельно по способу RLE. Особенность в том, что код уплотнён или неуплотнён – это 6-ой и 7-ой разряды.
В ряде случаев из-за применения такого способа сжатия возможен обратный эффект – размер файла может оказаться больше. Уплотнение фактически никогда не происходит, чтобы его выполнить, надо при сохранении файла отметить специальный флажок. Так же способ задания палитры зависит от конкретного типа графического адаптера (CGA, EGA, VGA).
Начиналось всё с CGA. Работает с 16 цветами. Соответственно полезная информация не может занимать полный байт. Записи разбиты на тройки. Для CGA в первом слове из трёх информацию несут 4 старших бита, это цвет фона. Все остальные игнорируются. Во втором слове информацию несут три разряда.
7-ой разряд: 0 – монохромное, 1 – цветное.
5-ый разряд: 0 – тёмный, 1 – светлый.
6-ой разряд. Цвета для смешивания:
0 – зелёный, красный, жёлтый.
1 – синий, белый, оттенок красного.
Таким образом можно получить 8 вариантов палитры на одном из 16 фонов.
Стандартные адаптеры EGA/VGA также используют 16 цветов, но их формируют совершенно по другому.
VGA – 16 цветов. Базовые цвета – красный, синий, зелёный. Используются все три байта записи. Количество уровней каждого цвета должно быть 4, чтобы формировать 16 цветов.
EGA. Значение каждого байта должно делиться на 4. Может принимать значения 0, 1, 2, 3. Два бита дадут 4 уровня яркости.
VGA (256 цветов). Образуют палитру по аналогии с EGA путём деления значения байта, только делится он на 4. Таким образом, формируется доля базового цвета, и получают стандартную палитру в 256 цветов. Если мы хотим работать с выбранными 256 цветами из 16777216 цветов, то в конце файла добавляется нестандартная палитра. С полным набором в 16777216 цветов формат PCX никогда не работает.
Если стоит монитор SVGA/XGA, то будут использоваться только 256 цветов. А выбор 256 цветов будет описываться в палитре, которая будет дописываться в конец файла.
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.

В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
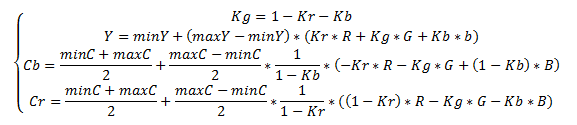
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц

Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.

На что при загрузке сайта расходуется больше трафика? Чаще всего это картинки, и их суммарный «вес» частенько в несколько раз больше, чем у разметки, скриптов и стилей. В файлах изображений распространенных форматов растровые данные хранятся в сжатом виде, и это значительно лучше, чем несжатый BMP. А если хочется ещё лучше? Ведь в достаточно крупных проектах каждый байт на счету (например, в TradingView, чего уж там скромничать).
Существует множество утилит для пережатия графики, от узкоспециализированных до всемогущих комбайнов. На хабре уже есть замечательный обзор таких программ, и вопрос, чем можно пережать картинку, рассмотрен более, чем детально.
Но как работают такие программы, что можно улучшить и как сделать свою? Приглашаю на обзорную экскурсию по форматам изображений и алгоритмам сжатия растровых данных.
Средневековье
Восьмидесятые годы прошлого столетия стали временем становления растровой графики. Графика как таковая применялась и раньше, но теперь она стала гораздо более доступна, и не в последнюю очередь на неё повлияла игровая индустрия. Atari 2600 позволяла рисовать нечто более изысканное, чем белый прямоугольник. А Commodore 64 обладал видеопамятью, с настоящими пикселями, и работать с ним было удобнее, чем «переключи цвет не позже 31415-го такта».
Нарисовать на экране Мону Лизу, выставляя пиксели вручную по хитрому алгоритму, трудновато. Да и не нужно, потому что из видеопамяти выдернуть кусок данных и сохранить его в файл, а потом из файла вставить. Такой дамп памяти в Бейсике делался командой BSAVE , а сам формат назывался в честь неё BSAVE'd. Редактировать изображения стало намного удобней, и расцвели пышным цветом простенькие графредакторы, большей частью неотличимые друг от друга.
Но некоторые из редакторов переросли детский возраст и стали весьма удобным и полезным инструментом. Так в 1984 появился PCPaint, в котором можно было рисовать при помощи мыши. Помимо очевидных удобств пользовательсого интерфейса PCPaint давал еще одно преимущество. Дело в том, что дамп BSAVE не включал данных о размере изображения, глубине цвета и палитре, и если видеорежимов было немного (да и цветное изображение вменяемо показывалось в черно-белом режиме) то для палитры приходилось использовать отдельный файлик PAL. В формате PIC редактора PCPaint содержались и палитра, и дамп BSAVE. Это маленький шаг для программиста и гигантский скачок для всего человества. Что-то вроде «а давайте придумаем формат MKV, в котором субтитры можно будет хранить внутри, и чтобы не нужно было их в нужную папочку класть».
Но еще одна проблема оставалась нерешенной: на PC есть BSAVE и на Apple есть BSAVE , но они генерируют файлы разного формата. Это и не удивтельно, внутреннее представление картинки в памяти различалось. Существовали транскодеры, но стало понятно, что долго эта вендор-зависимая кутерьма не продержится. В 1984 компания Truevision представила формат TARGA, более известный как TGA. А в следующем 1985 году свет увидела рисовалка PC Paintbrush. Хотя PC Paintbrush и продавалась хуже, её формат PCX, переносимый и достаточно простой, прожил дольше, чем PIC.
И в TGA, и в PCX данные о размере изображения и палитре хранились в явном виде, без сильной привязки к железу. Это стало возможным, потому как пиксельные данные перестали зависеть о конкретной платформы и представляли из себя просто сканлайны: слева направо, сверху вниз.
Но была ещё одна важная особенность у этих двух форматов, растровые данные в них хранились в сжатом виде. Применяемый алгоритм RLE не был верхом эффективности, но это было уже весьма неплохо.
RLE (Run length encoding) достаточно простой алгоритм, но он хорошо показывает, как работает сжатие данных. Сжать данные без потерь означает, избавиться от избыточности в них. Для этого берем набор данных, находим в них цепочки повторяющихся значений и заменяем их на нечто более компактное.
Обычно RLE переводят как «кодирование длин серий», и такие повторяющиеся значения именуют «серии». И хотя мне больше по душе перевод «прогон», ничего не могу поделать, это уже устоявшися термин.
Скорее всего, Вы уже пользуетесь им. Посмотрим на строку « AAAAAAAAAAAABBBAAAAAAAAA ». Если нам придется продиктовать её по телефону, то это будет звучать как «двенадцать заглавных букв A, три заглавные B, девять заглавных A». Если записать это, получится « 12 A 3 B 9 A », а чтобы не было разночтений, то « 9 A 3 A 3 B 9 A ». Гораздо компактнее.
Возьмем теперь другую строку, « 0KXQsNCx0YDQsNGF0LDQsdGA », и попытаемся её так сжать. Получится « 1 0 1 K 1 X …», стоп-стоп-стоп! Строка получается вдвое длиннее, чем исходная, это же ни разу не сжатие. Модифицируем алгоритм и добавим к цифрам буквы: буква A означает, что следующий символ пишется «как есть»; если B, то два; если C, то три, и так далее. Выходит « X 0KXQsNCx0YDQsNGF0LDQsdGA ». Итого, в лучшем случае мы получаем сжатие в 350%, а худшем случае мы теряем только 4%.
Разумеется, в реальных условиях кодируются обычно байты, а не буквы латинского алфавита, и длины последовательностей кодируются значениями от 0 до 255. Плюс к тому, обычно бессмысленные значения длин серий игнорируются: в нашем примере 1 и A делают одно и тоже, а 0 вообще смысла не имеет. Но это детали, суть остается одна и та же.
Энтропия
Как бы ни хотелось избежать теории, эта вещь слишком важная, чтобы её игнорировать. Вы заметили, что не все последовательности получается сжать? Строки AAAAAAAAAAAABBBAAAAAAAAA и 0KXQsNCx0YDQsNGF0LDQsdGA одной длины, 24 символа, но во второй эти символы более хаотичны, и её сжать труднее.
Чтобы проиллюстрировать это, обратимся к тому, что на первый взгляд не имеет отношения к IT.
Судоку слева содержит 81 цифру и уже решен. Тот, что посередине, содержит меньше информации, 26 цифр, но решив его, можно восстановить все исходные 81.
А вот с судоку справа все очень плохо — из него удалено слишком много данных, и он уже не решается, т.е., исходный набор данных мы уже не получим.
Но вернемся к PCX и займемся тем, чего уже лет десять никто не делал, создадим файл PCX, причем вручную. Знать свой инструмент нужно, поэтому обратимся с спецификации, и узнаем, что представляет из себя этот формат. Вот основные тезисы:
- Изображение может иметь размеры до 65536×65536. Палитра до 256 цветов, либо 24-битный цвет без палитры. Заголовок всегда размером 128 байт, содержит размер изображения, количество цветов и палитру до 16 цветов по одному байту на канал. Естественно, 256-цветовая палитра в такой заголовок не влезет, и если она есть, она дописывается в конец файла и имеет размер 769 байт (1 байт сигнатуры и 256×3 байт данных). Есть ещё поле для палитры CGA, но она более не поддерживается.
- «Сырой» поток данных состоит из сканлайнов — горизонтальных линий в один писель. Внутри каждого сканлайна может быть до 4 битовых плоскостей: R, G, B, A. Все плоскости пишутся последовательно: RRRRGGGGBBBBAAAA . Плоскости состоят из строго чётного количества байтов, и при необходимости к сырым данным дописываются заполнители, чтобы это условие выполнялось. Такие данные-заполнители при декодировании игнорируются.
- Сжатие «сырых» растровых данных производится построчно, при помощи RLE. «Построчно» означает, что серия RLE не может выходить за пределы битовой плоскости.
- В RLE байтовые значения от 192 до 255 кодируют количество повторений символа от 0 до 63 раз соответственно. Остальные значения — литеральные, если ни встречаются на том месте, где ожидается количество повторений, считается, что они повторяются один раз.
PCX на практике
Теперь давайте на примере разберем этот шмат технических данных. Возьмем для примера такую вот картинку (17×8, для удобства увеличена в 8 раз):
Определимся с палитрой. В изображении три разных цвета, поэтому нам подходят палитры из 4, 16 и 256 цветов, а также Truecolor. В 4-цветовой палитре у нас будет в одном байте 4 значения (8 бит байта поделить на 2 бита номера в палитре); в 16-цветовой — 2 пикселя на байт; в 256-цветовой — пиксель на байт (плюс 769 байт дополнительной палитры); в Truecolor — три байта на пиксель. Выбор очевиден, 4 цвета.
Цвета расположим, например, так:
Теперь выписываем битовые значения первой строки, начиная со старших битов. Листинг в четверичной системе, разделители — границы байтов.
0000 0000 0000 0000 0
Получается 4,25 байта. RLE с дробными байтами не работает, добиваем до пяти.
0000 0000 0000 0000 0 000
В документации сказано, что в сканлайне должно быть чётное количество байт. Делать нечего, добиваем ещё.
0000 0000 0000 0000 0 000 0000
То же самое проделываем с остальными строками, получаем:
0000 0000 0000 0000 0 000 0000
0111 1111 1111 1111 0 000 0000
0121 2121 2121 2121 0 000 0000
0212 1212 1212 1212 0 000 0000
0222 2222 2222 2222 0 000 0000
0202 0202 0202 0202 0 000 0000
0020 2020 2020 2020 0 000 0000
0000 0000 0000 0000 0 000 0000
Теперь посмотрим, какие значения можно сжать. Отметим только последовательности одинаковых байтов длиннее 2, потому что кодирование серии в 2 байта займет 2 байта, и смысла в этом особого нет.
0000 0000 0000 0000 0 000 0000
0111 1111 1111 1111 0 000 0000
0121 2121 2121 2121 0 000 0000
0212 1212 1212 1212 0 000 0000
0222 2222 2222 2222 0 000 0000
0202 0202 0202 0202 0 000 0000
0020 2020 2020 2020 0 000 0000
0000 0000 0000 0000 0 000 0000
Обратите внимание, что хотя нулевые байты в конце предпоследней строки так и просятся прицепиться к последней строке, этого сделать не получится, границу сканлайна пересекать нелья.
Теперь ход конём. В спецификации нигде не написано, чем именно нужно добивать сканлайны до чётного количества байт. Все равно, эти значения декодер выкинет. Поэтому можем сэкономить аж два байта, сделав вот так:
0000 0000 0000 0000 0 000 0000
0111 1111 1111 1111 0 000 0000
0121 2121 2121 2121 0 000 0000
0212 1212 1212 1212 0 000 0000
0222 2222 2222 2222 0 000 0000
0202 0202 0202 0202 0 202 0202
0020 2020 2020 2020 0 000 0000
0000 0000 0000 0000 0 000 0000
Закодируем получившееся в RLE. Пожалуй, будет удобней перейти к более привычному шестнадцатеричному виду:
00 00 00 00 00 00
15 55 55 55 00 00
19 99 99 99 00 00
26 66 66 66 00 00
2A AA AA AA 00 00
22 22 22 22 22 22
08 88 88 88 00 00
00 00 00 00 00 00
Кодируем первую строку. 6 байт 0x00 . Повтору 6 раз соответсвует значение 192 + 6 = 198 или C6 . После него пишем, какое же значение мы собираемся повторять 6 раз, получается 0xC6 0x00 . Первый сканлайн готов.
Далее три одинаковых байта становятся 0xC3 0x55 .
И в конце строки два нулевых байта, которые можно представить двумя способами: в лоб, 0x00 0x00 , или более хитро, 0xC2 0x00 . И так и сяк два байта. На девушек произвести впечатление хитрым приёмом вряд ли получится, а других причин делать вещи заковыристее, чем требуется, нету, поэтому берем просто 0x00 0x00 .
Продолжая подобным образом, получим:
PCX на практике 2: палитра
Возьмем теперь другое изображение и снова переведем его в PCX, пытаясь максимально сжать. На этот раз картинка поменьше, 7×5.
Это НЛО. Знаю, что не очень похоже.
Перво-наперво, выберем глубину цвета: 2 бита. Это четыре цвета, как раз, сколько нам и нужно. Определяем палитру, например, так:
Теперь очередь растровых данных. Второй раз утомительный процесс выписывания циферок производить не будем, сразу запишем сырые данные и то, что из них получилось, в шестнадцатеричном виде.
| Сырые данные | Сжатые данные |
| 0F C0 3A B0 FF FF D9 9C 3F F0 | 0F C1 C0 3A B0 C2 FF C1 D9 9C 3F C1 F0 |
Упс! Сжатые данные получились больше по размеру, чем исходные. Это потому, что значения от 0xC0 до 0xFF — это маркеры количества повторений, и их нельзя записать просто так. Вместо 0xC0 пришлось подставить C1 C0 , вместо 0xF0 — 0xC1 0xF0 и так далее.
В случае 0xFF 0xFF нам повезло — там мы драгоценных байт не потеряли. Но в целом выходит унылая картина: теперь RLE вместо того, чтобы помогать, только мешает.
В сторону безысходность, посмотрим, что с этим можно сделать. Маркерами являются байты с двумя старшими битами равными единице, 11XXXXXX. Данные пишутся последовательно, начиная со старшего бита. Зачит, при двухбитной глубине цвета на то, будет ли байт маркером или нет, влияют пиксели по смещению 4×n. А именно, пиксели цвета под номером 3 (в нашем случае, темно-серый).
Вот они, виновники разрастания размеров файла. В третьей строке темно-серые пиксели тоже попадают в выделенные колонки, но погоды они нам не делают: сама строка при кодировании даст два одинаковых байта.
Порядок цветов в палитре мы определяем сами, поэтому выберем в качестве цвета номер 3 тот, который меньше всего встречается по смещению 4×n. Синий — лучший кандидат, он не встречается на таких местах вообще ни разу. Переопределяем палитру и делаем вторую попытку.
| Сырые данные | Сжатые данные |
| 0A 80 25 60 AA AA B7 78 2A A0 | 0A 80 25 60 AA AA B7 78 2A A0 |
Сжатые данные оказались идентичны исходным. RLE это изображение пришлось не по зубам, но хотя бы нет и оверхеда. Так или иначе, растровые данные готовы, и это максимум, что можно выжать.
Итого
Еще раз вкратце техники, помогающие уменьшить вес PCX:
- Выбор минимально возможной глубины цвета (размера палитры);
- Оптимизация мусорных данных;
- Удаление бессмысленных данных (серии длиной 0);
- Оптимизация палитры.
Продолжение следует
Ну вот, пожалуй, и всё. Про TGA я рассказывать не буду, он хоть и отличается от PCX, но сходств гораздо больше, чем отличий. А других прямо уж примечательных графических форматов того времени и не было.
Кроме, конечно же, формата GIF компании CompuServe. В нем мы и покопаемся в следующий раз.
Одним из наиболее важных и определяющих аспектов как для хранения, так и для передачи является сжатие исходной информации. Форматы графических файлов: JPEG, BMP, PCX. Алгоритм архивации графики, дискретно-косинусное преобразование, этап квантования.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 12.03.2009 |
| Размер файла | 97,1 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
К КУРСОВОЙ РАБОТЕ
на тему: «Сжатие изображений»
по курсу «Цифровая обработка сигналов»
Содержание
1. ОБЗОР МЕТОДОВ СЖАТИЯ ИЗОБРАЖЕНИЙ
1.1 Общие понятия, связанные с изображениями
1.2 Требования к JPEG
1.3 Форматы графических файлов
1.4 Сравнительная характеристика алгоритмов сжатия
2 ВЫБОР И ОБОСНОВАНИЕ ВЫБРАННОГО МЕТОДА
2.1 Обоснование выбора метода сжатия изображения
2.2 Алгоритм архивации графики JPEG
2.2.1 Дискретно-косинусное преобразование
2.2.2 Этап квантования
2.2.3 Этап вторичного сжатия
3 РАЗРАБОТКА ПРОГРАММНО-АППАРАТНЫХ МОДУЛЕЙ
3.1 Разработка программного модуля на языке MatLab
3.2 Разработка программно-аппаратного модуля на языке С++
4 АНАЛИЗ ВЫЧИСЛИТЕЛЬНОЙ СЛОЖНОСТИ
5 РУКОВОДСТВО ПОЛЬЗОВАТЕЛЯ
ПРИЛОЖЕНИЕ А. Текст программы на MatLab
Введение
В 1990 году была завершена большая часть технических работ по разработке основных стандартов цифровых систем мультимедиа. Это дает возможность создавать интегрированные цифровые архивы, что в свою очередь будет способствовать развитию средств записи и хранения видео и аудио массивов информации в дополнение к имеющейся текстовой информации. При этом еще большее распространение получат цветные факсы, сканеры, принтеры; еще большим станет их быстродействие. Возникает обширное поле деятельности практически для каждой отрасли научной деятельности, связанной так или иначе с компьютерами: связь, системы обработки данных реального времени, параллельная обработка, разработка микросхем, объектно-ориентированное программирование, микропрограммирование и т.д.
Следует отметить, что одним из наиболее важных и определяющих аспектов как для хранения, так и для передачи является сжатие исходной информации. Большинство пользователей компьютерами уже знакомы со сжатием текстовой информации, позволяющей экономить место на дисках. Для текста необходима компрессия без потерь (нешумовая), если, конечно в дальнейшем потребуется восстановление текста. Такое сжатие обычно позволяет сократить занимаемое место в соотношении 2 : 1.
С другой стороны компрессия с потерями (шумовая) позволяет достичь значительно большего коэффициента - 1000 : 1, однако она применяется только в случае, когда условием ставится только визуальное распознавание изображения.
1 ОБЗОР МЕТОДОВ СЖАТИЯ ИЗОБРАЖЕНИЙ
1.1 Общие понятия, связанные с изображениями
Оцифрованный кадр цветного ТВ-изображения содержит информацию объемом порядка в миллион байт, а снимок на 35-миллиметровой фотопленке - где-то в десять раз больше. Это обширное количество данных - серьезное препятствие перед непосредственным использованием без предварительного сжатия оцифрованного изображения. Современные технические средства позволяют сжимать исходные изображения от 10 до 50 раз без заметного ухудшения их визуального качества. Технология сжатия не существует сама по себе. Для широкого применения систем сжатия информации то ли в целях передачи, то ли в целях хранения изображений, на рынке, куда поступают изделия от многих изготовителей, должен существовать определенный стандарт, позволяющий устройствам разных фирм работать совместно. Существующие ныне рекомендации Международного Телефонного и Телеграфного Консультативного Комитета (CCITT), известные под названием метода Группы 3, определяют условия работы только с двух градационными изображениями. За последние несколько лет был разработан стандарт JPEG, определяющий правила сжатия много градационных как полутоновых, так и цветных неподвижных изображений. Это результат сотрудничества ССITT и ISO (Международная Организация по стандартизации).
Использование компрессии позволяет:
снизить стоимость систем хранения и передачи информации;
увеличить количество каналов связи при сохранении заданной скорости передачи;
хранить больший объем информации;
облегчить сравнение хранимой информации (одинаковые участки данных, сжатые одним и тем же образом, не различаются и в компрессированном виде).
Методы сжатия изображений подразделяются на две большие группы:
в первой предполагается частично утраченная информация (сжатие изображений с потерями);
во второй - информация полная (сжатие без потерь).
В первом случае усеченная часть информации либо субъективно не будет заметна, либо, будучи замеченной, не окажет существенного влияния на восприятие информации в целом. Обычно такие методы применяются для передачи изображения и звука, исходя из особенностей нашего восприятия. Так, на движущемся объекте мы не замечаем мелких деталей, поэтому при сжатии видеозаписи быстродвижущихся предметов их можно не передавать и подробнее прорисовывать только на статичных картинах. Воспроизводя музыку, мы в момент звучания громкого инструмента не обращаем внимание на одновременно звучащий, но более тихий инструмент. Значит, при громком звучании можно не заботиться о качестве синхронных тихих звуков, а передавать их с высокой точностью лишь в моменты низкого уровня громкости. Методы сжатия с потерями позволяют достичь коэффициента десятикратного сжатия, но без значительного ухудшения качества изображения и звука. Наиболее известны сжатия с потерями в форматах JPEG для неподвижных изображений. Однако у десятикратного коэффициента сжатия есть оборотная сторона - это погрешности в записываемой информации.
Методы сжатия без потерь дают более низкий коэффициент сжатия, но зато сохраняют точное значение пикселов исходного изображения. Методы с потерями дают более высокие коэффициенты сжатия, но не позволяют воспроизвести первоначальное изображение с точностью до пиксела. Для файлов, создаваемых программами автоматизированного проектирования или электронных таблиц, очень важно сохранить всю информацию, потому что потеря хотя бы одного бита может изменить смысл всего файла. Совсем другое дело с растровыми данными. Человеческий глаз не воспринимает все тонкие оттенки цвета в обычном растровом изображении. Таким образом, некоторые детали могут быть опущены без видимого нарушения информационного содержания картинки.
1.2 Требования к JPEG
Визуально после сжатия изображение должно оцениваться как "отлично" или "хорошо" в сравнении с оригиналом; метод должен быть применим и удобен при практическом применении для любых многоградационных изображений; иметь невысокую расчетную сложность, что позволило бы избежать дополнительных аппаратных разработок и ограничиться лишь несложным программным обеспечением; JPEG должен иметь следующие режимы работы:
Последовательное кодирование: компоненты изображения кодируются слева направо, сверху вниз;
Прогрессивное кодирование: изображение кодируется при многократном сканировании, в случаях, когда время передачи велико;
Нешумовое кодирование: изображение кодируется с гарантией точного воспроизведения каждого элемента (даже, если это приводит к заметному снижению коэффициента сжатия);
Иерархическое кодирование: изображение разбивается и кодируется по многим уровням, причем нижние уровни могут быть доступны сразу и без предварительного декомпрессирования изображения на всех его уровнях.
1.3 Форматы графических файлов
Одна из основных технологий сегодня, заключается в хранении файлов растровой графики (bitmap file). В файле растровой графики содержится информация, необходимая компьютеру для воссоздания изображения. Мы с вами на экране можем увидеть красивое изображение заката солнца, но компьютер воспринимает эту картину в виде единиц и нулей. То, что делает компьютер с этими единицами и нулями, и позволяет воспроизвести первоначальное изображение. В конечном итоге биты и байты в растровом массиве (bitmap) сообщают компьютеру, в какой цвет окрасить каждый пиксел изображения. Затем компьютер преобразует цвета растрового массива в формат, совместимый с адаптером его дисплея, и передает этот формат аппаратуре вывода видеоизображения.
Вызывает интерес та часть процесса, где происходит преобразование данных в растровый массив. Существует несколько форматов файлов растровой графики, и каждый формат предусматривает собственный способ кодирования информации о пикселах и другой присущей компьютерным изображениям информации. Именно поэтому программа Paint, поставляемая в комплекте ОС Windows 95, совместима с BMP-файлами, но не может считывать файлы формата GIF. Создатели программы Paint наделили ее способностью декодировать графическую информацию, хранящуюся в формате BMP, но не сможет прочитать формат GIF
Распространенные форматы файлов растровой графики:
Макс. число бит/пиксел
Макс. число цветов
Макс. размер изображения, пиксел
Методы сжатия
Кодирование нескольких изображений
2'147'483'647 x 2 147 483 647
Deflation (вариант LZ77)
LZW, RLE и другие*
1.3.1 Файлы BMP
Формат файла BMP (сокращенно от BitMaP) - это "родной" формат растровой графики для Windows, поскольку он наиболее близко соответствует внутреннему формату Windows, в котором эта система хранит свои растровые массивы. Для имени файла, представленного в BMP-формате, чаще всего используется расширение BMP, хотя некоторые файлы имеют расширение RLE, означающее run length encoding (кодирование длины серий). Расширение RLE имени файла обычно указывает на то, что произведено сжатие растровой информации файла одним из двух способов сжатия RLE, которые допустимы для файлов BMP-формата.
В файлах BMP информация о цвете каждого пиксела кодируется 1, 4, 8, 16 или 24 бит (бит/пиксел). Числом бит/пиксел, называемым также глубиной представления цвета, определяется максимальное число цветов в изображении. Изображение при глубине 1 бит/пиксел может иметь всего два цвета, а при глубине 24 бит/пиксел - более 16 млн. различных цветов.
Файл разбит на четыре основные раздела: заголовок файла растровой графики, информационный заголовок растрового массива, таблица цветов и собственно данные растрового массива. Заголовок файла растровой графики содержит информацию о файле, в том числе адрес, с которого начинается область данных растрового массива. В информационном заголовоке растрового массива содержатся сведения об изображении, хранящемся в файле, например, его высоте и ширине в пикселах. В таблице цветов представлены значения основных цветов RGB (красный, зеленый, синий) для используемых в изображении цветов. Программы, считывающие и отображающие BMP-файлы, в случае использования видеоадаптеров, которые не позволяют отображать более 256 цветов, для точной цветопередачи могут программно устанавливать такие значения RGB в цветовых палитрах адаптеров.
Формат собственно данных растрового массива в файле BMP зависит от числа бит, используемых для кодирования данных о цвете каждого пиксела. При 256-цветном изображении каждый пиксел в той части файла, где содержатся собственно данные растрового массива, описывается одним байтом (8 бит). Это описание пиксела не представляет значений цветов RGB, а служит указателем для входа в таблицу цветов файла. Таким образом, если в качестве первого значения цвета RGB в таблице цветов файла BMP хранится R/G/B=255/0/0, то значению пиксела 0 в растровом массиве будет поставлен в соответствие ярко-красный цвет. Значения пикселов хранятся в порядке их расположения слева направо, начиная (как правило) с нижней строки изображения. Таким образом, в 256-цветном BMP-файле первый байт данных растрового массива представляет собой индекс для цвета пиксела, находящегося в нижнем левом углу изображения; второй байт представляет индекс для цвета соседнего справа пиксела и т. д. Если число байт в каждой строке нечетно, то к каждой строке добавляется дополнительный байт, чтобы выровнять данные растрового массива по 16-бит границам.
Структура файла BMP:
1. Заголовок файла растровой графики (14 байт) Сигнатура файла BMP (2 байт) Размер файла (4 байт) Не используется (2 байт) Не используется (2 байт) Местонахождение данных растрового массива (4 байт)
2. Информационный заголовок растрового массива (40 байт) Длина этого заголовка (4 байт) Ширина изображения (4 байт) Высота изображения (4 байт) Число цветовых плоскостей (2 байт) Бит/пиксел (2 байт) Метод сжатия (4 байт) Длина растрового массива (4 байт) Горизонтальное разрешение (4 байт) Вертикальное разрешение (4 байт) Число цветов изображения (4 байт) Число основных цветов (4 байт)
3. Таблица цветов (длина изменяется от 8 до 1024 байт)
4. Собственно данные растрового массива (длина переменная)
1.3.2 Файлы PCX
PCX стал первым стандартным форматом графических файлов для хранения файлов растровой графики в компьютерах IBM PC. На этот формат, применявшийся в программе Paintbrush фирмы ZSoft, в начале 80-х гг. фирмой Microsoft была приобретена лицензия, и затем он распространялся вместе с изделиями Microsoft. В дальнейшем формат был преобразован в Windows Paintbrush и начал распространяться с Windows. Хотя область применения этого популярного формата сокращается, файлы формата PCX, которые легко узнать по расширению PCX, все еще широко распространены сегодня.
1.3.3 Файлы JPEG
Формат файла JPEG (Joint Photographic Experts Group - Объединенная экспертная группа по фотографии, произносится "джейпег) был разработан компанией C-Cube Microsystems как эффективный метод хранения изображений с большой глубиной цвета, например, получаемых при сканировании фотографий с многочисленными едва уловимыми (а иногда и неуловимыми) оттенками цвета. Самое большое отличие формата JPEG от других рассмотренных здесь форматов состоит в том, что в JPEG используется алгоритм сжатия с потерями (а не алгоритм без потерь) информации. Алгоритм сжатия без потерь так сохраняет информацию об изображении, что распакованное изображение в точности соответствует оригиналу. При сжатии с потерями приносится в жертву часть информации об изображении, чтобы достичь большего коэффициента сжатия. Распакованное изображение JPEG редко соответствует оригиналу абсолютно точно, но очень часто эти различия столь незначительны, что их едва можно (если вообще можно) обнаружить.
Процесс сжатия изображения JPEG достаточно сложен и часто для достижения приемлемой производительности требует специальной аппаратуры. Вначале изображение разбивается на квадратные блоки со стороной размером 8 пиксел. Затем производится сжатие каждого блока отдельно за три шага. На первом шаге с помощью формулы дискретного косинусоидального преобразования фуры (DCT) производится преобразование блока 8х8 с информацией о пикселах в матрицу 8x8 амплитудных значений, отражающих различные частоты (скорости изменения цвета) в изображении. На втором шаге значения матрицы амплитуд делятся на значения матрицы квантования, которая смещена так, чтобы отфильтровать амплитуды, незначительно влияющие на общий вид изображения. На третьем и последнем шаге квантованная матрица амплитуд сжимается с использованием алгоритма сжатия без потерь.
Поскольку в квантованной матрице отсутствует значительная доля высокочастотной информации, имеющейся в исходной матрице, первая часто сжимается до половины своего первоначального размера или даже еще больше. Реальные фотографические изображения часто совсем невозможно сжать с помощью методов сжатия без потерь, поэтому 50%-ное сжатие следует признать достаточно хорошим. С другой стороны, применяя методы сжатия без потерь, можно сжимать некоторые изображения на 90%. Такие изображения плохо подходят для сжатия методом JPEG.
При сжатии методом JPEG потери информации происходят на втором шаге процесса. Чем больше значения в матрице квантования, тем больше отбрасывается информации из изображения и тем более плотно сжимается изображение. Компромисс состоит в том, что более высокие значения квантования приводят к худшему качеству изображения. При формировании изображения JPEG пользователь устанавливает показатель качества, величине которого "управляет" значениями матрицы квантования. Оптимальные показатели качества, обеспечивающие лучший баланс между коэффициентом сжатия и качеством изображения, различны для разных изображений и обычно могут быть найдены только методом проб и ошибок.
1.4 Сравнительная характеристика алгоритмов сжатия
В данном разделе были описаны методы сжатия изображений с потерей данных и без потерь. Перечень приведенных алгоритмов далеко не полон, но, дает представление об основных тенденциях развития алгоритмов архивации статических растровых изображений. Во-первых, это ориентация на фотореалистичные изображения с 16 миллионами цветов (24 бита). Во-вторых, использование сжатия с потерями, возможность за счет потерь регулировать качество изображений. В-третьих - использование избыточности изображений в двух измерениях. В-четвертых - появление существенно несимметричных алгоритмов. И, наконец, что для нас важнее всего - увеличивающаяся степень сжатия изображений.
Сейчас не редкость создание базы данных, хранящей изображения, активное использование изображений в программах. Критичность их размеров дает себя знать довольно быстро, поэтому резонно применить один или несколько алгоритмов сжатия. Возможно, идеальным решением будет воспользоваться парой-тройкой новых универсальных алгоритмов, а может быть, стоит разработать специальный. Для электронных фотографий из досье, отпечатков пальцев, рентгеновских снимков созданы специальные алгоритмы, обеспечивающие сжатие до 1000 раз. Если планируется создание большой многогигабайтной базы данных, содержащей однородную информацию, то уменьшение ее хотя бы в 10 раз - это уже серьезно.
При выборе алгоритмов важно понимать их положительные и отрицательные стороны. Если выбран алгоритм с потерей данных, то стоит понять его природу и условия, при которых изображения будут портиться. Использование новых оптимальных алгоритмов позволит сохранить качество изображений, десятки и сотни мегабайт дискового пространства, уменьшит трафик в сети. Методы сжатия развиваются очень быстро. Ежегодно появляются новые алгоритмы и десятки модификаций известных
2 ВЫБОР И ОБОСНОВАНИЕ ВЫБРАННОГО МЕТОДА
2.1 Обоснование выбора метода сжатия изображения
В данном курсовом проекте реализуется сжатие изображений на основе дискретного косинусного преобразования, (дискретное косинусное преобразование используется в широко распространенном стандарте сжатия изображений - JPEG). Рассмотрим сравнительную характеристику выше рассмотренных алгоритмов сжатия изображений (таблица 2.1).
У меня образовался дисплейчик от нокии 3310. Монохромный. 84 х 48 пикселей.
Пока еще его не подключал. Только напаял проводочки.
Сегодня думал — в каком формате хранить картинки. Если записывать без сжатия по 1 биту на пиксель, то один кадр занимает 504 байта. Для отображения пары картинок оно конечно уместно, а вот если хочется записать в МК анимацию или еще что, то будет фейл.
Стал думать над тем, как-бы сжать картинку, чтобы при этом на распаковку тратилось минимум времени и сил. Первое, что пришло на ум — PCX. Это такой древний, как MS-DOS, формат изображений.
Суть в следующем: вместо того, чтобы писать подряд цвета для каждого пикселя, мы запишем сколько пикселей одного цвета идут друг за другом и цвет этой пачки.

Например, вот эта прекрасная картинка:
Будет сжата, и записана как:
1 пиксель белого, 1 черного, 3 белого, 4 черного.
PCX умеет работать с восьмибитной палитрой, но для нас это слишком много — хватит и одного бита. Остальные 7 бит оставляем на запись длины цепочки одноцветных пикселей.
Еще понадобится записать разрешение картинки, без него восстановить её обратно будет невозможно. И общую длину данных, не считая заголовка. В итоге имеем вот такой формат:

Для преобразования из bmp в наш монохромный PCX написал (точнее, дописал) вот такую утилиту:

Работает просто, как топор:
Нажимаем открыть, выбираем bmp (не больше 255х255 и монохромный). Он тут-же сжимается. Можно тыкнуть кнопку «Массив (pascal)» и получить готовый листинг для МикроПаскаля, типа такого:
Так-же можно нажать кнопку «сохранить» и записать данные в .bin файл.
Алсо, утилта умеет отображать свои сжатые картинки — надо при открытии выбрать тип файла «Binary».
Алгоритм сжатия выглядит так:
Для проверки качества сжатия взял 8 разных картинок. Все они имеют разрешение 84х48 пикселей, и несжатый размер 504 байта (без служебной информации).
Как и следовало ожидать, сжатие черного квадрата проходит лучше всего — 37 байт вместе с заголовком. Win!
Две линии и овал сжались до 138 байт. Кстати, листинг, который висит выше — от этой картинки.
Эмблема этой вашей игры про паркур ужалась до 186 байт.
Попытка уменьшить мою мою эмблемку до 48 пикселей по вертикали привела к тому, что надпись зафейлилась.
А после сжатия в PCX она стала весить 277 байт.
Корявая такая надпись. После сжатия весит 305 байт.
Матан после преобразования стал весить 329 байт.
А вот плакат «НЕ ТУПИТЬ» наоборот — вырос до 574 байт.
Сжатие сеточки с ячейкой в 1 пиксель приводит к фейлу.
После «сжатия» она стала весить 3989 байт. Тоже самое случится, если сжимать вертикальную штриховку.
Алгоритм сжатия можно сделать чуть более интеллектуальным. К примеру, если размер файла после сжатия > исходного, то записать, вместо сжатых, исходные данные, изменив сигнатуру (первый байт в массиве), или попробовать другой метод сжатия. Естественно, что на стороне МК алгоритм распоковщика должен быть готов к разным форматам данных.
А пока у меня есть довольно простой алгоритм, который сжимает bmp в полтора-два раза, без потерь. А главное, сжатая картинка шустро распаковывается. Вот так:
Это кусок кода из той-же утилиты. Распаковщик для МК я пока не писал — как разберусь с дисплеем, возьмусь за него.
В приложении к статье — утилита и тестовые картинки.
Комментарии ( 30 )
RLE это называется. Еще как минимум в BMP и TGA юзается. Самый простой алгоритм, чем и радует. Можно еще попробовать препроцессинг строк аля PNG сделать. Не слишком накладно, но вполне можно сделать сжимабельной если не сетку, то хотя бы полосы — полноценно кодироваться будет только первая строка, остальные выродятся в нули.
это больше подходит не для анимаций, а для массива картинок. для анимации выгоднее записывать отличия от предыдущего кадра.
Отличия, как правило, тоже нужно чем-то сжимать. Учитывая, что они в основном состоят из нулей — RLE вполне неплохо справляется.
Алсо, 7 бит на длину наверное лишку для таких маленьких картинок. Правда, следущее удобное значение — 3, а этого уже маловато (картинка будет весить от 0.5 до 4 размеров исходной). Можно еще 5 попробовать.
Вертикальная штриховка кстати будет весить еще больше сеточки. 4032 байта плюс заголовок — 4037.
И еще мелкая оптимизация. Поскольку цепочка не может иметь нулевую длину — можно кодировать длины от 1 до 128, а не 0..127 (здесь малозаметно, а вот при меньшем размере поля длины — более актуально).
Комп у нас шустрый-шустрый. Вполне может попробовать разные алгоритмы сжатия — разное количество бит на длину, разное направление сканирования (горизонтальное/вертикальное). С каким получится компактнее — тот и оставить, не забыв поменять сигнатуру.
Вот только картинру с вертикальной разверткой будет писец как неудобно на дисплей выводить.
ну-ну… учитывая что обычная его настройка в горизонтальном направлении выводить столбцы по 8 пикселей. собственно отсюда по моему и пошло то, что для него шрифт делают 6х8 пикселей.
Кстати, о шустроте. Более 99% времени комп у тебя занимается вычислением вызова Pixels[i, j]. Подумай в сторону использования ScanLine.
Знаю. Но все равно размер картинки маленький и обработка выполняется почти моментально. Другое дело, если размер будет больше.
Не такая уж бредовая идея. Скорее наоборот — вполне годная.
И распаковка опять-же не сильно усложняется.
Надо будет опробовать. Спасибо.
да этот сайтик с библиотекой машкова один из старейших сайтов в рунете и в мире, он по моему существовал с 1996 года.
Есть кстати еще алгоритмы сжатия графики для факсов. Они ориентированы на сжатие черно-белой картинки и (я так думаю) на работу в достаточно ограниченных аппаратных условиях. Стоит и на них взглянуть.
Я бы сделал самое простое изменение — сделал бы изменяемой длину записи количества одинаковых пикселей. От 0 до 7 или 8 бит.
Программа на PC тупо сжимает всеми вариантами и узнает длину, при которой результат меньше всего.
Это требует добавления функций побитового чтения/записи. Варианты, где одна запись укладывается в 4 или 8 бит тем и хороши, что с ними проще работать. 6 бит — чуть хуже, но его тоже можно декодировать фиксированной процедурой 3-в-4.
Кстати, есть ведь и реализации LZ, у которых декодер весит порядка 200 байт (в варианте для х86) — LZO например. Правда, они обычно просят память под входной и вызодной буферы, но они могут и частично перекрываться.
Можно и еще оптимизировать. Например для 4-бит кода сделать значения 1-15 — соответствующее число точек одного цвета, далее цвет меняется на противоположный, а 0 означает 15 точек одного цвета, далее цвет продолжается. Выигрышь в сжатии гарантирован.
Читайте также: