
1с модуль не скомпилирован
С помощью инструкций препроцессора можно указать где именно будет выполняться код на встроенном языке: на сервере, на клиенте, в вебклиенте и т.д.
Данный кусок кода будет присутствовать в скомпилированном модуле только при выполнении на сервере, в режиме обычного приложения или при подключении через COM (внешнее соединение).
Процесс выполнения кода на встроенном языке 1с:
1. Обработка исходного кода препроцессором
2. Компиляция модуля во внутренний байт-код 1С
3. Исполнение байт-кода на виртуальной машине 1С (интерпретация)
При этом один и тот же модуль может быть скомпилирован как на сервере, так и на клиенте. С помощью инструкций препроцессора можно указать должен ли присутствовать в скомпилированном модуле тот или кусок кода.
Инструкции препроцессора
Возможные варианты инструкций препроцессора:
- Клиент
- НаКлиенте
- НаСервере
- Сервер
- ТонкийКлиент
- ВебКлиент
- МобильныйАвтономныйСервер
- МобильноеПриложениеКлиент
- МобильноеПриложениеСервер
- МобильныйКлиент
- ТолстыйКлиентОбычноеПриложение
- ТолстыйКлиентУправляемоеПриложение
- ВнешнееСоединение
Клиент и НаКлиенте — одно и то же. Сервер и НаСервере — одно и то же.
Также есть инструкции для выделения областей в модуле и для директивы «Изменение и контроль» в расширениях. В данной статье они не будут рассмотрены.
Инструкции препроцессора и директивы компиляции
Директивы компиляции используются в модулях форм и команд. Они определяют где будет скомпилирована процедура: на клиенте или на сервере. Директивы компиляции начинаются с символа &.
Сначала выполняются инструкции препроцессора, а уже потом определяются директивы компиляции. Например:
Данный кусок кода будет присутствовать в серверном модуле формы, но не будет скомпилирован. В клиентском модуле формы его даже не будет.
Часто инструкции препроцессора по ошибке называют директивы препроцессора. Но правильно все-таки инструкции препроцессора.
Исполнение процедур и функций
В файловой базе данных инструкции препроцессора будут игнорироваться, куски кода не будут вырезаны при компиляции.
В 1С можно защитить исходный код общих модулей и модулей объектов.
Код формы защитить нельзя.
Защитить можно только те модули, которые не содержат
Пароль на код модуля
Исходный код шифруется с помощью данного пароля, взломать без знания пароля невозможно.
Откройте любой код модуля.
Выберите пункт меню Текст - Установить Пароль. Введите пароль и подтверждение.
Исключение кода модуля
С помощью поставки конфигурации можно вообще исключить исходный код модуля из конфигурации - он будет храниться в скомпилированном виде. Причем делается это все очень просто.
Открываете конфигурацию.
Через пункт Конфигурация - Поставка конфигурации - Настройка поставки заходите в форму настройки поставки, выбираете текст каких модулей нужно исключить из поставки (можно выбрать сразу все для каждого уровня иерархии). Выберите также галочку "Файл поставки может использоваться для обновления".
Далее через пункт Конфигурация - Поставка конфигурации - Комплект поставки создаете CF-файл.
Теперь этот CF файл можно загружать у клиента - в этом CF файле нужные модули исключены (защищены от просмотра).
Настройки поставки хранятся в CF-файле, но к сожалению их нельзя изменить через сравнение конфигураций, только путем полной загрузки CF-файла. Поэтому лучше сделать один общий модуль "КлиентСервер", где хранить функции, которые используют директивы препроцессора, а все остальные модули закрыть.
Но к сожалению это слабая защита. Простенький пример подтверждает это.
ВНИМАНИЕ! ДАЛЕЕ ТЕКСТ ПИСАЛ НЕ АВТОР СТАТЬИ, ГЕНИЙ 1С
Просьба не обращаться к Гению с просьбами рассказать, как расшифровать байт-код или как его получить из закрытой конфигурации. Я этого никогда не делал.
Чтобы получить байт код, рекомендую открытый конфигуратор SQL для 1С8 (ищите на инфостарт)
Чтобы расшифровать байт-код, посмотрите обработки автора TormozIT там же.
Точнее не знаю.
Вот маленький кусок программы:
имеющий вот такой байт-код:
(он получается когда ставится пароль на модуль и когда делается поставка без текстов)
А вот программа декомпилирования этого примера, написать которую может каждый второй 1С-ник:
Описание байт-кода имеет разделы:
- описание алгоритма
- описание констант
- описание переменных
- описание процедур
Разбор байт-кода показывает, что движок 1С это простая стековая машина с "польской" системой вычислений.
Данная система исчисления хорошо знакома большинству программистов по калькуляторам БЗ-34 и другим этой серии.
Основываясь на этом можно, сказать об упрощенном понимании заложенном в приведенный алгоритм.
На самом деле, так называемый спусковой крючок для калькулятора не сам оператор как в приведенном алгоритме, а завершающий оператор "".
Не разбираемый в приведенном коде набор "", на самом деле возврат управления из выполняемого фрагмента на выше стоящий уровень.
Естественно, мы не приводим полный набор команд этого макро языка, составить список сможет, каждый второй 1С-ник, готовый потратить на это какое то время.
Приведу, только фрагмент:
| № п/п | Оператор | Количество данных подним в стеке | Наименование |
|---|---|---|---|
| 1 | 56 | 1 | СокрЛП |
| 2 | 57 | 2 | Лев |
| 3 | 58 | 2 | Прав |
| 4 | 59 | 3 | Сред |
| 5 | 60 | 2 | Найти |
Как понятно, структура байт-кода такова:
Пример кода позволит разобрать дерево байт кода какой бы глубины оно не было (Не стоит думать, что приведенный код станет основой для написания полноценного декомпилятора для стековой машины 1С, т.к. он содержит упрощенный алгоритм разбора потока):
Второй приводимый фрагмент, рассматривает код более обобщенно по сравнению с предыдущим, но не претендует на абсолютную истину и написан только для демонстрации обобщенного взгляда на проблему.
Не забывайте о том, что декомпилируя код, вы можете нарушить право собственности на интелектуальный продукт.
« Как стать программистом 1С » Язык 1С » Препроцессор 1С и компилятор 1С
Препроцессор 1С и компилятор 1С
После написания программы на встроенном языке 1С она сохраняется в конфигурацию в составе модуля. При запуске 1С в режиме 1С Предприятие программа на языке 1С будет выполнена.
Сначала немного терминов:
-
— специальная программа, которая перерабатывает программный код из «вида» удобного для работы программиста, в «вид», удобный для работы копилятора; — специальная программа, которая умеет перерабатывать программный код в «машинный» код — выполняемый непосредственно процессором компьютера; — специальная программа, которая вместо компилирования кода в машинный код для процессора, выполняет его самостоятельно. Интерпретатор с предварительной компиляцией — компилирует программу не в машинный код, а в специальный «байт-код» удобный для последующего выполнения интерпретатором.
Как выполняются программы написанные на встроенном языке 1С?
Программа на языке 1С перед выполнением компилируется – преобразовывается в специальный код.
Выполнение кода на языке 1С производится в три этапа:
- Обработка модулей препроцессором 1С согласно директив препроцессора 1С
- Компиляция в байт-код
- Исполнение
Компиляция производится отдельно на клиенте и отдельно на сервере (даже одного и того же модуля), при первом обращении к нему.
Компилятор 1С на входе получает модуль не в том виде, в каком его видит программист. Препроцессор 1С разрезает модуль на части (вырезая не нужное) и потом соединяет его.
Директива препроцессора 1С — это способ указать препроцессору 1С где будет выполняться указанный участок кода на языке 1С.
Это связано с тем, что выполнение текста программы производится на сервере и на клиенте. Есть функции и процедуры, которые не могут быть выполнены на сервере/клиенте. Например на сервере Вы не можете показать пользователю предупреждение с необходимостью нажатия кнопки ОК.
Поэтому в модуле указывается где должен выполняться код:
- Общий модуль (ветка Общие/Общие модули) – в свойствах модуля указывается может ли он выполняться на сервере и на клиенте
- В остальных модулях – для этого используются директива препроцессора 1С.
Непосредственно в тексте модуля, блоки программного кода, отмечаются директивы препроцессора 1С:
Функция Пример1() //будет выполнена и на клиенте и на сервере
КонецФункции
Если никаких инструкций препроцессору 1С в тексте не указано, и использована функция, которую нельзя выполнять на сервере/клиенте, то в момент компилирования модуля (при первом доступе к нему) в исполняемом режиме будет вызвана ошибка.
«Обертывать» можно не только функции, но и конкретные строки исполняемого кода.
Так как компиляция 1С на данный момент еще не началась, то можно с помощью таких блоков создавать функции с одинаковыми наименованиями (для сервера, для клиента).
В модуле управляемой формы инструкции препроцессору 1С рекомендуется использовать только внутри функций/процедур.
После того, как препроцессор 1С «склеил» модуль, он передает его компилятору 1С, который его компилирует. Далее в режиме исполнения код будет выполнен.
При выполнении кода одного модуля, [может] происходит разовое/множественное переключения выполнения с клиента на сервер и обратно.
Например, если требуется выполнить запрос к базе данных, то выполнение будет переключено на сервер, выполнен запрос, данные переданы на клиент. Таким образом модуль существует на сервере и на клиенте.
Переключение исполнения с клиента на сервер и обратно производится «автоматически».
По умолчанию толстый клиент выполняет весь код на клиенте и иногда вызывает сервер. Тонкий клиент наоборот – все выполняет на сервере и иногда вызывает клиент (хотя в любом случае инициализация первого вызова сервера производится клиентом).
Программист в получившемся «склеенном» модуле может для каждой функции указать, где ее требуется исполнять. Не забываем, что доступ к данным производится на сервере, а инициализация вызова на клиенте. Например:
&НаСервере
Функция ПолучитьДанныеБазыДанных()
Запрос = Новый Запрос("");
КонецФункции
Ранее, в толстом клиенте, форма создавалась и была доступна только на клиенте (если не передать ее параметром на сервер, конечно). Управляемая форма создается на сервере и может обрабатываться на клиенте и на сервере.
Поэтому, при выполнении функций модуля, при переключении выполнения с клиента на сервер и обратно, передаются кроме прочего все данные формы (называется «контекст»).
Данных может быть много и передаваться они будут «долго». А в вызываемой функции они могут быть и не нужны, она их не использует вовсе. Для таких случаев есть директива &НаСервереБезКонтекста.
Эта статья дает представление о работе внешних компонент в системе «1С: Предприятие».
Будет показан процесс разработки внешней компоненты для системы «1С: Предприятие» версии 8.2, работающей под управлением ОС семейства Windows с файловым вариантом работы. Такой вариант работы используется в большинстве решений, предназначенных для предприятий малого бизнеса. ВК будет реализована на языке программирования C++.
Внешние компоненты «1C: Предприятие»
- с использованием Native API
- с использованием технологии COM
Структура ВК
Внешняя компонента системы «1С: Предприятие» представлена в виде DLL-библиотеки. В коде библиотеки описывается класс-наследник IComponentBase. В создаваемом классе должны быть определены методы, отвечающие за реализацию функций внешней компоненты. Более подробно переопределяемые методы будут описаны ниже по ходу изложения материала.
Запуск демонстрационной ВК
- Выполнить сборку внешней компоненты, поставляемой с подпиской ИТС и предназначенной для демонстрации основных возможностей механизма внешних компонент в 1С
- Подключить демонстрационную компоненту к конфигурации 1С
- Убедиться в корректной работоспособности заявленных функций
Компиляция
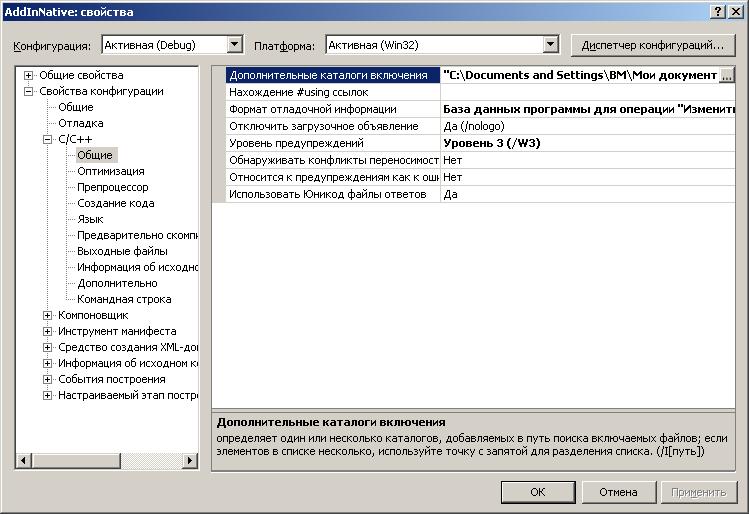
Демонстрационная ВК расположена на диске подписки ИТС в каталоге «/VNCOMP82/example/NativeAPI».
Для сборки демонстрационной ВК будем использовать Microsoft Visual Studio 2008. Другие версии данного продукта не поддерживают используемый формат проекта Visual Studio.
Открываем проект AddInNative. В настройках проекта подключаем каталог с заголовочными файлами, необходимыми для сборки проекта. По умолчанию они располагаются на диске ИТС в каталоге /VNCOMP82/include.
Результатом сборки является файл /bind/AddInNative.dll. Это и есть скомпилированная библиотека для подключения к конфигурации 1С.
Подключение ВК к конфигурации 1С
Создадим пустую конфигурацию 1С.
Ниже приведен код модуля управляемого приложения.
Если при запуске конфигурации 1С не было сообщено об ошибке, то ВК была успешно подключена.
В результате выполнения приведенного кода в глобальной видимости конфигурации появляется объект ДемоКомп, имеющий свойства и методы, которые определены в коде внешней компоненты.
Демонстрация заложенного функционала
Произвольное имя внешней компоненты
Задача: Изменить имя внешней компоненты на произвольное.
В предыдущем разделе использовался идентификатор AddInNativeExtension, смысл которого не был пояснен. В данном случае AddInNativeExtension — это наименование расширения.
В коде ВК определен метод RegisterExtensionAs, возвращающий системе «1С: Предприятие» имя, которое необходимо для последующей регистрации ВК в системе. Рекомендуется указывать идентификатор, который в известной мере раскрывает суть внешней компоненты.
Приведем полный код метода RegisterExtensionAs с измененным наименованием расширения:
В приведенном примере имя ВК изменено на SomeName. Тогда при подключении ВК необходимо указывать новое имя:
Расширение списка свойств ВК
- Изучить реализацию свойств ВК
- Добавить свойство строкового типа, доступное для чтения и записи
- Добавить свойство строкового типа, доступное для чтения и записи, которое хранит тип данных последнего установленного свойства. При установке значения свойства никаких действий не производится
- Убедиться в работоспособности произведенных изменений
Полное описание методов, включая список параметров подробно описан в документации, поставляемой на диске ИТС.
Рассмотрим реализацию приведенных методов класса CAddInNative.
В демонстрационной ВК определены 2 свойства: Включен и ЕстьТаймер (IsEnabled и IsTimerPresent).
В глобальной области видимости кода библиотеки определено два массива:
которые хранят русское и английское названия свойств. В заголовочном файле AddInNative.h определяется перечисление:
- Добавить имя добавляемого свойства в массивы g_PropNames и g_PropNamesRu (файл AddInNative.cpp)
- В перечисление Props (файл AddInNative.h) перед ePropLast добавить имя, однозначно идентифицирующее добавляемое свойство
- Организовать память под хранение значений свойств (завести поля модуля компоненты, хранящие соответствующие значения)
- Внести изменения в методы GetPropVal и SetPropVal для взаимодействия с выделенной на предыдущем шаге памятью
- В соответствии с логикой приложения внести изменения в методы IsPropReadable и IsPropWritable
Перечисление Props будет иметь вид:
Для значительного упрощения кода будем использовать STL C++. В частности, для работы со строками WCHAR, подключим библиотеку wstring.
Для сохранения значения метода Тест, определим в классе CAddInNative в области видимости private поле:
Для передачи строковых параметров между «1С: Предприятие» и внешней компонентов используется менеджер памяти «1С: Предприятие». Рассмотрим его работу подробнее. Для выделения и освобождения памяти соответственно используются функции AllocMemory и FreeMemory, определенные в файле ImemoryManager.h. При необходимости передать системе «1С: Предприятие» строковый параметр, внешняя компонента должна выделить под нее память вызовом функции AllocMemory. Ее прототип выглядит следующим образом:
где pMemory — адрес указателя, в который будет помещен адрес выделенного участка памяти,
ulCountByte — размер выделяемого участка памяти.
Пример выделения памяти под строку:
Для удобства работы с строковыми типами данными опишем функцию wstring_to_p. Она получает в качестве параметра wstring-строку. Результатом функции является заполненная структура tVariant. Код функции:
Тогда соответствующая секция case оператора switch метода GetPropVal примет вид:
Метода SetPropVal:
Для реализации второго свойства определим поле класса CaddInNative
в котором будем сохранять тип последнего переданного значения. Для этого в метод CaddInNative::SetPropVal добавим команду:
Теперь при запросе чтения значения второго свойства будем возвращать значение last_type, чего требует обозначенное задание.
Проверим работоспособность произведенных изменений.
Для этого приведем внешний вид конфигурации 1С к виду:
Расширение списка методов
- Расширить функционал внешней компоненты следующим функционалом:
- Изучить способы реализации методов внешней компоненты
- Добавить метод-функцию Функц1, которая в качестве параметра принимает две строки («Параметр1» и «Параметр2»). В качестве результата возвращается строка вида: «Проверка. Параметр1, Параметр2»
- Убедиться в работоспособности произведенных изменений
- Добавить имя метода в массивы g_MethodNames и g_MethodNamesRu (файл AddInNative.cpp)
- Добавить осмысленный идентефикатор метода в перечисление Methods (файл AddInNative.h)
- Внести изменения в код функции GetNParams в соответствии с логикой программы
- При необходимости внести изменения в код метода GetParamDefValue, если требуется использовать значения по умолчанию параметров метода.
- Внести изменения в функцию HasRetVal
- Внести изменения в логику работы функций CallAsProc или CallAsFunc, поместив туда непосредственно исполняемый код метода
Отредактируем функцию GetNProps, чтобы она возвращала количество параметров метода «Тест»:
Внесем изменения в функцию CAddInNative::GetParamDefValue:
Благодаря добавленной строке
в случае отсутствия одного или нескольких аргументов соответствующие параметры будут иметь пустое значение (VTYPE_EMPTY). Если необходимо наличие значения по умолчанию для параметра, следует задать его в секции eMethTest оператора switch функции CAddInNative::GetParamDefValue.
Так как метод «Тест» может возвращать значение, необходимо внести изменения в код функции HasRetVal:
И добавим исполняемый код метода в функцию CallAsFunc:
Скомпилируем компоненту и приведем код конфигурации к виду:
Таймер
- Изучить реализацию таймера в демонстрационной ВК
- Модифицировать метод «СтартТаймер», добавив возможность передавать в параметрах интервал срабатывания таймера (в миллисекундах)
- Убедиться в работоспособности произведенных изменений
Рассмотрим реализацию таймера в демонстрационной ВК.
Так как мы рассматриваем процесс разработки внешней компоненты для ОС семейства Windows, не будем рассматривать реализацию таймера в других операционных системах. Для ОС GNU/Linux, в частности, реализация будет отличаться синтаксисом функции SetTimer и TimerProc.
В исполняемом коде вызывается метод SetTimer, в который передается функция MyTimerProc:
Идентефикатор созданного таймера помещается в переменную m_uiTimer, чтобы в последствии его можно было отключить.
Функция MyTimerProc выглядит следующим образом:
Приведем код метода CallAsProc к виду:
Теперь проверим работоспособность. Для этого в модуле управляемого приложения конфигурации напишем код:
Взаимодействие с системой «1С: Предприятие»
Тип данных tVariant
При обмене данными между внешней компонентой и системой «1С: Предприятие» используется тип данных tVariant. Он описан в файле types.h, который можно найти на диске с ИТС:
- смесь (union), предназначенную непосредственно для хранения данных
- идентификатор типа данных
- Определение типа данных, которые в данный момент хранятся в переменной
- Обращение к соответствующему полю смеси, для непосредственного доступа к данным
Приложение

Linux предоставляет мощный и обширный API для приложений, но иногда его недостаточно. Для взаимодействия с оборудованием или осуществления операций с доступом к привилегированной информации в системе нужен драйвер ядра.
Модуль ядра Linux — это скомпилированный двоичный код, который вставляется непосредственно в ядро Linux, работая в кольце 0, внутреннем и наименее защищённом кольце выполнения команд в процессоре x86–64. Здесь код исполняется совершенно без всяких проверок, но зато на невероятной скорости и с доступом к любым ресурсам системы.
Не для простых смертных
Написание модуля ядра Linux — занятие не для слабонервных. Изменяя ядро, вы рискуете потерять данные. В коде ядра нет стандартной защиты, как в обычных приложениях Linux. Если сделать ошибку, то повесите всю систему.
Ситуация ухудшается тем, что проблема необязательно проявляется сразу. Если модуль вешает систему сразу после загрузки, то это наилучший сценарий сбоя. Чем больше там кода, тем выше риск бесконечных циклов и утечек памяти. Если вы неосторожны, то проблемы станут постепенно нарастать по мере работы машины. В конце концов важные структуры данных и даже буфера могут быть перезаписаны.
Можно в основном забыть традиционные парадигмы разработки приложений. Кроме загрузки и выгрузки модуля, вы будете писать код, который реагирует на системные события, а не работает по последовательному шаблону. При работе с ядром вы пишете API, а не сами приложения.
У вас также нет доступа к стандартной библиотеке. Хотя ядро предоставляет некоторые функции вроде printk (которая служит заменой printf ) и kmalloc (работает похоже на malloc ), в основном вы остаётесь наедине с железом. Вдобавок, после выгрузки модуля следует полностью почистить за собой. Здесь нет сборки мусора.
Необходимые компоненты
Прежде чем начать, следует убедиться в наличии всех необходимых инструментов для работы. Самое главное, нужна машина под Linux. Знаю, это неожиданно! Хотя подойдёт любой дистрибутив Linux, в этом примере я использую Ubuntu 16.04 LTS, так что в случае использования других дистрибутивов может понадобиться слегка изменить команды установки.
Во-вторых, нужна или отдельная физическая машина, или виртуальная машина. Лично я предпочитаю работать на виртуальной машине, но выбирайте сами. Не советую использовать свою основную машину из-за потери данных, когда сделаете ошибку. Я говорю «когда», а не «если», потому что вы обязательно подвесите машину хотя бы несколько раз в процессе. Ваши последние изменения в коде могут ещё находиться в буфере записи в момент паники ядра, так что могут повредиться и ваши исходники. Тестирование в виртуальной машине устраняет эти риски.
И наконец, нужно хотя бы немного знать C. Рабочая среда C++ слишком велика для ядра, так что необходимо писать на чистом голом C. Для взаимодействия с оборудованием не помешает и некоторое знание ассемблера.
Установка среды разработки
На Ubuntu нужно запустить:
Устанавливаем самые важные инструменты разработки и заголовки ядра, необходимые для данного примера.
Примеры ниже предполагают, что вы работаете из-под обычного пользователя, а не рута, но что у вас есть привилегии sudo. Sudo необходима для загрузки модулей ядра, но мы хотим работать по возможности за пределами рута.
Начинаем
Приступим к написанию кода. Подготовим нашу среду:
Запустите любимый редактор (в моём случае это vim) и создайте файл lkm_example.c следующего содержания:
Мы сконструировали самый простой возможный модуль, рассмотрим подробнее самые важные его части:
- В include перечислены файлы заголовков, необходимые для разработки ядра Linux.
- В MODULE_LICENSE можно установить разные значения, в зависимости от лицензии модуля. Для просмотра полного списка запустите:
Если мы запускаем make , он должен успешно скомпилировать наш модуль. Результатом станет файл lkm_example.ko . Если выскакивают какие-то ошибки, проверьте, что кавычки в исходном коде установлены корректно, а не случайно в кодировке UTF-8.
Теперь можно внедрить модуль и проверить его. Для этого запускаем:
Если всё нормально, то вы ничего не увидите. Функция printk обеспечивает выдачу не в консоль, а в журнал ядра. Для просмотра нужно запустить:
Вы должны увидеть строку “Hello, World!” с меткой времени в начале. Это значит, что наш модуль ядра загрузился и успешно сделал запись в журнал ядра. Мы можем также проверить, что модуль ещё в памяти:
Для удаления модуля запускаем:
Если вы снова запустите dmesg, то увидите в журнале запись “Goodbye, World!”. Можно снова запустить lsmod и убедиться, что модуль выгрузился.
Как видите, эта процедура тестирования слегка утомительна, но её можно автоматизировать, добавив:
в конце Makefile, а потом запустив:
для тестирования модуля и проверки выдачи в журнал ядра без необходимости запускать отдельные команды.
Теперь у нас есть полностью функциональный, хотя и абсолютно тривиальный модуль ядра!
Немного интереснее
Копнём чуть глубже. Хотя модули ядра способны выполнять все виды задач, взаимодействие с приложениями — один из самых распространённых вариантов использования.
Поскольку приложениям запрещено просматривать память в пространстве ядра, для взаимодействия с ними приходится использовать API. Хотя технически есть несколько способов такого взаимодействия, наиболее привычный — создание файла устройства.
Вероятно, раньше вы уже имели дело с файлами устройств. Команды с упоминанием /dev/zero , /dev/null и тому подобного взаимодействуют с устройствами “zero” и “null”, которые возвращают ожидаемые значения.
В нашем примере мы возвращаем “Hello, World”. Хотя это не особенно полезная функция для приложений, она всё равно демонстрирует процесс взаимодействия с приложением через файл устройства.
Вот полный листинг:
Тестирование улучшенного примера
Теперь после запуска make test вы увидите выдачу старшего номера устройства. В нашем примере его автоматически присваивает ядро. Однако этот номер нужен для создания нового устройства.
Возьмите номер, полученный в результате выполнения make test , и используйте его для создания файла устройства, чтобы можно было установить коммуникацию с нашим модулем ядра из пространства пользователя.
(в этом примере замените MAJOR значением, полученным в результате выполнения make test или dmesg )
Параметр c в команде mknod говорит mknod, что нам нужно создать файл символьного устройства.
Теперь мы можем получить содержимое с устройства:
или даже через команду dd :
Вы также можете получить доступ к этому файлу из приложений. Это необязательно должны быть скомпилированные приложения — даже у скриптов Python, Ruby и PHP есть доступ к этим данным.
Когда мы закончили с устройством, удаляем его и выгружаем модуль:
Заключение
Надеюсь, вам понравились наши шалости в пространстве ядра. Хотя показанные примеры примитивны, эти структуры можно использовать для создания собственных модулей, выполняющих очень сложные задачи.
Просто помните, что в пространстве ядра всё под вашу ответственность. Там для вашего кода нет поддержки или второго шанса. Если делаете проект для клиента, заранее запланируйте двойное, если не тройное время на отладку. Код ядра должен быть идеален, насколько это возможно, чтобы гарантировать цельность и надёжность систем, на которых он запускается.
Читайте также: