
1с сбросить повторное использование
1. Общие модули с повторным использованием возвращаемых значений (далее: кэш) предусмотрены для кэширования результатов работы функций, которые в них размещены - на время сеанса или на время вызова . Их следует применять для экономии вычислительных ресурсов сервера и для минимизации клиент-серверного взаимодействия.
См. также: раздел "Повторное использование возвращаемых значений" документации по платформе 1С:Предприятие,
Использование значений, влияющих на поведение клиентского приложения
2. В то же время, чрезмерное (неоправданное) применение общих модулей с повторным использованием возвращаемых значений может приводить к излишнему потреблению памяти.
2.1. Недопустимо создать общие модули с повторным использованием, из которых возвращаются данные, вычисление которых выполняется быстрее, чем получение из кэша. Например, строковые константы. Кроме того, что получение строковой константы каждый раз будет работать гораздо быстрее, чем получение ее из общего модуля с повторным использованием, эти данные будут занимать память кэша.
Например, неправильно размещать в модуле с повторным использованием:
Имеет смысл кэшировать данные, полученные из базы данных, внешних источников данных или путем сложных (ресурсоемких) вычислений. Причем в ряде случаев, даже значения, полученные из базы данных, не стоит кэшировать, если выгода от их кэширования – неочевидна. Например, не стоит кэшировать константы (объект метаданных) примитивных типов, поскольку часто они привносят лишь незначительную долю от общего времени выполнения ресурсоемкой операции.
2.2. Следует помещать в кэш только такие данные, к которым потом будут часто обращаться.
В частности, следует иметь в виду, что кэш не хранит данные вечно. Закэшированное значение будет удалено из кэша через 20 минут после вычисления или через 6 минут после последнего использования (в зависимости от того, что наступит раньше*). Кроме этого значение будет удалено при нехватке оперативной памяти в рабочем процессе сервера, при перезапуске рабочего процесса и при переключении клиента на другой рабочий процесс. Поэтому если никто "не успел" воспользоваться данными из кэша, то этот ресурс был потрачен зря.
* Примечание: конкретные цифры могут варьироваться в зависимости от используемой версии платформы 1С:Предприятие.
2.3. Диапазон значений входных параметров функций, размещенных в общих модулей с повторным использованием, не должен быть широким.
Например, в конфигурации предусмотрена функция, получающая на вход контрагента. Если контрагентов в базе очень много, а сценарий работы пользователей таков, что вероятность того, что кто-то за 5 минут обратится к этому же контрагенту, очень невысокая, то ресурсы будут потрачены впустую. Кроме того, если эту «трату» умножить на количество одновременно работающих пользователей, то бесполезные расходы ресурсов становятся значительными.
3. Не следует изменять данные, полученные из кэша. В противном случае, возможны скрытые ошибки в работе программы, а также бесполезное расходование памяти (ресурсов кэша). Поэтому в качестве возвращаемых значений рекомендуется использовать значения, состояние которых изменить нельзя, например: ФиксированныйМассив, ФиксированнаяСтруктура.
Это ограничение вызвано тем, что кэш возвращает каждый раз не копию объекта, а ссылку на один и тот же объект в памяти. Например, если в массив, который возвращает функция с повторным использованием, при каждом вызове при проведении документов дописывать новое значение, то в результате кэш очень быстро «распухнет». Кроме того, при очередном сбросе кэша, добавленные значения будут потеряны и код, который на них опирался, будет работать некорректно.
4. Если в модуле с повторным использованием размещено несколько экспортных функций, которые не только вызываются «снаружи», но и вызывают друг друга, то следует иметь в виду, что результат «внутренних» вызовов не кэшируется.
Например, если в модуле ОбменДаннымиПовтИсп размещено две экспортных функции:
которые последовательно вызываются из прикладного кода,
то функция АвтономнаяРаботаПоддерживается будет вычислена дважды.
Для того чтобы ее возвращаемое значение всегда получалось из кэша, следует явно указывать имя модуля:
Про повторное использование значений в рамках одного сеанса сказано уже достаточно. Давайте подумаем, как сделать то же самое, но глобально для ИБ в рамках всех сеансов. Спойлер: без вэб-сервера ничего не получится.
Upd: Внимание! Приведенный метод не является универсальным инструментом на все случаи жизни и имеет существенные ограничения. Прежде чем пилить код - обязательно читайте главу "Update: Потокобезопасность"
В чем проблема
Банальная инициализация параметров какого-то длительного фонового действия может занимать по нескольку секунд. А если это действие распараллелить - то с ростом производительности за счет многопоточной обработки - мы получим рост издержек на инициализацию параметров. Даже в пользовательских сеансах встречаются операции а-ля получения каких-то значений по-умолчанию, продолжающихся достаточно длительное время. Особой проблемы в рамках одного сеанса это как правило не представляет, но если 200 сеансов "долбят" базу данных одними и теми-же вопросами - это уже становится ощутимо.
Согласитесь, было бы здорово прочитать, например, параметры обмена данными один раз и использовать их дальше из оперативной памяти. В общем то такое уже встречается сплошь и рядом: в типовой УТ наверно сотня модулей с повторным использованием возвращаемых значений. Но есть проблема: все это работает только в рамках одного сеанса и у нас нет средства для передачи данных между сеансами (кроме разве что базы данных, но ее использование в этом качестве само по себе является анти-паттерном)
Решение
Схематично все это можно изобразить так:

Таким образом, мы как-бы "заворачиваем" вызовы из разных сеансов в один посредством REST сервиса, а в нем уже используем штатную функциональность модулей с повторным использованием возвращаемых значений.
Детали
Для того, чтобы все это взлетело - необходимо создать HTTP сервис и установить в нем параметр Повторное использование сеансов в значение Использовать автоматически. Время жизни сеанса устанавливайте по своему усмотрению, у меня стоит 2.592.000 (месяц). Будьте внимательны: это не время жизни сеанса, это время бездействия сеанса, после которого он будет завершен. Дополнительно, в файле default.vrd (файл описания сервиса, лежит в папке публикации) необходимо установить параметр poolSize="1". Все это вполне легальные действия, никакой партизанщины.
Далее, варианты могут быть разными, вы можете писать какие-то специфичные функции установки и чтения параметров, но в случае написания универсальной процедуры, "оборачивающей" любую процедуру в повторно-используемую оболочку - получится следующее.
Здесь параметры соединение введены хардкодом, что как бы не очень хорошо, но если мы будем делать все по-правильному и читать их каждый раз из БД - эффект от повторного использования возвращаемых значений может быть существенно снижен.
Функции повторно-используемого модуля:
Подводные камни
Во-первых у этого метода есть ограничение снизу, некий "порог вхождения", который обусловлен существенными издержками на инициализацию общего сеанса и обращение "завернутое" через сетевые интерфейсы:
- Первый вызов (в рамках которого происходит инициализация общего сеанса) в моем случае длится около 1 секунды. Этот параметр зависит от того, что у вас за конфа. У меня УТ 11.3.
- Последующие вызовы, которые не инициализируют сеанс, а обращаются к уже готовому, занимают 0,015 - 0,02с, что вполне неплохо (это только время самой сетевой транзакции, если будет выполняться трехэтажный запрос - реальное время будет больше). Но я подозреваю, что тут все сильно зависит от сетевой архитектуры.
Здесь важно обратить внимание: инициализация длинной в 1 секунду будет проходить только один раз для всех возможных методов и наборов их значений, а не для каждого нового метода/значения.
Во-вторых у этого метода есть ограничение сверху, некий "потолок использования", который обусловлен размером оперативной памяти, которую вы готовы выделить под кэширование значений. Хотя, здесь невозможно не заметить, что если вы будете кэшировать эти данные традиционным способом, через повторноиспользуемый модуль для каждого сеанса - это займет памяти больше, кратно количеству сеансов, поэтому здесь есть как ограничение так и простор для экономии.
Дополнительные возможности
В рассмотренном случае, механизм повторного использования сеанса REST сервиса используется для получения функциональности повторного использования возвращаемых значений между сеансами, но это не единственная возможность. Видится возможным использовать этот механизм для организации других видов межсеансового взаимодействия, например:
- передача данных между сеансами
- хранение актуальных состояний и управление общим оборудованием, например, одним фискальником на несколько рабочих мест
- управление соединением с другой ИБ (иметь COM-коннект в одном сеансе и использовать его из остальных)
И не стоит забывать, что все это будет работать только в версии 8.3.9 и выше. Удачи!
Update: Потокобезопасность
Комментарий Юрия Дешина подтолкнул меня к, как теперь кажется, очевидной мысли: заворачивание вызова нескольких сеансов в один, при некоторых обстоятельствах может привести к образованию очереди и массовому отказу в обслуживании вызовов. Так, пока сеанс Х выполняет какие-то вычисления, "заказанные" сеансом 1, сеанс 2 не сможет получить никакие данные (в том числе ранее закэшированные) от сеанса Х. При этом сеанс 2 будет "висеть", пока не будет достигнут тайм-аут (параметр poolTimeout в файле default.vrd), по достижении тайм-аута будет возвращен ответ 500.
В общем, как обычно, когда кто-то встает и спрашивает "а что там с потокобезопастностью?" - все становится сильно сложнее чем было до этого. Но это не значит, что задавать такие вопросы не нужно.
Что же нам со всем этим делать?
Ну во-первых, очень осторожно пользуйтесь вызовом такой процедуры в обработке проведения или внутри какой-либо другой транзакции записи.
Во-вторых, можно наметить следующие пути снижения рисков образования очереди в высоконагруженных системах:
- Не использовать универсальных обработчиков, которые отвечают сразу за все (например такие, как описано выше). Т.е. если сервис будет отвечать и за расчет себестоимости и за соединение с соседней базой по COM - неизбежно будут возникать ситуации, когда мы не можем подключиться к соседней базе, потому что считаем себестоимость в этой (я утрирую, но мысль думаю понятна). Однако, если мы примем концепцию типа "одно значение - один сервис", то все будет логично: пока значения нет - все сеансы сидят и ждут когда оно появится. Появилось значение - раздали его всем.
- Увеличивать число сеансов, раздающих значения. (параметр poolSize в файле default.vrd). Это экстенсивный путь, но до какой-то степени его можно считать рабочим, поскольку такое решение позволит избежать завешивания: при занятости одного сеанса - платформа автоматически переключит вызов на второй, третий, пятый и т.д., но в этом случае значение вычисленное в сеансе Х1 не будет доступно в сеансе и Х2 и будет вычисляться там заново. Можно думать об этом примерно так: все значения кэшируются в сеансе Х1, но он может быть недоступен, в этом случае вызов будет обработан сеансом Х2 (Х3. Хn), но значение будет вычислено заново.
- Городить более сложные схемы взаимодействия с кэширующими сеансами, при которых использование сервиса сильно усложнится, но и вероятность получить отказ будет минимальной. Например такую:

Также, в ключе потокобезопастности стоит обратить внимание на тот факт, что повторное использование сеанса производится в разрезе пользователя, под которым вы подключаетесь к сервису. т.е. если обстоятельства заставляют вас гарантировать отсутствие взаимного влияния каких-то процессов, вы можете сделать это не только сделав новый сервис, но и сделав новый логин к тому же сервису.
В целом же, стоит признать что приведенный в статье метод нельзя использовать как универсальное средство кэширования данных, но при достаточной глубине понимания вопроса из него можно почерпнуть идею для межсеансового взаимодействия.
По роду своей деятельности, мне часто приходится обсуждать с программистами детали реализации той или иной функциональности. Очень часто, разговаривая даже с квалифицированными специалистами я сталкиваюсь с незнанием сути платформенной функциональности Повторного использования возвращаемых значений общих модулей. В данной статье я постараюсь дать краткий обзор и основные особенности этой функциональности.
В чем проблема
Часто нам приходится по ходу исполнения программы получать значения, которые хранятся в базе данных и не меняются годами. Яркий пример - значения констант. Отчасти, можно причислить сюда же поиск элемента справочника или узла плана обмена по коду, получение значений реквизитов объектов по ссылке.
Не думая, "на лету" такие задачи решаются конструкциями вида:
В результате, каждый раз когда выполняется этот код - происходит "дерганье" базы данных.
Программисты более щепетильно относящиеся к своему коду, выполняют один запрос к базе данных, кэшируя все данные которые им понадобятся, однако такой подход не всегда приводит к желаемой разгрузке БД:
- Цикл выполнения кода может быть неявным (например, групповое перепроведение документов)
- Получить строгий набор данных (не больше и не меньше), которые потребуются позже, иногда затруднительно или вовсе невозможно.
- Кэшированные значения требуется использовать в разных вызовах/формах
Модуль с повторным использованием возвращаемых значений
Для решения описанных проблем в платформе есть модули с повторным использованием возвращаемых значений. Фактически, это обычный общий модуль (клиентский или серверный), в котором Повторное использование возвращаемых значений установлено в "На время вызова" или "На время сеанса". В самом модуле процедуры и функции описываются как обычно.
Вся соль заключается в том, что при многократных вызовах экспортных функций таких модулей - в первый раз вызов действительно производится как мы и ожидаем, а все последующие вызовы приводят к возврату закэшированного значения без реального выполнения кода функции. Этот эффект можно наблюдать в замере производительности.
Возвращаемые значения, естественно, кэшируются в разрезе значений переданных параметров, т.е. при выполнении кода
, оба вызова действительно приведут к выполнению соответствующей процедуры и вернут разные ссылки, а при последующих попытках получить узел с кодом 0001 или 0002 - будут возвращаться соответствующие узлы без вызова процедуры и, как следствие, базы данных.
Значения кэшируются отдельно для каждого сеанса на клиенте или сервере (в зависимости от того клиентский или серверный модуль). Т.е. если есть особенности настройки прав доступа или другой зависимости полученного значения от текущего пользователя - все отработает корректно.
Чего делать нельзя
Есть одно ограничение. В качестве параметров функций можно указывать только простые типы. Неопределено, Null, Булево, Дата, Строка, Число, Ссылка. Никаких структур, таблиц значений, объектов и т.п. Если вы попытаетесь передать в качестве параметра, например, структуру - все отработает, но о повторном использовании полученного значения можете забыть.
Возвращаемое значение при этом может быть любого типа.
Также, стоит обращать внимание на размер данных которые вы кэшируете. Всю память сервера вы забьете вряд ли, но помнить о том, что ресурсы не бесконечны стоит.
Баг или фича от 1С
Интересное свойство есть у повторно используемых значений. Баг это или фича непонятно, но знать о нем не помешет. Если выполнить код следующего характера:
, то в ЗначениеСтруктура2.Наименование будет лежать именно "Новое наименование". В принципе, это можно использовать для обновления значений, реально измененных в БД, но когда прикроют и прикроют ли лавочку - непонятно. При разработке типовых решений так делать запрещено.
Что делать при изменении закэшированных данных
Есть всего лишь один "легитимный" метод обработать ситуацию с изменением закэшированного значения в базе данных. Это метод ОбновитьПовторноИспользуемыеЗначения(). Будут сброшены значения всех функций по всем параметрам всех модулей. Обновить по конкретным значениям параметров / функциям / модулям нельзя.
Соответственно, из-за такого волюнтаристского подхода, пользоваться этой функцией необходимо крайне осмотрительно: вся система после его использования какое-то время будет работать существенно медленнее.
Посягаем на святое: пишем запрос в цикле
Кроме очевидных вариантов использования функций с повторным использованием возвращаемых значений, есть немало интересных, универсальных, нестандартных подходов, среди которых:
- Написание универсальных процедур, возвращающих реквизиты произвольных ссылок (есть в БСП)
- Написание процедур, возвращающих значения констант по имени константы (есть в большинстве типовых)
- Возврат "чуть большего" объема данных, чем необходимо ради уменьшения количества вызовов (напр. если требуется получить курсы сразу нескольких валют, имеет смысл вызывать функцию по дате без отбора валюты, получить курсы всех валют и далее "разбираться на месте" какая из валют в настоящий момент нужна)
- Написание процедуры, выполняющей запрос с кэшированием результата (входящими параметрами при этом будут текст запроса и пара-тройка имен и значений параметров)
Но есть еще один подход, на котором я хочу остановиться подробно. Это использование функции, содержащей вызов БД, с повторным использованием возвращаемого значения в цикле. Т.е. фактически это запрос в цикле. Вообще, нас учили так не делать, но бывают случаи, когда такое построение кода приведет к лучшей производительности, если:
- Количество различных значений входящих параметров, которые встретятся внутри цикла небольшое и подавляющее большинство сочетаний с высокой долей вероятности было получено ранее в этом сеансе.
- Заранее получить строгий набор сочетаний значений входящих параметров, которые встретятся в цикле затруднительно, а получение значений для всех возможных сочетаний значений входящих параметров приведет к считыванию большого объема данных из БД
Как видите формулировки не точные и больше похожи на напутствия, чем на правила. Поэтому всегда держите в голове контекст, оценивайте текущую картину, обдумывайте условия в которых будет работать ваш код.
Общие модули предназначены для содержания общих алгоритмов конфигурации, которые доступны из разных модулей конфигурации. В общих модулях отсутствует раздел определения переменных и раздел основной программы, то есть они должны содержать только процедуры и функции.
Если используется клиент–серверный вариант работы системы 1С:Предприятие 8, то с помощью свойств Клиент (обычное приложение), Клиент (управляемое приложение) и Сервер, а также указаний препроцессору разработчик может организовывать выполнение различных процедур и функций общих модулей в контексте сервера или в контексте клиента.
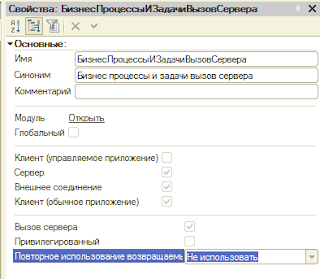 |
| 1. Пример общего модуля |
Описание свойств
Если установлено свойство Клиент (обычное приложение) или Клиент (управляемое приложение), то все процедуры и функции общего модуля могут использоваться в клиентском приложении. В контексте неглобального общего модуля с установленным свойством Клиент (обычное приложение) доступны экспортируемые переменные, процедуры и функции модуля обычного приложения. В контексте неглобального общего модуля с установленным свойством Клиент (управляемое приложение) доступны экспортируемые переменные, процедуры и функции модуля управляемого приложения.
Если установлено свойство Сервер, то все процедуры и функции общего модуля могут использоваться в клиент-серверном варианте.
Если установлено свойство Внешнее соединение, то все процедуры и функции общего модуля могут быть использованы во внешнем соединении. В контексте неглобального общего модуля с установленным свойством Внешнее соединение доступны экспортируемые переменные, процедуры и функции модуля внешнего соединения.
Свойство Вызов сервера разрешает вызов сервера. Свойство доступно, если установлено свойство Сервер. Если данное свойство не установлено, то процедуры и функции данного модуля доступны только на сервере, иначе процедуры и функции доступны на клиенте.
Свойство Привилегированный предназначено для установки полных прав доступа при выполнении действий с базой данных в процедурах и функциях общего модуля. При установленном свойстве выполнение производится только на сервере.

Принцип обмена данными из 1С с сайтом (на MySQL) и выдачи (публикации) этих данных по запросу.
PHP-Скрипт автоматической загрузки данных из файла данных в формате CSV в базу данных сайта работающего на WordPress.
В продолжение моей темы: 1С:Альфа-Авто Автосалон Автосервис: обмен с сайтом.
С помощью данного скрипта можно загружать в автоматическом режиме, по расписанию, данные сервисных книжек (ремонтов авто) из 1С:Альфа-Авто Автосалон Автосервис.
Также можно загружать данные в ручном режиме: для этого делается скрытая страница, где размещается специальная кнопка.
Комментарии размещенные внутри скрипта разъяснят логику и порядок действия.
Комментарии с "///// echo" использовались для отладки.
Дополнительно создана таблица для журналирования результатов загрузки данных.
Скрипт включает в себя защиту от SQL инъекций (думаю безопасность соблюдена в полной мере).
В кратце:
1. Пишется скрипт, который запускает этот.
2. Создается регламентное задание в WordPress, по которому запускается скрипт из п.1.
3. Этот скрипт осуществляет проверку на существование файла обмена в папке.
4. Если данные не новые, загрузка не производится.
5. Если данные новые, очищается таблица сервисных книжек.
6. Загружаются новые данные.
Собственно сам скрипт:
(0) я суть статьи не понял. рабочие примеры есть для понимания?
уже писал на форуме, прошло не замеченным — то что сейчас разработчики типовых 1с применяют — сильно огорчает. вот пример:
Столкнулся в УТ 10.3 с такой проблемой — в УТ 10.3 появился механизм ПравилаВыборочнойРегистрацииОбъектов (константа),
который не позволяет переименовывать типовые реквизиты документов.
Я переименовал в документе ПКО реквизит Основание (Тип Строка), потому что он некорректно заполняется при заполнении на основании другого документа (стандартный параметр Основание процедуры ОбработкаЗаполнения()).
…Срабатывает процедура ОбработкаЗаполнения, в которую передается параметр Основание (тип ДокументСсылка). В конце концов реквизит документа Основание и параметр Основание пересекаются и дают отрицательный эффект.
Я переименовал этот реквизит в ОснованиеСтрока — теперь у меня элементарно не проводится документ, выходит ошибка здесь:
Функция ПолучитьТаблицуРеквизитовРегистрацииШапкиДоИзменения(Объект, СтрокаТаблицыРеквизитовРегистрации)
+ » ИЗ » + СтрокаТаблицыРеквизитовРегистрации.ИмяОбъекта + » КАК ТекущийОбъект
Запрос = Новый Запрос;
, в запрос тащится СтрокаТаблицыРеквизитовРегистрации.РеквизитыРегистрации, который содержит следующие поля:
Организация, ВидОперации, Контрагент, ДоговорКонтрагента, ВалютаДокумента, СуммаДокумента, ПринятоОт, Основание, Приложение, Комментарий, ДокументОснование, СтатьяДвиженияДенежныхСредств, СтавкаНДС, НомерЧекаККМ, ПометкаУдаления, Проведен, Номер, Дата, Ответственный, ОтражатьВБухгалтерскомУчете
То есть таким механизмом разработчики ут 10.3 не позволяют переименовывать типовые реквизиты. Хм, думаю это неправильно.
может я не туда пишу — поправьте — но это своего рода кэширование — хранение информации о жесткой структуре метаданных конфигурации которую как будто теперь нельзя изменять — валятся родные механизмы
По поводу жесткой структуры не совсем понятно, раз вы переименовали стандартный реквизит значит структура нежесткая, просто надо переписать код где идет обращение к этому реквизиту. Мне кажется Вы сами никогда не программировали в связке СУБД. Если Вы создали в СУБД таблицу а в ней поля, назвали их как то и написали программу, в которой идет обращение к этой таблице и ее полям (т.е. к их именам), протестировали и дали заказчику полностью рабочую программу, а заказчик в свою очередь переименовал стандартные поля в Вашей таблице не исправляя кода программы, где идет обращение к переименованным полям и обнаруживает, что программа перестала работать (выдает ошибки и т.д.) и начинает Вам жаловаться, что Вы не правильно составили программу, как Вы на это посмотрите?
P.S. на самом деле Вы не в ту тему пишите.
(24) я понял вас: пугает что этот список реквизитов засунули в константу с типом Хранилище.
обычно когда меняют наименование реквизита, прогоняют глобальным поиском места где встречается этот реквизит, и везде поправляют название.
в нашем случае Глобальный Поиск не нашел Константу в которой спрятан список реквизитов — по сути строка спрятана, саму константу в пользовательском режиме вы тоже не откроете и не увидите — потому тип объекта Хранилище.
ну и кто так кодит?
вердикт — что-то намудрили в УТ с механизмами версий, оттуда проблемы происходят
(24) я вот не пойму обсуждаемую здесь тему с кэшированием без примеров — какую конкретную задачу пытается решить автор?
(26) Автор не про конкретную задачу, а про инструмент.
Если хочется живых примеров — откройте список общих модулей любой современной типовой и глядите в модуля, где в конце «ПовтИсп» в названии.
а зачем так сложно придумали?
столько модулей развели — в чем суть?
(28) Жертвы на алтарь возможности работать через браузер.
(29) где-нибудь можно об этом прочитать подробнее?
(15)Возвращать-то можно любое значение. Но, принимать как параметр…. в повторно используемую функцию можно значение типа «Структура». Но НЕЛЬЗЯ типа «ФиксированнаяСтруктура» — вот такой идиотизм. Конечно преобразования «Структура» «ФиксированнаяСтруктура» делается легко — но для повторного использования важна идентичность входных параметров — а тут она теряется!
Поэтому, лично я предпочитаю вот так (привожу в упрощённом виде) создавать структуры — когда нужна их идентичность (ну и не изменять их потом):
Такой подход «гарантирует», что где-то 20 минут структура будет идентична, и её «без опаски» можно дальше передавать как входной параметры в другие повторно используемые функции.
Конечно, есть и другие варианты достичь идентичности.
Статья полнейшая глупость. Если бы автор реально занимался замерами работы производительности, то он бы знал, что получение константы методом:
занимает тысячные доли процента, от времени выполнения реального кода.
А уж если и нужно в коде часто использовать данные этой константы, то пишем:
и дальше использ-уем НашаПеременная
Самые затраты операции при работе кода — это запросы и вот там нужно оптимизировать.
(17) Перечитал это еще раз (процитирую)
Закэшированное значение будет удалено из кэша через 20 минут после вычисления или через 6 минут после последнего использования (в зависимости от того, что наступит раньше*). Кроме этого значение будет удалено при нехватке оперативной памяти в рабочем процессе сервера, при перезапуске рабочего процесса и при переключении клиента на другой рабочий процесс. Поэтому если никто «не успел» воспользоваться данными из кэша, то этот ресурс был потрачен зря.
* Примечание: конкретные цифры могут варьироваться в зависимости от используемой версии платформы 1С:Предприятие.
На какой-то из недавних версий платформы пытался это поведение протестировать. Ставишь точку в повторяемом модуле. Провалился в модуль — кэш очистился, нет — еще жив.
Любопытно, что четких временных границ для «последнего использования» не оказалось. Как-то хаотично очистка кэша срабатывала: могло и по 10, и по 20 минут не очищаться при полном бездействии. Но то что очистка происходит — это факт. И это прекрасно )) С содроганием вспоминаю кэш в глобальной переменной.
ПС: еще не раскрыта тема и приведены примеры «кэша на вызов». Такой вид почти не используется. А между тем тоже стоит о нем помнить. Хватает специфических сложных алгоритмов, когда такой кэш незаменим.
Да тема вообще практически не раскрыта. Ни срок жизни этого кэша, ни где он лежит (в сеансовых данных аль ишшо где), ни различия тонкого и толстого, ни различия повт.исп. на сервере и на клиенте… Можно было определить границу эффективности, за которой такое кэширование становится вредным и тормозным; можно было сравнить с параметром сеанса и его поведением; с поведением глобальных переменных модуля приложения, итд… Я уж не говорю о специфических вещах, как-то кэширование значения типа веб-прокси или ком-объект))
Ниочёмка с умным видом. Единственная заслуга статьи, за которую я плюсанул тоже — дискуссия пошла. Вот из дискуссии можно полезное почерпнуть.
(37) Вы давно 1С занимаетесь или недавно? Давайте уже включайте соображаловку. Учить азам я вас не буду. Константу 1 раз получаете в Процедуре ОбработатьВсе() до цикла, после передаете ее в Процедуру ОбработатьЧтоТо(Ссылка, НашаКонстанта) в цикле. Все просто.
Еще раз говорю, не нужно пытаться придумывать пользу от получения констант, займитесь программированием наконец.
(4) Это не баг, и таки не фича — это способ выстрелить себе в ногу))).
Если хочется возвращать наборы значений — то логичней использовать «фиксированные» — Фиксированная структура и т.д.
Ага. Особенно если таких процедур штук двадцать… И они вызывают еще другие процедуры… А те в свою очередь еще процедуры… Везде добавляем аргумент со значением константы и передаем его?…
Как на мой взгляд, не самое лучшее архитектурное решение. Особенно, если добавленный аргумент в списке аргументов процедур как «не пришей кобыле хвост» смотрится (в том смысле, что не имеет отношения к решаемым процедурами задачам).
Но если Вы относитесь к программистам, не сильно заморачивающимся изяществом архитектуры, а стремящимся на скорую руку удовлетворить клиента (а заодно обеспечить себя в будущем большим количеством работы), тогда да — Ваше решение значительно эффективнее в достижении этих целей.
(40) Двадцать процедур, тридцать процедур. Давайте придумывайте сферического коня в вакууме. Вы написали конкретный код и я вам написал, как правильно программировать. Еще раз, у меня нет желания вас учить основам программирования. Продолжайте фантазировать на тему констант и двадцати тридцати процедур. Читать забавно
Я привел ПРИМЕР кода. Естественно, максимально его упростив, т.к. 50 экранов текста никто читать не будет. А если у Вас недостаточно опыта, чтобы с помощью этого простого примера вспомнить реальный код соответствующего масштаба, то помалкивали бы тихонечко. И хотя бы типовые конфигурации полистали (как пример идеального кода они, конечно, не подойдут, а вот как пример сложной иерархии вызовов множества процедур — самое оно будет).
Успехов Вам в постижении программирования вообще и тонкостей 1С в частности!
Ну и достану уже «козырную Мантану»….
Представьте себе, что Вам нужно читать значение константы в обработчике события, например ПриОтправкеДанныхПодчиненному, объекта плана обмена.
Интересно, где Вы предлагаете определить переменную? Где Вы предлагаете ее инициализировать прочитанным из константы значением? И самое главное — как Вы предлагаете передавать значение этой переменной в обработчик события, который при выгрузке данных на узел вызывается тысячи раз (по количеству выгружаемых объектов данных)?
Вряд ли Вы сможете ускорить процесс выгрузки не используя кэшируемые общие модули. 🙂
(3) Звезда не заработана.
Время жизни кэшированных значений — это важнейший момент, отличающий данный механизм от глобальной переменной используемой как КЭШ.
На ИТС кажется были следующие значения: 20 минут от создания или 6 минут от последнего чтения из кэша.
…кэш не хранит данные вечно. Закэшированное значение будет удалено из кэша через 20 минут после вычисления или через 6 минут после последнего использования (в зависимости от того, что наступит раньше*). Кроме этого значение будет удалено при нехватке оперативной памяти в рабочем процессе сервера, при перезапуске рабочего процесса и при переключении клиента на другой рабочий процесс. Поэтому если никто «не успел» воспользоваться данными из кэша, то этот ресурс был потрачен зря.
А самый большой косяк автора — это не рассказать где живут кэши! И что будет при использовании «фичи».
Чтобы не быть голословным — еще раз перепроверил свои знания практическим примером. Докладываю:
Повторяемый серверный модуль с вызовом сервера имеет 2 кэша: как на сервере, так и на клиенте. Если самому «установить» в закэшированную структуру значение, то оно запишется в кэш только там где его присвоили (на клиенте или на сервере). Т.о. на клиенте и на сервере после такой махинации будем из кэша получать разные значения.
Некоторые константы удобнее кэшировать в параметры сеанса.. Вообще у меня в ПовтИсп есть такой метод:
(43) «Козырная Монтана». Мне что-то смешно. Ладно. Вот «корызная Монтана». Я только что написал обработчик, который 50000 раз читает константу. Все это заняло 14 секунд. Так вот, если вы в реальном программировании используете такие циклы, на 50 тыс. раз, то эти 14 секунд ни на что влиять не будут. Так что советую изучить, что такое «производительность» и что реально требует оптимизации в реальном программировании, а не в Сферическом коне в вакууме, который вы мне тут упорно расписываете.
(46) Иногда, 14 секунд — это очень долго.
К тому же помня, что «Сила мелочей — в их количестве»(С)Народ… очень часто приходится сталкиваться с вроде бы равномерно-тормозящим кодом (где оптимизировать вроде бы нечего), который путем «Сферических» оптимизаций можно ускорить раза в три.
Если код изначально писать оптимально (с точки зрения Сферического коня в вакууме), то зачастую, как Вы выразились «реальные оптимизации в реальном программировании» — не требуются вообще.
Хотя да — это мы с Вами уже в Холивар проваливаемся. У каждого свой путь на ниве программирования.
Батенька, здесь в узких кругах народы привыкли к диссертациям в виде статей, а вы тут статейку написали, вот и ругаются, читать много букоф…
Мои мысли о применении фичи:
1. Мониторинг изменения данных в одной функции общего модуля с признаком повторные использование.
2. В функции получаем нужный список реквизитов нужного объекта метаданных. Храним значения в кешированной таблице.
3. Функцию получения реквизитов загоняем в цикл и гоняем туда сюда.
4. При изменении данных в существующих объектах, запускается отдельная процедура по проверке изменений.
5. Если изменения запрещены по определенному алгоритму — создаем электронное письмо администратору.
Как работает механизм:
1. Большие объемы изменения данных.
2. В момент изменения данных максимальная свобода и производительность системы без дополнительных проверок.
3. Все проверки в режиме оффлайн.
4. Проверка изменений осуществляется в оффлайн с помощью кеширования реквизитов и сравнения с существующими в базе.
5. Если реквизиты изменены не по правилам, то кеш сохраняется в файл на диске, админу 1с приходит письмо с описанием проблемы.
6. Админ разбирается в правомерности изменения данных.
7. Если изменение данных запрещено правилами, можно восстановить реквизиты из кеша, который сохранен на диск.
1. Максимальная свобода изменения данных в базе.
2. Минимум проверок при записи в БД.
3. Высокая производительность.
4. Проверки делаются отдельно.
1. При большом количестве изменений кеши изменений будут очень большими, нужно место для хранения кешей таблиц.
Читайте также: