
1с журнал регистрации последовательный формат или sqlite
Новый формат журнала регистрации был реализован в платформе 1С:Предприятие 8 в версии 8.3.5.1068. Начиная с этой версии при создании новой информационной базы журнал регистрации будет храниться в одном файле базы данных SQLite с расширением .lgd, который располагается:
- Для файлового варианта информационной базы – в подкаталоге 1Cv8Log каталога информационной базы.
- Для клиент-серверного варианта информационной базы – в подкаталоге 1Cv8Log каталога информационной базы в каталоге служебных файлов кластера. Имя каталога можно определить по файлу реестра данных кластера.
Целью переработки журнала регистрации и перевода его в новый формат было увеличение скорости выполнения запросов к нему и повышение надежности хранения данных. Новость об этом была размещена на официальном ресурсе фирмы 1С. Обновление платформы до версии 8.3.5.1068 и выше не приводит к автоматическому переводу журнала регистрации в новый формат у уже созданных информационных баз. Но при этом имеется возможность смены формата на новый штатными средствами платформы. Для этого следует открыть диалог настройки журнала регистрации (Главное меню –> Администрирование –> Настройка журнала регистрации) и нажать кнопку «Новый формат».

Проблемы при работе с новым форматом журнала регистрации
Итак, одна из проблем возникает после перезапуска кластера серверов или аварийного завершения работы менеджера кластера. При этом возможно разрушение структуры файла журнала регистрации .lgd. При попытке открыть такой журнал регистрации происходит ошибка:
sqlite3_step failed: database disk image is malformed
Также иногда можно заметить проявление следующей ошибки при попытке в конфигураторе открыть файл журнала регистрации нового формата:
sqlite3_exec failed: attempt to write a readonly database
Еще одна ошибка связана с медленной работой или зависанием на записи в журнал регистрации, использующим новый формат. В технологическом журнале, при этом, можно увидеть следующие записи:
81029657-3fe6-4cd6-80c0-36de78fe6657: Передача данных прервана по инициативе принимающей стороны.'
Данная строка ТЖ говорит о том, что процесс rmngr центрального сервера не отвечает, так как занят работой с журналом регистрации. И далее в технологическом журнале можно видеть следующие записи:
0,EXCP,0,process=rmngr,p:processName=RegMngrCntxt,p:processName=ServerJobExecutorContext,Exception=81029657-3fe6-4cd6-80c0-36de78fe6657, Descr='src\RMngrCalls.cpp(549):
81029657-3fe6-4cd6-80c0-36de78fe6657:server_addr=tcp://[сервер]:[порт] descr=Сервер недоступен (Не отвечает, завершается аварийно или порт занят другим приложением) line=1073 file=src\DataExchangeTcpClientImpl.cpp'
Помимо этого, достаточно часто возникает проблема с высоким потреблением памяти журналом регистрации в новом формате. Данное поведение проявляется, например, если кто-то из пользователей случайно запустит выборку по ЖР без ограничения по периоду. При этом весь журнал регистрации попадет в память, вытеснит весь кэш и "положит" сервер.
Данные проблемы являются достаточно критичными и при их проявлении рекомендуется перевести журнал регистрации в старый формат.
Перевод журнала регистрации в старый формат
Штатные средства платформы 1С не позволяют перевести журнал регистрации из нового формата в старый. Здесь мы опишем способ, который позволит выполнить данную задачу вручную. Итак, для начала необходимо остановить службу 1С. При этом, необходимо согласовать данное действие с пользователями, так как при этом они не смогут работать с информационными базами, которые находятся в соответствующих кластерах 1С.

После того как служба 1С остановлена, переходим в каталог файлов информационной базы для которой необходимо изменить формат журнала регистрации. Данный каталог выглядит следующим образом:
…\1cv8\[каталог служебных файлов службы 1С, обычно srvinfo]\reg_ + [номер порта менеджера кластера]\[UUID информационной базы]
Уникальный идентификатор информационной базы (UUID) можно получить из файла «1CV8Clst.lst», который располагается в каталоге реестра кластера. Для быстрого получения идентификаторов баз и их имен из файла реестра кластера можно воспользоваться следующим регулярным выражением:
Далее в каталоге файлов информационной базы ищем папку «1Cv8Log» и переносим оттуда все файлы в отдельный каталог. Затем в папке «1Cv8Log» создаем пустой файл журнала регистрации в старом формате «1Cv8.lgf».
После того как все этапы данной процедуры выполнены, запускаем службу 1С. Готово, теперь журнал регистрации переведен в старый формат. Чтобы обратно вернуться к новому формату ЖР воспользуйтесь инструкцией, описанной во введении данной статьи.
Заключение
В статье мы постарались описать возможные проблемы при работе с новым форматом журнала регистрации. Такие проблемы чаще всего возникают на предприятиях с большим числом пользователей 1С. Далее мы описали способ перехода с нового формата на старый. Это может быть полезно, так как на данный момент не существует стандартных средств, предоставляемых платформой 1С, которые бы позволили это сделать.
Надеемся, вы сможете с легкостью выполнить нужную вам задачу и продолжите с удовольствием пользоваться продуктами 1С. Ну а если у вас что-то не получится, или вы столкнетесь с какими-то трудностями, обращайтесь к нам, мы обязательно поможем!
1C:Предприятие поддерживает два формата ведения Журнала регистрации: SQLite (файлы с расширением .lgd) и последовательный (набор файлов с расширениями .lgf, .lgp и.lgx). К настоящему времени Компания 1С провела значительную оптимизацию работы ЖР в последовательном формате. Мы рассматриваем возможность прекращения поддержки формата Журнала регистрации SQLite (файлы с расширением .lgd) и поддерживать работу только с последовательным форматом. Прежде чем принять это решение мы хотим собрать информацию от пользователей наших продуктов, чтобы сделать возможный процесс отказа от SQLite наиболее безболезненным.
Как считаете, в нём есть необходимость?
во всех случаях когда приходилось настраивать логи, резать и копаться в них - приходилось использовать "старый" формат.
бывало когда базы доставались в наследство с новым, или просто забывали поменять - было печально при попытках что-то отыскать.
(13) ЖР сделали как недо-ТЖ и по засратому вусмерть логу долго искать было. Чья-то "светлая" голова сказала - "так давайте БД прикрутим! Я слыхал там быстро ищет".
Его сделали чтобы индекс самим не строить. Но потом одумались и осилили индекс и для текстового файла
(23) Для агрегаторов логов хоть что угодно прикручивай. На здоровье. А для первичных логов только плоские файлы имеют право на существование.
(30) Может, встроенный механизм работы с ЖР недостаточно эффективный и компы, на которых с ним работают, не соответствуют поставленной задаче.
текстовый файл никак не может быть лучшим решением - ибо он не структурирован.
а жр очень даже структурирован
(30) а зачем нужны цельнотекстовые файлы логов в 100 Гб?
какая религия запрещает эти файлы дробить по годам, месяцам, дням в конце концов до достижения адекватного размера?
(30) Никто не логирует в один мегафайл. Его банально неудобно сопровождать. Настраивается разбиение по файликам-периодам в зависимости от нагруженности базы.
(41) Ну первичное - это непосредственный лог программы. Локально на хосте где работает программа в плоский файл. Это максимально быстро и максимально надежно. Поэтому именно так. Логи должны быть источником информации о сбоях, а не причиной сбоев. Но это ясен пень не очень удобно для централизованного анализа. Поэтому в серьезных системах эти данные из первичных логов (часто с разных хостов) подсасывают в системы агрегации логов имеющие внутри какие-нить БД где уже и индексация и анализ и сопоставление по каким хочешь критериям и с разных хостов удобно взаимовлияющие логи сопоставлять и вся хурма короче.
(43) + Поэтому первичные логи еще часто бьют на файлики по периодам и автоудаление старых периодов настраивают, не очень глубокое. В итоге они не могут быть даже причиной сбоев по причине переполнения диска. А в агрегаторах уже держат нужной глубины.
Пусть будет, я считаю.
Только спецификацию формата желательно открыть полностью. Да, и последовательного формата тоже.
Многопоточность есть при поиске по ЖР, в клиент-серверном варианте? Искать, когда известна дата, хотя бы месяц, несложно. А когда надо за год найти, что делали с документами и файлы журнала за месяц 10-15 ГБ, то будет совсем небыстро.
Если нет, надо предусмотреть. Пересчет итогов же сделали многопоточным, в 8.3.20, кажется..
(43) >> в серьезных системах эти данные из первичных логов (часто с разных хостов) подсасывают в системы агрегации логов имеющие внутри какие-нить БД где уже и индексация и.
Кстати говоря, наилучшим вариантом был бы как раз какой-нибудь конвертер от 1С, который позволял бы конвертировать последовательные текстовые логи в формат БД. Быть может даже с возможностью выбора разных форматов СУБД и полноты выгружаемых данных.
Только ждать такого решения от 1С не приходится. Т.к. 99% пользователей вполне удовлетворяет текущий журнал. Оставшийся 1% сами выкручиваются или не являются для 1С целевой группой ради которой стоит сильно заморачиваться.
(0) на поверку ЖР под SQLite оказался узким местом, снижающим производительность всей системы. Они изначально был ошибкой эволюции
они хотели ускорить чтение ЖР, но подзабыли, что ещё есть скорость записи в ЖР
ЖР надо разделить на два. Один, в который пишутся события до логина - сделать как сейчас. Второй - должен хранится в самой базе, используя механизмы нативной СУБД. Чтобы при восстановлении из бэкапа или переносе sql-базы не терялись события.
(58) Цитата из статьи по ссылке.
". скорость однопоточной записи тоже немного ускорилась. А вот скорость многопоточной записи возросла почти в полтора раза. Как в файловом варианте, так и в клиент-серверном."
Возникают вопросики. Как тестировали? Что изменилось?
Ведь судя по той статье SQLite явно должен был выигрывать по сравнению с последовательным форматом.
Причем даже человеческой возможности переключиться на файловый формат не было. Только подкладыванием пустого файла с нужным расширением. Мол скулайт - наше все, а файловый формат - это прошлое.
А теперь упс - нет. Таки будущее.
Во первых они не умеют готовить sqlite, даже режим wal не включили, а он дает резкое ускорение записи.
Во вторых они не прочитали в руководстве по sqlite что по сети его использовать нельзя - база может разрушится.
Да, я знаю что запускать файловую по сети это редкое извращение, но некоторые ххх же так работают!
В третьих можно было бы новый гибридный формат lgp/lgx и в sqlite реализовать, т.е. писать сырые данные в таблицу без индексов, а потом раскидывать по разным таблицам уже по фэншую.
Блин. Ну когда же 1с сделает хранение ЖР в основной базе, а не отдельно от неё? Это же напрашивается просто!
Трое суток журнал восстанавливал прошлый раз после сбоя. Слетел при обновлении платформы. Что-то они там недоперемудрили.
В backbas.dll в составе 1С:Предприятие 8.3 (8.3.6.2299) стоят такие прагмы:
The WAL journaling mode uses a write-ahead log instead of a rollback journal to implement transactions.
The OFF journaling mode disables the rollback journal completely. No rollback journal is ever created and hence there is never a rollback journal to delete. The OFF journaling mode disables the atomic commit and rollback capabilities of SQLite.
(14) Внутри DLL backbas.dll - хотя наверное правильнее 1С попросить, это только моя гипотеза. Или в настройку это вынести.
Если я правильно понимаю, WAL применяется в MS-SQL и в других базах данных, чтобы при выключении питания и других сбоях можно было откатить неудачную транзакцию.
(29)
Для чтения тоже быстрее простого файла ничего нет. А вот для анализа.
Во всем мире логи кидают в текстовые файлы, а потом конвертят их по мере надобности в любой приемлемый формат, одна 1С, как всегда, идёт поперёк.
Я вообще не понимаю, как они умудряются запороть файл базы данных sqlite, который вообще-то один из самых надежнейших форматов.
(33) Журнал регистрации для бэкапа не менее ценен, чем данные в базе. А при фатальной ошибке с базой смысла читать лог практически нет.
(17) Сейчас попробую написать.
(27) Частенько использую текстовый лог, но в 1С и с ним проблема (хотя можно извернуться через FileSystemObject).
Требуется отбор по пользователям, кто чего менял, тут с базой, наверное, ловчее. Я бы завел по месяцам, 12 баз в год.
(30) Есть же версионирование как внешняя примочка? ВерсииОбъектов, ВерсионированиеОбъектов etc.
(38) То есть, нельзя на sql-сервере произвести запись в таблицу вне текущей транзакции? Если так, то да, проблема.
(39) Это должно было быть сразу, и тогда бы никому журнал регистрации не нужен был, максимум - вход - выход фиксировать
(41) По идее да. Если клиент откроет два сеанса на sql-сервере, один для работы с данными, второй - для протоколирования, то транзакции мешать вести лог не будут.
Предложил сделать (13) или вынести это в административные настройки: тогда, я думаю, это обеспечит требуемую для высоко-нагруженных баз степень надежности - а для кого критична скорость, тот поставит PRAGMA journal_mode = OFF. И проблема SQLite, если я правильно ее вижу, будет решена.
(2) >> когда же 1с сделает хранение ЖР в основной базе, а не отдельно от неё? Это же напрашивается просто!
СУБД не совсем подходит для ведения журнала. Используя ее мы платим за то что не будем использовать. Это связано с особенностями нагрузки, которая характеризуется огромным и последовательным по времени трафиком на запись, минимальными изменениями данных и сильно разреженными выборками. (SQLite был выбран в качестве компромисса между субд (клиент-серверной) и хранениями в файлах. Кроме того для файлового варианта использование СУБД вообще чуждо.
Решение перехода на SQLite связано с фундаментальными проблемами в старом журнале регистрации. В частности долгие выборки по любым запросам.
(47) А интересно если разрезать журнал по месяцам - это же будет еще лучший компромисс. Например когда диск подойдет к заполнению, можно будет переместить старые месяцы. Не будет разрастания баз и их индексов.
(47) Для файловой sql-журнал вообще не уместен, особенно при многопользовательском доступе. Тут текстовые файлы рулят. А для клиент-серверной - почему бы и нет, если мощностей сервера хватает? Можно в конце концов сделать это опцией.
(50) Вот именно, и за этот файл конкурируют на запись куча клиентов, в каждом свой "встроенный сервер sqlite". Это такое же зло, как и 1cd по сети.
(51) SQLite ставит блокировку на файл. Блокировка может быть сделана корректно (с паузами) - думаю, что там это так и есть, и тогда не должно быть «плохой конкуренции» между клиентами, потоками сервера и т.д., которые одновременно пытаются что-то писать. Тут для 1С 7.7 я делал патч:
Книга знаний: Исправление ошибки 1С:Предприятие 7.7/8.0 - 100% загрузка процессора при ожидании блокировки
(52) А у сервера много потоков исполнения может быть, там тоже конкуренция (хочется надеяться, что там она корректная и, так сказать, честная).
Текстовый лог бы тоже делали с блокировками на файл (обычно его называют *.lck, хотя может быть что-то еще). Сервер 1С может распедаливать ожидание конкурирующих потоков через другие механизмы, файлы блокировок - самый древний образец такого межпроцессного взаимодействия.
(57) С блокировкой файла трудно ошибиться, но я подозреваю, что в 1С еще какая-нибудь Прагма отключает еще и это. :-)
(57) Там еще несколько опций, насколько я понимаю, WAL - это то, что делает MS-SQL со своей базой (гарантируя при этом безошибочный откат транзакций). И там компромисс между двукратной записью и полным отсутствием защиты. :-)
(58) А это смотря с какой целью: если вы хотите отобрать события по объекту (документу, элементу справочника) или пользователю, то ничего быстрее СУБД с индексами придумать в принципе нельзя, даже при неограниченном ресурсе ОЗУ. АВЛ-деревья не спроста же придумали в далеком-далеком СССР.
(2) Лучше бы 1С разрешила писать запросы на языке хранилища БД. если это SQL, то пишется на SQL, английскими буковками, используя только транскрипцию Реквизитов, как это было реализовано у 1С++ :)
(32) Вот ты не поверишь. Но я столкнулся с системой, где вот такой подход приводит только к тому, что анализировать Лог просто нереально долго :)
. Идея от 1С писать в SQLlite приветствуется, но все же встает вопрос, почему не было реализовано в составе БД?
Зачем было придумывать костыль?
Да, может для файловой БД, это и приемлемо. А вот для других версий, SQL и .т.д. уже трагично глупо со стороны 1С :)
Кстати, в своё время реализовал хранение жр в отдельной сиквельной базе. Прям все летало. Потом с переходами-переездами как-то потерялось.
А насчёт хранения в БД - версионирование этож тот же лог изменений.
(64) Версионирование средствами прикладного решения - костыль. Это должна обеспечивать платформа независимо от прикладного решения.
(63) Логи разрастаются - это первое, что хочется куда-нибудь вынести, обрезать/сократить и так далее. Например, в ситуации когда на диске кончилось место и надо что-нибудь предпринять.
(68) Точно. Как в банковских калькуляторах у кассиров. Все расчеты печатаются на ленте. Что там умножал и делил - всё можно раскрутить потом.
(67) Потеря базы - это полный аншлаг и все бегают ищут копии, а за потерю логов на практике даже не журят. Ну вот потерялись у нас целых 3 раза, и вроде пока все тихо. То есть, у них ценность другая, а размеры при этом могут быть сопоставимы с основной базой, все эти десятки гигабайт не хочется ежедневно бэкапить. Хотя, в каких-то применениях эти данные могут быть важны, но в этих случаях почему бы не хранить полную историю важных документов через Версионирование 1С.
(59)
С чего бы это?
Никак это размер файла не ограничивает. Просто отображать будешь "скользящим окном".
А вообще как и что с логами делается - во всём цивилизованном мире давно уже решили, одни одинэсники не знают, куда приткнуться, и пытаются велосипеды выдумывать.
(32) Кстати, да, можно писать в текст же, а отдельным приложением (например, второй базой 1С) тексты разбирать. А чтобы из основной базы 1С можно было кликать на документы и прочее - возможно веб-решение, у нас уже так сделано.
Я сейчас подумал, что таким же путем можно вести вообще полный архив версий документов, при этом не будет зас..ния основной базы версиями.
(72) У мня РИБ-база и мне проще - есть узел, база где не только полный архив базы на случай оперативного восстановления, но и версионирование документов. В этой базе пользователи не работают и проблема производительности меня не волнует.
(71) поделись с миром 1с-ников достижениями в области хранения логов, только чтобы начиная хотябы от 100М записей с возможностью отбора по объекту и пользователю.
(74) Видимо, быстрее всего писать лог в текст (при этом не выстраивается индекс и нет зависимости скорости записи от объема лога), а потом (например, ночью) его считывать второй БД, а текстовый лог обнулять или перемещать.
(71) Для многих внедрений SQLite может быть и оптимальный вариант, есть же всякие бухгалтерии и ларьки. Вообще эта часть разработки платформы может быть не самой трудоемкой: ну заменили DLL ту на эту, что-то изменилось к лучшему, а кому-то понравилась бы и другая опция, я думаю, что со временем и другое тоже разработают, когда дойдут руки/приоритеты. Москва же не сразу строилась.
(74)
Вот, до romix'а вроде дошло уже.
Что ПИСАТЬ в ЛОГ и АНАЛИЗИРОВАТЬ лог - две разные вещи.
Поэтому во всём мире мире ЗАПИСЬ лога осуществляется в обычные текстовые файлы, из которых затем различными КОНВЕРТЕРАМИ информация преобразуется в вид, удобный для АНАЛИЗА.
Самое простое средство из цивилизованного мира - logrotate.
До его принципа в (75) romix сам додумался.
Поэтому на месте одинэсников я вместо ведения журнала в sqlite выпустил бы удобный конвертер, который бы с задаваемой пользователем периодичностью заводил новый файл журнала регистрации, а старый бы конвертил хоть в sqlite, хоть в чёрта лысого.
Сбоит регулярно. Приходится удалять.
До применения SQLite логи работали без сбоев, хотя и медленно.
Не понятно для чего нужно было использовать SQLite когда есть сервер СУБД основной базы. Почему не использовать его для хранения отдельной базы логов.
Логи, как и бекапы, нужно хранить отдельно от основной базы. Это же азы безопасности.
У меня даже роутер выкидывает свои логи на удалёнку.
(81) сейчас эти логи тоже хранятся отдельно. Не понятно почему в формате SQLite а не в формате СУБД основной базы.
(80) ничто не мешает настроить физически отдельное от основной базы место хранения базы логов. Не понятно для чего использовать формат SQLite когда есть формат и сервер СУБД основной базы.
pragma journal_mode=wal приводит к частым непрогнозируемым зависаниям и деградации производительности на нагруженных базах или при достаточно большом периоде работы.
В случае возникновения проблем мы рекомендуем использовать старый журнал регистрации.
Для этого из каталога журнала регистрации следует перенести файлы 1Cv8.lgd, и создать пустой файл 1Cv8.lgf.
Я подозреваю, что все проблемы решит сочетание journal_mode=wal и посуточного обрезания лога (365 файлов в год).
Или то же самое - с текстом (если получится его методически корректно распарсить в стороннюю базу 1С или SQL).
Отправил в 1С предложение добавить там мьютекс (скорее всего, транзакции SQLite не распараллеливаются, и это приводит к зависаниям серверных процессов) и посоветовать методически правильное средство для сбора информации из текстовых логов (может, уже есть готовое, или планируется к разработке).
(92) Там видимо надо поставить режим WAL и распараллелить потоки мьютексом (наверное сейчас долбятся повторами при ошибках SQLite).
На нагруженных же базах лог собирать из текстов по ночам в, скажем, вторую базу 1С с логами в регистре сведений (без SQLite). Как-то так.
(93) Не верю (с) Станиславский. Если два пользователя одновременно записывают документы, то как там один поток может быть.
(94) тебе же писали уже, что WAL глючит. Накой тебе этот WAL дался? Пускай тупо в текстовый файл пишут и все будут счастливы.
Имхо, проблему можно решить и без 1С, если административно раз в сутки перезаводить текстовый ЖР, и конвертить прошлый в вид, удобный для анализа. Но при этом все штатные средства просмотра журнала пойдут лесом, а многих такой путь не устраивает, все хотят "vendor way".
После жалоб пользователей на замедление 1С:Предприятие администраторы высказали подозрение, что причиной тормозов является Журнал регистрации. Журналы – это несколько файлов формата lgd от одного до двух гигабайт. Чтобы развеять все сомнения, и вооружившись трехзвенкой 8.3.12.1469 x86, а также инструментами от производителя, решено было изучить вопрос вдоль и поперек или другими словами, узнать, «что там под капотом».
Чтобы 1С:Предприятие хранила журнал в данном формате, необходимо его указать явно в конфигураторе или файле настроек. Либо просто удалить все файлы из каталога журнала, если там файлы предыдущего формата. Разделение данных, как было в предыдущей версии, не поддерживается. Корневой каталог журналов указывается в параметрах запуска службы после ключа -d. Например, -d “d:\temp\srvinfo”
Итак, журнал представляет из себя не что иное, как базу данных sqlite, хотя 1С использует свое именование расширения и даже свой драйвер для доступа, который входит в поставку платформы. Разработчики 1С не стали использовать предлагаемый авторами sqlite драйвер, а просто скомпилировали свой, видимо для совместимости и/или простоты использования, благо исходники доступны на сайте sqlite. Но используется он своеобразно. К примеру, если пометить на удаление записи в журнале любым доступным вам способом, то это ничего не даст потому, что 1С просто игнорирует эту метку. То есть при просмотре отразятся все без исключения записи.
Разработчики sqlite утверждают, что размер файла базы данных может превышать сотню гигабайт и даже сотню терабайт. Так что, если бы 1С:Предприятие тормозила из-за журнала, то скорее всего это могло случиться только из-за кривого драйвера от 1С или неумения его правильно готовить использовать. Хотя конечно могут влиять и внешние факторы, как например, дефрагментация диска и тому подобное. К примеру, одно из последних нововведений разработчиков sqlite – метод VACUUM. И хотя он также упоминается в драйвере 1С, на деле этот метод никак не используется или я не смог спровоцировать его выполнение. Если вы решите сократить полностью журнал из Конфигуратора, то вместо того, чтобы заново создать файл или основную таблицу журнала, 1С:Предприятие начнет удалять все записи в таблице EventLog. И если у вас он большого размера, то придется запастись терпением. За то при этом все пользователи могут продолжать свою работу в обычном режиме, вот только вряд ли при этом что-то отразится в журнале об их работе. Многопоточность? Нет, не слышал.
В документации сказано, что при загрузке информационной базы все записи журнала не очищаются. Для чего так сделано? Ведь если конфигурация иная, то в базе останутся никому не нужные записи об объектах предыдущей конфигурации, которых просто может не быть в новой. Видимо пользователю предлагается самому найти этот файл и удалить.

Службы 1С:Предприятие автоматически создает файл 1Cv8.lgd при первом же обращении будь то конфигуратор или web-приложение. Что интересно база не формируется сразу же целиком, а только по необходимости. К примеру, если установить уровень «Регистрировать ошибки», запустить регламентное задание, то создадутся только две таблицы, пусть и пустые. То есть о выполнении регламентных заданий вы не узнаете, пока не начнется нормальное ведение журнала, а для этого нужно хотя бы раз открыть 1С:Предприятие (в любом режиме). Кстати регламентные задания в журнале отражаются как фоновые. Почему так? Зачем понадобилось два термина?
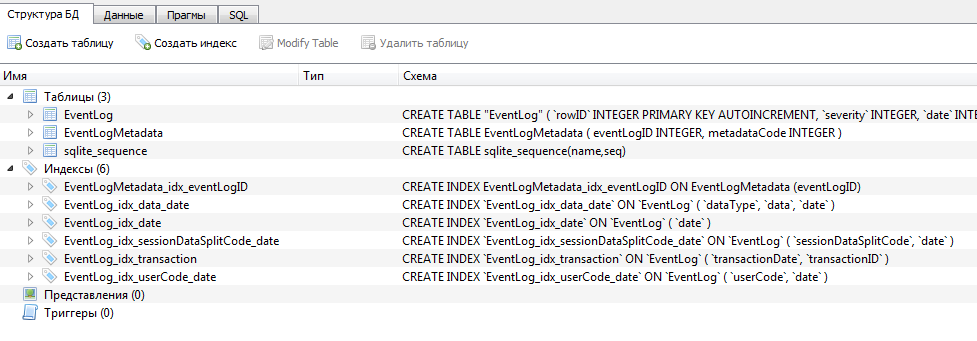
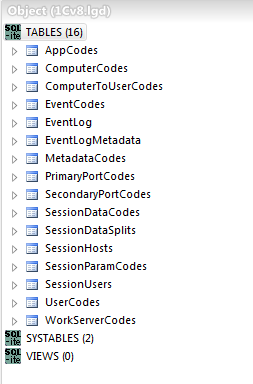
И только при запуске 1С:Предприятие в режиме конфигуратора или обычного приложения создадутся все оставшиеся необходимые таблицы. Записи создаются по такому же алгоритму. К примеру, есть таблица MetadataCodes, в которой хранятся объекты конфигурации. Но все объекты разом не записываются, хотя это можно было бы сделать, к примеру, при обновлении конфигурации, а записываются только по требованию.
Структура базы нормализована по полной программе. Размер записи основной таблицы равен примерно 140 байт, что совсем немного для такого рода сценария использования как ведение логов.
Но есть вопросы. К примеру, для чего нужно было создавать отдельные таблицы используемых портов? Сколько килобайт планировали сэкономить авторы? Видимо это все ради того, чтобы потом быстро показать/использовать в форме отбора. Другого объяснения не нашел. Но опять же для чего надо было создавать поле Name, когда его значение можно было хранить в поле Code. Если у кого есть идеи, поделитесь.
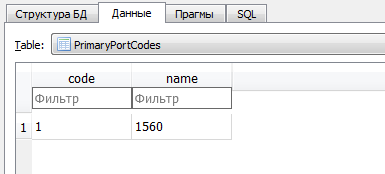
Следующий момент больше похож на ошибку разработчиков. Столкнулся с ней, когда попытался соединить эти таблицы. Дело в том, что ключ metadataCodes в основной таблице EventLog имеет тип TEXT, хотя должен был быть INTEGER. Выкрутился преобразованием «на лету»: SELECT 0+ metadataCodes FROM . Драйвер ODBC позволил такое проделать. Хотя можно просто изменить структуру таблицы, работоспособность журнала от этого никак не пострадает.
И эта песня тянется уже не один год.
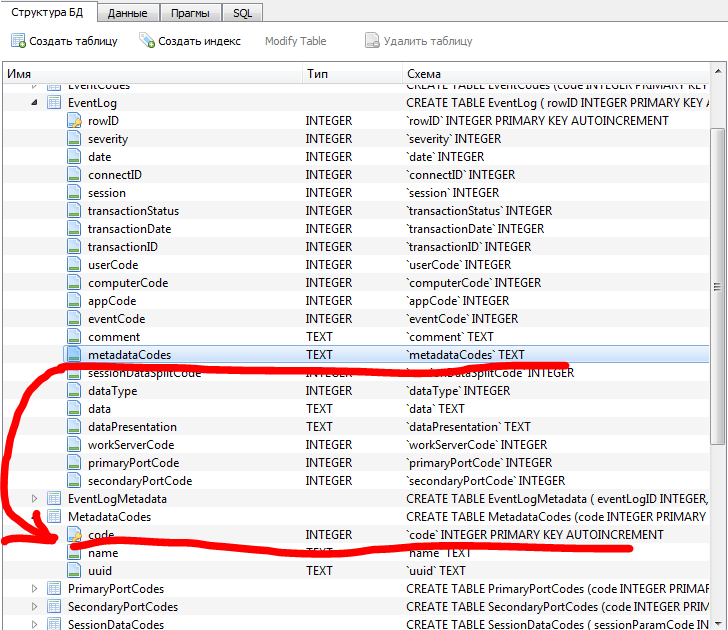
При любом несложном нарушении структуры базы она будет восстановлена. К примеру, мной были удалены некоторые индексы, и при следующем моем обращении к журналу из главного меню конфигуратора Администрирование – Журнал регистрации все индексы были благополучно восстановлены после небольшой паузы.
Итак, вернемся к файлу журнала, с которого все и началось. Размер его чуть превышал 1 гигабайт, что по меркам авторов sqlite это копейки. Нельзя не отметить всеобщий сарказм администраторов в отношении к 1С, многие относят ее к разряду «для киосков с оборотом 3 рубля». Это, конечно же, отдельная история. Хотя предыдущая статья лишь подтверждает этот момент, особенно аргументы в обсуждении.
Принимая во внимание все вышеперечисленные проблемы, сомнения все же оставались. Мною было решено просто проверить, как влияет рост размера журнала на производительность. Была создана обработка, которая в цикле выполняла одну лишь команду:
20 циклов/замеров по миллиону записей. Размер файла вырос с пары-тройки десятков килобайт до почти трех гигабайт. Обратите внимание, что скорость никоим образом не изменилась, более того даже не деградировала от того, что файл сильно распух. Все же авторы sqlite правы, говоря, что это копейки.

Так же для контроля скорости записи на диск использовалась программа Process Monitor (Procmon) из набора утилит Sysinternals Марка Руссиновича и Брюса Когсвела, которая лишь подтвердила полученные данные.
Размер файла журнала регистраций никак не влияет на скорость записи. Конечно, надо учитывать еще много других факторов. Но текущая задача была лишь проверить как сама 1С:Предприятие работает с файлами sqlite большого размера.
В 1С 8 журнал регистрации хранится в текстовых файлах, которые находятся в подкаталоге 1Cv8Log. Для клиент-серверной ищем где-то в "C:\Program Files\1cv82\srvinfo\reg_1541\\1Cv8Log\".
Обычно журнал регистрации 1С 8 состоит из одного файла описаний (ELF в 8.1 / LGF в 8.2) и одного или нескольких файлов данных (LOG в 8.1 / LGP в 8.2). Существуют еще так называемые архивы журнала регистрации – в этом случае описания и данные находятся в одном файле последовательно, сначала описания, затем данные, при этом расширение как у файла данных.
В первой строке файла журнала регистрации пишется маркер
"1CV8LOG_" для 8.1 и "1CV8LOG(ver 2.0)" для 8.2.
Во второй строке пишется GUID.
Для файла данных журнала регистрации пишется еще дополнительно третья пустая строка.
Дальше идут непосредственно данные, которые заключены в фигурные скобки "<>" и отделяются друг от друга запятой.
При парсинге журнала регистрации сталкиваемся с проблемой отделения друг от друга записей – ведь они имеют переменную длину и могут быть разбиты на разное число строк, которое получается из-за следующих правил, добавляющих дополнительные символы новой строки (Символы.ПС):
2) Закрывающие фигурные скобки ">" не могут идти подряд – они всегда разделены символом новой строки;
3) Символ новой строки может встретиться внутри кавычек.
Таким образом отделить запись можно по следующим критериям
1) Первый символ – открывающая фигурная скобка "
3) Последний символ – закрывающая фигурная скобка ">";
4) Так же у правильной записи всегда будет четное число кавычек.
Структура записей файла описаний 8.1 сильно отличаются от 8.2.
При анализе файла описаний 8.1 по приведенным выше правилам получим всего одну запись, которая будет состоять из элемента "Legend" и вложенных записей. Структура вложенных записей одинакова – это заголовок и вложенная запись. Заголовок может принимать следующие значения "Users" – GUIDы пользователей, "UserNames" – имена пользователей, "Hosts" – компьютеры, "Apps" – приложения, "Events" – события, "MDID" - GUIDы метаданных, "MDCodes" – имена метаданных, "SrvHosts" – серверы, "MainPorts" – основные порты, "SyncPorts" – вспомогательные порты. Вложенные записи состоят по сути из массивов. Первый элемент – размер массива, дальше идут непосредственно значения. Разделитель – запятая.
При анализе файла описаний 8.2 увидим другую картину. Файл содержит много записей размером от обычно трех элементов до четырех, в случае если надо указать GUID – для пользователей и метаданных.
Формат записи прост – первый элемент код массива, второй – значение, третий – номер в массиве. В случае четырех записей, между первым и вторым элементом появляется GUID.
Коды массивов были обнаружены следующие:
7 – основные порты;
8 – вспомогательные порты.
Так же встречаются пока неопознанные коды 11, 12 и 13
Таким образом, из файлов описаний получаем необходимые справочники, которые будут использованы в файлах данных.
Структура записей файлов данных 8.1 отличается от 8.2 по сути только количеством элементов. В 8.1 запись состоит жестко из 16 элементов, а в 8.2 число элементов переменно и может быть от 19 штук и до в принципе любого количества.
Далее приведу значения элементов в записи:
1) Дата и время в формате "yyyyMMddHHmmss", легко превращается в дату функцией Дата();
2) Статус транзакции – может принимать четыре значения "N" – "Отсутствует", "U" – "Зафиксирована", "R" – "Не завершена" и "C" – "Отменена";
3) Транзакция в формате записи из двух элементов преобразованных в шестнадцатеричное число – первый – число секунд с 01.01.0001 00:00:00 умноженное на 10000, второй – номер транзакции;
4) Пользователь – указывается номер в массиве пользователей;
5) Компьютер – указывается номер в массиве компьютеров;
6) Приложение – указывается номер в массиве приложений;
7) Соединение – номер соединения;
8) Событие – указывается номер в массиве событий;
9) Важность – может принимать четыре значения – "I" – "Информация", "E" – "Ошибки",
"W" – "Предупреждения" и "N" – "Примечания";
10) Комментарий – любой текст в кавычках;
11) Метаданные – указывается номер в массиве метаданных;
12) Данные – самый хитрый элемент, содержащий вложенную запись;
13) Представление данных – текст в кавычках;
14) Сервер – указывается номер в массиве серверов;
15) Основной порт – указывается номер в массиве основных портов;
16) Вспомогательный порт – указывается номер в массиве вспомогательных портов;
17) Сеанс – номер сеанса;
Теперь рассмотрим вложенную запись элемента 12 (Данные), который может принимать следующие значения:
1) – Неопределено – можно преобразовать через ЗначениеИзСтрокиВнутр();
2) – Строка – можно преобразовать через ЗначениеИзСтрокиВнутр();
3) – Ссылка c GUID, где метаданные с id. Для получения id метаданных пока нашел только немного извращенный способ – ЗначениеИзСтрокиВнутр(ТипМетаданных.ИмяМетаданных.ПустаяСсылка()) и парсить полученную строку.
4) ,>>– что-то вроде массива но пока не понятно что значит 6 – на ее месте пока встречал только 1, 2 и 6. Возможно это разные типы - массив, структура и т. п.
Позже появилась довольно интересная публикация - Периодическая загрузка событий из журналов регистрации в базу MS SQL Server, где автор парсит файлы журнала регистрации напрямую, причем он пишет, что разбирал формат журнала регистрации сам, задолго до текущей публикации, но к сожалению пока дополнительно найденной информацией по формату с сообществом не поделился.
Читайте также: