
1с dbcc checkdb как запустить
Как обнаружить, что база данных повреждена
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0xfdff74c9; actual: 0xfdff74cb). It occurred during a read of page (1:69965) in database ID 13 at offset 0x0000002229a000 in file 'D:\Develop\Databases\Broken1.mdf'.
Attempt to fetch logical page 1:69965 in database 13 failed. It belongs to allocation unit 72057594049069056 not to 281474980642816.
Что делать если база данных все-таки повреждена
- Не паниковать
- Не отсоединять (detach) ее
- Не перезапускать SQL Server
- Не начинать восстановление сразу
- Запустить проверку целостности
- Найти причину
Не паниковать
Самое важное, при обнаружении повреждения БД — это не паниковать. Любые принимаемые решения должны быть тщательно взвешаны, во внимание должны быть приняты все возможные факторы. Чертовски просто ухудшить ситуацию приняв не до конца обдуманное решение.
Не отсоединять базу данных
В большинстве случаев, когда SQL Server обнарживает повреждение базы данных, это означает, что в БД на самом деле есть поврежденные страницы. Попытка убедить SQL Server что это не так, путем отсоединения (detach) и повторного присоединения (attach) БД, бэкапа и последующего восстановления, перезапуска службы SQL Server, либо перезагрузки сервера, не приведет к тому, что ошибка исчезнет.
Если база данных повреждена и SQL Server обнаружит это при присоединении, он не сможет присоединить ее. Есть несколько способов заставить его увидеть эту БД, но намного лучше просто не отсоединять ее.
Не перезапускать SQL Server
Не начинать восстановление сразу
У вас может возникнуть соблазн просто запустить DBCC CHECKDB с одним из «восстановительных» параметров (обычно допускающими потерю данных) и надеяться, что все станет лучше (по моему опыту — первое что рекомендуют на «непрофильных» форумах по SQL Server — запустить DBCC CHECKDB REPAIR_ALLOW_DATA_LOSS — прим. переводчика). Во многих случаях запуск такого восстановления не рекомендуется. Он не гарантирует исправления всех ошибок и может привести к недопустимой потере данных.
Такое восстановление — это последний шаг при исправлении ошибок. Оно должно быть запущено только если у вас уже нет другого выбора, но никак не в первую очередь.
Запустить проверку целостности
Найти причину
После того как ошибки исправлены, работу нельзя считать законченной. Если причина этих ошибок не установлена, они могут возникнуть снова. Обычно, основной причиной ошибок являются проблемы с подсистемой ввода-вывода, но они также могут быть вызваны неправильной работой «низкоуровнего ПО» (вроде антивируса), действиями человека, либо багами самого SQL Server.
Что дальше
Дальнейшие действия по исправлению ошибок целиком и полностью зависят от результатов выполнения CheckDB. Чуть дальше я покажу несколько наиболее часто возникающих ошибок (учтите, что эта статья не претендует на звание полного описания всевозможных ошибок).
Описанные ошибки располагаются по возрастанию уровня серьезности — от наименее серьезных к наиболее серьезным. В общем-то, для наиболее серьезных ошибок, находимых CheckDB, есть описание доступных методов их резрешения.
Если у вас вдруг обнаружится ошибка не описанная в статье, обратите внимание на последний раздел — «Поиск помощи».
Неверная информация о свободном месте на странице
Msg 2508, Level 16, State 3, Line 1
The In-row data RSVD page count for object «Broken1», index ID 0, partition ID 76911687695381, alloc unit ID 76911687695381 (type In-row data) is incorrect. Run DBCC UPDATEUSAGE.
Msg 8914, Level 16, State 1, Line 1
Incorrect PFS free space information for page (1:26839) in object ID 181575685, index ID 1, partition ID 293374720802816, alloc unit ID 76911687695381 (type LOB data). Expected value 0_PCT_FULL, actual value 100_PCT_FULL.
Эта ошибка появляется, когда PFS-страница (Page Free Space), которая учитывает насколько заполнены страницы в БД, содержит некорректные значения. Эта ошибка, как и упомянутая ранее, не является серьезной. Алгоритм, по которому определялось насколько заполнены страницы, в SQL Server 2000 не всегда отрабатывал правильно. Для решения этой проблемы нужно запустить DBCC CHECKDB с параметром REPAIR_ALLOW_DATA_LOSS и, если это единственная ошибка в БД, никакие данные, на самом деле, не пострадают.
Повреждение только некластерных индексов
Если все ошибки, найденные CheckDB, относятся к индексам с и больше, это означет, что были повреждены только некластерные индексы. Поскольку информация, содержащаяся в некластерных индексах, является «избыточной» (те же самые данные хранятся в куче, либо в кластерном индексе — прим. переводчика), эти повреждения могут быть исправлены без потери каких-либо данных.
Если все ошибки, найденные CheckDB, относятся к некластерным индексам, рекомендуемый «уровень восстановления» для DBCC CHECKDB — REPAIR_REBUILD. Примеры таких ошибок (на самом деле ошибок такого типа намного больше):
Msg 8941, Level 16, State 1, Line 1
Table error: Object ID 181575685, index ID 4, page (3:224866). Test (sorted [i].offset >= PAGEHEADSIZE) failed. Slot 159, offset 0x1 is invalid.
Msg 8942, Level 16, State 1, Line 1
Table error: Object ID 181575685, index ID 4, page (3:224866). Test (sorted[i].offset >= max) failed. Slot 0, offset 0x9f overlaps with the prior row.
В этом случае, повреждение может быть полностью исправлено удалением поврежденных некластерных индексов и повторным их созданием. Перестроение индекса (ALTER INDEX REBUILD) в режиме on-line (и иногда в off-line) читает страницы старого индекса для создания нового и, следовательно, завершится с ошибкой. Поэтому, необходимо удалить старые индексы и создать их заново.
Именно это сделает DBCC CHECKDB с параметром REPAIR_REBUILD, но база данных при этом должна быть в однопользовательском режиме. Вот почему обычно лучше вручную выполнить эти операции, чтобы с базой данных можно было продолжать работать, пока индексы будут пересоздаваться.
Если у вас недостаточно времени на то, чтобы пересоздать нужные индексы и в наличии есть «чистый» (не содержащий в себе ошибок) полный бэкап и бэкапы журнала транзакций с неразорванной цепочкой журналов, вы можете восстановить поврежденные страницы из них.
Повреждение LOB-страниц
Msg 8964, Level 16, State 1, Line 1
Table error: Object ID 181575685, index ID 1, partition ID 72057594145669120, alloc unit ID 72057594087800832 (type LOB data). The off-row data node at page (1:2444050), slot 0, text ID 901891555328 is not referenced.
Ошибка говорит о том, что существуют LOB-страницы (Large OBject), на которые не ссылается ни одна страница с данными. Такое может произойти, если ранее был поврежден кластерный индекс (или куча) и его поврежденные страницы были удалены.
Если CheckDB говорит только о таких ошибках, то можно запускать DBCC CHECKDB с параметром REPAIR_ALLOW_DATA_LOSS — эти страницы будут уничтожены. Поскольку у вас все равно нет страниц с данными, которые ссылаются на эти страницы, бОльшей потери данных уже не будет.
Ошибки, связанные с выходом за пределы допустимого диапазона
Msg 2570, Sev 16, State 3, Line 17
Page (1:1103587), slot 24 in object ID 34, index ID 1, partition ID 281474978938880, alloc unit ID 281474978938880 (type «In-row data»). Column «modified» value is out of range for data type «datetime». Update column to a legal value.
Повреждение кластерного индекса или кучи
Server: Msg 8976, Level 16, State 1, Line 2
Table error: Object ID 181575685, index ID 1, partition ID 76911687695381, alloc unit ID 76911687695381 (type In-row data). Page (1:22417) was not seen in the scan although its parent (1:479) and previous (1:715544) refer to it.
Server: Msg 8939, Level 16, State 1, Line 2
Table error: Object ID 181575685, index ID 0, page (1:168576). Test (m_freeData >= PAGEHEADSIZE && m_freeData
Следует помнить, что если ошибки, возвращаемые CheckDB, относятся к index или 1, это значит, что повреждены непосредственно данные.
Такой тип ошибок исправляется, но исправление заключается в уничтожении строк или целых страниц. Когда CheckDB удаляет данные для исправления ошибки, ограничения, налагаемые внешними ключами, не проверяются и никакие триггеры не срабатывают. Строки или страницы просто удаляются. В результате данные могут оказаться не согласованными, либо может быть нарушена логическая целостность (на LOB-страницы может больше не ссылаться ни одна строка, либо строки некластерного индекса могут указывать «в никуда»). Из-за таких последствий, подобное восстановление, не рекомендуется использовать.
Если у вас есть «чистый» бэкап, восстановление из него обычно является более предпочительным, для исправления таких ошибок. Если база данных находится в полной модели восстановления и у вас есть бэкапы журнала транзакций с неразорванной цепочкой журналов (начиная с последнего «чистого» полного бэкапа), вы можете сделать бэкап активной части лога и восстановить базу данных целиком (или только поврежденные страницы), в результате чего данные вообще не будут потеряны.
Если бэкапа с неповрежденными данными нет, у вас остается только один вариант — запуск DBCC CHECKDB с параметром REPAIR_ALLOW_DATA_LOSS. Это потребует перевода базы данных в однопользовательский режим на все время выполнения этой процедуры.
И хотя у вас нет возможности избежать потери данных, вы можете посмотреть какие данные будут удалены из кластерного индекса. Для этого, посмотрите этот пост Пола Рэнадала.
Повреждение метаданных
Msg 3853, Level 16, State 1, Line 1
Attribute (object_id=181575685) of row (object_id=181575685,column_id=1) in sys.columns does not have a matching row (object_id=181575685) in sys.objects.
Неисправимые повреждения
Повреждение системных таблиц
Msg 7985, Level 16, State 2, Line 1
System table pre-checks: Object ID 4. Could not read and latch page (1:358) with latch type SH.
Check statement terminated due to unrepairable error.
Msg 8921, Level 16, State 1, Line 1
Check terminated. A failure was detected while collecting facts. Possibly tempdb out of space or a system table is inconsistent.
Повреждение «карт распределения»
Msg 8946, Level 16, State 12, Line 1
Table error: Allocation page (1:2264640) has invalid PFS_PAGE page header values. Type is 0. Check type, alloc unit ID and page ID on the page.
Msg 8998, Level 16, State 2, Line 1
Page errors on the GAM, SGAM, or PFS pages prevent allocation integrity checks in database ID 13 pages from (1:2264640) to (1:2272727)
Поиск помощи
Заключение
В этой статье я дал несколько примеров того, что можно сделать при обнаружении поврежденной БД и, что даже важнее, того, что делать не надо. Надеюсь, что теперь вы лучше понимаете какие методы можно применять для решения описанных проблем и насколько важно иметь хорошие бэкапы (и правильно выбрать модель восстановления — прим. переводчика).

Примечание: это мой первый перевод, который, к тому же делался не за раз, а в несколько подходов, вечерами, когда появлялось свободное время, поэтому текст целиком, возможно, кому-то покажется несколько несогласованым. Если где-то я был излишне косноязычен и какая-то часть текста вдруг окажется трудной для понимания — с радостью выслушаю все замечания.
С уважением, unfilled.
P.S. Когда я уже собрался было нажать на кнопочку «Опубликовать», мне на почту свалилась рассылка от SQL Server Central с вот таким вот комиксом.
Сразу оговорюсь, что мои познания в T-SQL не сильно велики т. к. по большей части пишу код для конфигураций на платформе 1С:Предприятие, и предложенное решение может быть не совсем оптимальным.
Оптимизация и улучшения предложенного скрипта приветствуется.
Небольшое предисловие.
Часто случается, что базы данных повреждаются, по различным причинам, и мы не всегда это вовремя замечаем.
Что бы проверить базу данных надо зайти в интерфейс, запустить скрипт, получить результат. И уже в зависимости от результата принимать какие-то решения и действия. Возможно это нормально, когда есть свободно время и не лень запустить скрипт вручную. Но что делать когда, к примеру, на поддержке с 10-к и более баз и находятся они на разных серверах. Подключаться к каждому серверу и запускать скрипт руками занимает много времени, да делать это вручную лень.
Для разработчика, администратора и т. п. л ень это двигатель его прогресса, настроил систему как надо и читай логи, письма и прочее оповещения.
Вот после очередного повреждения базы, я опять вернулся к задаче проверки целостности баз по регламенту и рассылке результата на почту. Ранее я уже занимался этой задачей но не доделал, точнее не нашел нужного мне решения.
Это было небольшое предисловие, теперь перейдем к самой задаче.
Целью задачи было: проверять целостность баз данных 1с на сервере SQL по регламенту и при обнаружении поврежденной базы оповещать по почте. Оповещение только если найдена поврежденная база. Состав письма краткий, все данные результата проверки высылать не требуется.
Поиски готового решения в интернете ничего не дали. Нашел всего одно решение, но оно мне не подходит. Кому интересно, можете ознакомится с публикацией Отправляем результаты задания DBCC CHECKDB по электронной почте.
На просторах интернета прочитал, что данные можно вывести в таблицу.
DBCC CHCKDB WITH TABLERESULTS выведет данные в таблицу, но просто так взять и сделать выборку из из этой таблицы нельзя, но выход все же нашелся.
В поисках нужной информации для решения моей задачи наткнулся на публикацию Спасибо тебе R odert Pearl , что ты ее когда то написал.
1. Создаем временную таблицу.
Исходное описание таблицы немного изменено.
Добавлена колонка "DatabaseName".
Изменил типы данных в некоторых колонках, т.к. при первом же тесте получил ошибки о невозможности преобразования типов данных
Колонки: PartitionID, AllocUnitID изменил тип данных с INT на BIGINT ,
Колонка: RepairLevel с INT на VARCHAR(300)
В каких колонках нужно менять тип данных искал методом тыка и исключения.
2. В ранее созданную временную таблицу, при помощи CURSOR , по списку баз, поместим выходные данные DBCC CHCKDB .
У меня есть база 'Recovery', использую для разных целей. Сегодя она играет роль поврежденной базы данных. Результ ее проверки и поместим во временную таблицу.
DECLARE @database_name NVARCHAR(50)
DECLARE database_cursor CURSOR FOR
SELECT name
FROM sys.databases db
WHERE name = 'Recovery'
AND db.state_desc = 'ONLINE'
AND source_database_id IS NULL -- REAL DBS ONLY (Not Snapshots)
AND is_read_only = 0
OPEN database_cursor
FETCH NEXT FROM database_cursor INTO @database_name
WHILE @@FETCH_STATUS=0
BEGIN
FETCH NEXT FROM database_cursor INTO @database_name
END
CLOSE database_cursor
DEALLOCATE database_cursor
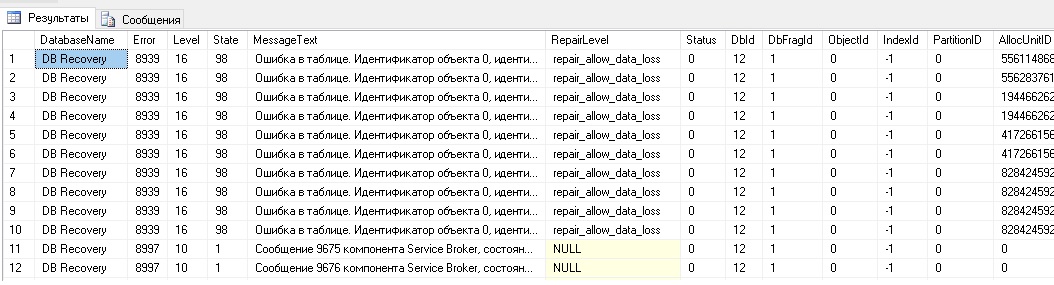
Теперь с данными можно работать, накладывать отборы, делать сортировку и все остальное.
Мне на выходе нужна одна строка с описанием ошибок. Строку собираю из колонок: DatabaseName , MessageText при помощи конкатенации. Дополнительно накладываю условия на ' MessageText ', что бы получить нужные строки, т.к. если база не повреждена данные в выходном наборе все равно будут. Только в тексте будет количество ошибок "0". Мне эти данные не нужны.
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 10 ошибок согласованности, не связанных ни с одним объектом.
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 30 ошибок согласованности в таблице "_InfoRg23950" (идентификатор объекта 469889041).
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 9 ошибок согласованности в таблице "_Reference12359" (идентификатор объекта 956790716).
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 5 ошибок согласованности в таблице "_InfoRg24673" (идентификатор объекта 1015882886).
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 3 ошибок согласованности в таблице "_InfoRg9101" (идентификатор объекта 1179359466).
DB Recovery: CHECKDB обнаружил 0 ошибок размещения и 57 ошибок согласованности в базе данных "Recovery".
Осталось проверить есть ли у нас в сформированной строке данные, при их наличии отправляем данные на почту.
EXEC msdb.dbo.sp_send_dbmail
@profile_name = @Profilename,
@recipients = @Recipients,
@body = @MSG,
@subject = @Msubject;
END
GO
Проверяем скрипт, все работает.
Создаем Job, настраиваем расписание и готово
DECLARE @database_name NVARCHAR(50)
DECLARE database_cursor CURSOR FOR
SELECT name
FROM sys.databases db
WHERE name = 'Recovery'
AND db.state_desc = 'ONLINE'
AND source_database_id IS NULL -- REAL DBS ONLY (Not Snapshots)
AND is_read_only = 0
OPEN database_cursor
FETCH NEXT FROM database_cursor INTO @database_name
WHILE @@FETCH_STATUS=0
BEGIN
FETCH NEXT FROM database_cursor INTO @database_name
END
CLOSE database_cursor
DEALLOCATE database_cursor
EXEC msdb.dbo.sp_send_dbmail
@profile_name = @Profilename,
@recipients = @Recipients,
@body = @MSG,
@subject = @Msubject;
END
GO
Все началось с того, что после проблем с жестким диском на сервере и "не совсем удачным" восстановлением рабочей базы данных 1С начала сообщать "could not continue scan with nolock" при проведении документов и закрываться с непоправимой ошибкой. Бэкап был, но не самый свежий, а данные терять не хотелось. Что же лучше делать?
Первым делом нужно сделать резервную копию.
Далее запускаем в SQL Management Studio и выполняем DBCC CHECKDB. Выполняем ее так, чтобы данные не терялись, параметр REPAIR_ALLOW_DATA_LOSS оставим на случай совсем безнадежный.
Например, наша база называется Office
Выполняем следующие запросы:
ALTER DATABASE Office
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
GO
DBCC CHECKDB (N'Office', REPAIR_REBUILD) WITH NO_INFOMSGS
GO
Msg 8928, Level 16, State 1, Line 2
Object ID 814625945, index ID 1, partition ID 72057594157203456, alloc unit ID 72057594154844160 (type In-row data): Page (1:3605) could not be processed. See other errors for details.
The repair level on the DBCC statement caused this repair to be bypassed.
Msg 8939, Level 16, State 98, Line 2
Table error: Object ID 814625945, index ID 1, partition ID 72057594157203456, alloc unit ID 72057594154844160 (type In-row data), page (1:3605). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 12584969 and -4.
Repairing this error requires other errors to be corrected first.
Msg 8976, Level 16, State 1, Line 2
Table error: Object ID 814625945, index ID 1, partition ID 72057594157203456, alloc unit ID 72057594154844160 (type In-row data). Page (1:3605) was not seen in the scan although its parent (1:6481) and previous (1:8859) refer to it. Check any previous errors.
Repairing this error requires other errors to be corrected first.
CHECKDB found 0 allocation errors and 8 consistency errors in table 'DT3311' (object ID 1970106059).
CHECKDB found 0 allocation errors and 43 consistency errors in database 'Office'.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (Office, repair_rebuild).
После проверки выполняем запрос для дальнейших операций с базой данных:
ALTER DATABASE Office
SET MULTI_USER;
Как восстанавливать поврежденные страницы писать не буду. Статья рассчитана на простое администрирование и поможет даже при модели Simple. Те, кто делают бэкапы логов журнала транзакций очень-очень часто, сюда заходить не будут. Единственное условие - нам потребуется резервная копия (будем надеяться, что по теории вероятности самые свежие данные мы спасли без повреждений и бэкапы хоть иногда делали).
Как видим, все ошибки относятся к index или index Это говорит о том, что повреждены данные. Но не будем отчаиваться и воспользуемся резервной копией.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0xacafd5b7; actual: 0x21c9cf6a). It occurred during a read of page (1:8473) in database ID 8 at offset 0x00000004232000 in file 'E:\SQL_Data\Office.mdf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
Обращаем внимание, на какой строке таблицы останавливается запрос при полном показе содержимого таблицы в графическом интерфейсе. Например, он показал нам данные до строки 1915.
Проверяем: запрос Select top 1915 * From DT3311 выполняется, а Select top 1916 * From DT3311 - уже нет.
Смотрим резервную базу, поле IDDOC в таблице начиная со строки 1916, это документ с ID ' 1SP '
В рабочей базе мы ничего с документом не можем сделать: ни открыть его в 1С, ни прочитать его табличную часть, ни удалить его. Что делать?
Предлагаю перебросить по кусочкам данные из разных баз (рабочей и резервной), удалить таблицу в рабочей базе, создать ее повторно и положить данные на место.
Создаем временную базу test, в ней создаем такую же таблицу DT3311 (для тех, кто не знает как это сделать быстро - картинки ниже на примере создания индексов) и выполняем запрос:
Insert into Test.dbo.DT3311
Select * From DT3311 Where IDDOC <> ' 1SP '
Запрос выполнился без ошибок. Это говорит о том, что других данных с "мусором" в этой таблице нет.
Данные о поврежденном документе берем из резервной копии. Выполняем запрос в резервной базе:
Insert into Test.dbo.DT3311
Select * From DT3311 Where IDDOC = ' 1SP '
Теперь в тестовой базе есть полные данные. Удаляем таблицу в рабочей базе, создаем заново и выполняем запрос:
Insert into DT3311
Select * From Test.dbo.DT3311
Пробуем прочитать полностью другие таблицы, ведь мы помним, что не проводились документы. Выясняется, что не могут прочитаться некоторые таблицы итогов регистров (RGXXX). В данном случае можно просто удалить эти таблицы, данные в них восстановит сама 1С. Заходим монопольно в 1С: Предприятие, сдвигаем ТА на самый первый документ, затем на самый последний проведенный документ. В результате итоги по регистрам пересчитаются.
Производим повторную проверку ошибок и убеждаемся в их отсутствии.
Беремся за другую базу, Acc.
Выполняем следующие запросы:
ALTER DATABASE Acc
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
GO
DBCC CHECKDB (N'Acc', REPAIR_REBUILD) WITH NO_INFOMSGS
GO
Для нее мы получили такой перечень ошибок:
Msg 8978, Level 16, State 1, Line 2
Table error: Object ID 1685581043, index ID 6, partition ID 72057594149928960, alloc unit ID 72057594147569664 (type In-row data). Page (1:17191) is missing a reference from previous page (1:19106). Possible chain linkage problem.
Repairing this error requires other errors to be corrected first.
Msg 8928, Level 16, State 1, Line 2
Object ID 1685581043, index ID 6, partition ID 72057594149928960, alloc unit ID 72057594147569664 (type In-row data): Page (1:19106) could not be processed. See other errors for details.
The repair level on the DBCC statement caused this repair to be bypassed.
Msg 8939, Level 16, State 98, Line 2
Table error: Object ID 1685581043, index ID 6, partition ID 72057594149928960, alloc unit ID 72057594147569664 (type In-row data), page (1:19106). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 62916617 and -4.
Repairing this error requires other errors to be corrected first.
Msg 8976, Level 16, State 1, Line 2
Table error: Object ID 1685581043, index ID 6, partition ID 72057594149928960, alloc unit ID 72057594147569664 (type In-row data). Page (1:19106) was not seen in the scan although its parent (1:20741) and previous (1:15201) refer to it. Check any previous errors.
Repairing this error requires other errors to be corrected first.
CHECKDB found 0 allocation errors and 4 consistency errors in table 'SC59729' (object ID 1685581043).
CHECKDB found 0 allocation errors and 4 consistency errors in database 'Acc'.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (Acc, repair_rebuild).
Не забываем вернуть доступ к базе данных:
ALTER DATABASE Acc
SET MULTI_USER;
Для начала запишем скрипты на создание индексов (поочередно):
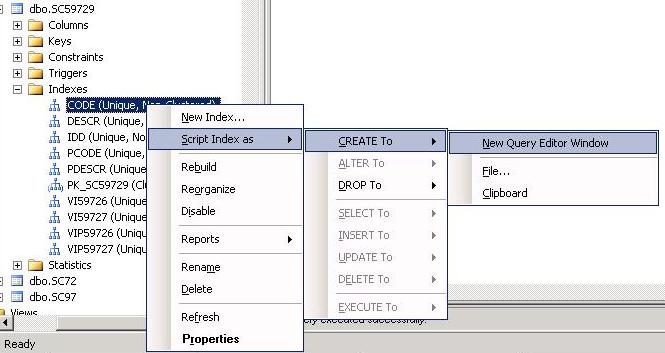
Затем удаляем индексы:
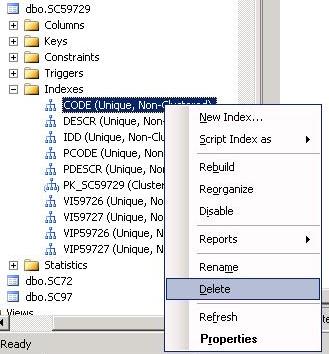
Затем выполним поочередно скрипты по созданию индексов в открытых окнах, попутно закрывая их (чтобы ничего не забыть).
Все исправили, производим повторную проверку и убеждаемся в отсутствии ошибок.

Поступила жалоба от бухгалтера о проблемах с проведением документов в 1С.

Из скриншота выяснилось, что 1С «ругается» на проблемы с согласованностью «внутри» базы данных и предлагает провести проверку на согласованность.
Переходим в SQL Server Management Studio и, сделав, на всякий случай, бэкап текущего состояния, выполняем проверку:
Для начала переводим нужную нам БД в однопользовательский режим
Запускаем Окно запросов (CTRL+N). Выбираем Новый запрос и вводим запрос Transact-SQL (T-SQL) в этом окне:
Далее, вводим запрос на сканирование базы данных:
Проверка продлилась около 15 минут, после чего выдала следующее:
CHECKDB обнаружил 0 ошибок размещения и 766 ошибок согласованности, не связанных ни с одним объектом.
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysdbfiles" (идентификатор объекта 20).
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysxmlcomponent" (идентификатор объекта 91).
CHECKDB обнаружил 0 ошибок размещения и 49 ошибок согласованности в таблице "_AccRg1025" (идентификатор объекта 1778313595).
CHECKDB обнаружил 0 ошибок размещения и 3 ошибок согласованности в таблице "_AccRgAT21046" (идентификатор объекта 1826313766).
CHECKDB обнаружил 0 ошибок размещения и 1783 ошибок согласованности в таблице "_AccRg1051" (идентификатор объекта 1906314051).
CHECKDB обнаружил 0 ошибок размещения и 2603 ошибок согласованности в базе данных "KA".
Вариант решения №1: восстановление из бэкапа выявило накопительный характер ошибки: чем раньше сделан бэкап – тем меньше в базе ошибок, вплоть до самого «дальнего» (14 дней). Примерно на третьем бэкапе количество ошибок перестало уменьшаться – стало ясно, что этим путём мы придём только к потере актуальности базы и проблему не решить
Вариант решения №2: В справочной информации описаны три возможных варианта исправления этих ошибок, рассмотрим каждый:
REPAIR_FAST
Синтаксис поддерживается только для обеспечения обратной совместимости. Действия по восстановлению не выполняются.
REPAIR_REBUILD
Выполняет действия по восстановлению данных, которые можно выполнить без риска их потери. Это может быть быстрое восстановление (например, восстановление отсутствующих строк в некластеризованных индексах) или более ресурсоемкие операции (например, перестроение индекса).
REPAIR_ALLOW_DATA_LOSS
Пытается устранить все обнаруженные ошибки. Эти исправления могут привести к частичной потере данных.
Аргумент REPAIR_FAST нам не подходит, REPAIR_ALLOW_DATA_LOSS оставим на крайний случай - пробуем REPAIR_REBUILD:
CHECKDB обнаружил 0 ошибок размещения и 766 ошибок согласованности, не связанных ни с одним объектом.
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysdbfiles" (идентификатор объекта 20).
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysxmlcomponent" (идентификатор объекта 91).
CHECKDB обнаружил 0 ошибок размещения и 49 ошибок согласованности в таблице "_AccRg1025" (идентификатор объекта 1778313595).
CHECKDB обнаружил 0 ошибок размещения и 3 ошибок согласованности в таблице "_AccRgAT21046" (идентификатор объекта 1826313766).
CHECKDB обнаружил 0 ошибок размещения и 1783 ошибок согласованности в таблице "_AccRg1051" (идентификатор объекта 1906314051).
CHECKDB обнаружил 0 ошибок размещения и 2603 ошибок согласованности в базе данных "KA".
Не помогло, переводим базу данных обратно в многопользовательский режим:
На всякий случай, я попробовал провести обслуживание базы данных и перепроверил – результат тот же.
Решил провести тестирование и исправление информационной базы средствами 1С, на что получил ошибку

Выгрузить базу данных в *.dt файл тоже не удалось:

Что ж, стало понятно, что часть потерянных данных – меньшее зло, по сравнению с «развалившейся» базой данных, пробуем REPAIR_ALLOW_DATA_LOSS:
И, наконец, после нескольких прогонов, количество ошибок немного уменьшилось:
CHECKDB обнаружил 0 ошибок размещения и 733 ошибок согласованности, не связанных ни с одним объектом.
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysdbfiles" (идентификатор объекта 20).
CHECKDB обнаружил 0 ошибок размещения и 1 ошибок согласованности в таблице "sys.sysxmlcomponent" (идентификатор объекта 91).
CHECKDB обнаружил 0 ошибок размещения и 1783 ошибок согласованности в таблице "_AccRg1051" (идентификатор объекта 1906314051).
CHECKDB обнаружил 0 ошибок размещения и 2518 ошибок согласованности в базе данных "KA ".
Ситуацию это не спасло: база, по-прежнему не выгружалась и не «лечилась» средствами 1С.
Дальнейшие попытки (по очереди несколько раз запускал REPAIR_REBUILD и REPAIR_ALLOW_DATA_LOSS) не увенчались успехом: количество ошибок не уменьшилось, база, по-прежнему, не выгружалась и не «лечилась».
Коллеги подсказали попробовать очистить (именно очистить, без удаления самой таблицы) «проблемную» таблицу в MS SQL.
Больше всего ошибок в таблице "_AccRg1051" – ей и было принято решение заняться:
И, после успешного выполнения, прогоняем проверку еще раз:
15 минут ожидания и, о чудо – все ошибки исчезли, в том числе и в остальных таблицах.
Перевожу базу в многопользовательский режим, выгружаю в *.dt файл и загружаю обратно.
Звоню бухгалтеру – прошу проверить проблемные документы: всё работает нормально. Пускаю остальных пользователей в базу.
Через час снова ошибка:

Делаем вывод, что выгрузка в *.dt – не панацея. Выгоняем Вежливо просим пользователей выйти и ещё немного потерпеть и тестируем базу с исправлением ошибок в режиме конфигуратора 1С со следующими параметрами

Видим, что всё ОК

Пускаем обратно пользователей в 1С и идём молиться настраивать планы обслуживания баз данных.
Статья Gail Shaw «Help, my database is corrupt. Now what?», перевод которой я запостил на прошлой неделе, вызвала, вроде бы, определенный интерес, но она, увы, не содержала «практики». Да, там написано как можно спасти данные, но нет никаких примеров.
Изначально я хотел сделать еще один перевод все того же автора, но, подумав, решил написать пост «от себя», как бы «по мотивам». Причины, побудившие меня поступить так, я опишу в конце поста, в примечаниях.
Восстановление баз данных в SQL Server
Как уже было сказано в предыдущей статье, в том случае, если повреждены страницы кластерного индекса или кучи, то данные, содержащиеся на этих страницах, потеряны и единственным вариантом для их восстановления является непосредственно восстановление базы данных.
SQL Server предоставляет множество возможностей для восстановления баз данных. Во-первых, это восстановление базы данных целиком — оно может занимать довольно много времени (зависит от размера БД и скорости жестких дисков). Во-вторых, восстановление отдельных файловых групп, либо файлов, если ваша БД состоит из нескольких файловых групп (или, соответствено, файлов). В этом случае, есть возможность восстановления только поврежденных частей БД, не затрагивая остальных. Эти два вида восстановления БД используются довольно часто и затрагиваться в дальнейшем не будут.
В-третьих, в SQL Server 2005 появилась возможность восстановления отдельных страниц БД — в этом случае из бэкапа будут восстановлены только указанные страницы. Такое восстановление будет особенно актуально, если DBCC CHECKDB найдет несколько поврежденных страниц в какой-нибудь огромной таблице, «лежащей» в здоровенном файле. За счет того, что восстанавливаться будет не весь файл, и даже не вся таблица, а только несколько страниц — время простоя может быть значительно сокращено.
Требования и ограничения
Модель восстановления и доступность резервных копий журнала транзакций
Самое главное, что нужно помнить — для восстановления отдельных страниц, база данных должна использовать полную (full) модель восстановления, либо модель восстановления с неполным протоколированием (bulk-logged). Если ваши базы находятся в простой (simple) модели восстановления — дальше вы можете уже и не читать.
Второе требование — ваши полные бэкапы и бэкапы журнала транзакций должны образовывать неразрывную цепочку журналов (log chain). Если вы никогда не выполняете команду BACKUP LOG WITH TRUNCATE_ONLY (NO_LOG) и не переключаетесь в простую модель восстановления для того, чтобы уменьшить журнал транзакций, и у вас есть ВСЕ резервные копии журнала транзакций с момента последней полной резервной копии не содержащей поврежденных страниц (включая эту самую полную резервную копию) — за цепочку журналов можно не волноваться.
В модели восстановления с неполным протоколированием, теоретически, восстановление отдельных страниц должно работать нормально в том случае, если соблюдаются условия описанные выше, и восстанавливаемые страницы не изменялись операциями, выполняемыми с минимальным протоколированием.
Редакции SQL Server
Восстановление страниц возможно в любой редакции SQL Server, но для редакций Enterprise Edition и Developer Edition возможно восстановление поврежденных страниц on-line, т.е. к базе данных, во время восстановления, можно обращаться (и более того, обращаться можно даже к той таблице, к которой относятся восстанавливаемые в данный момент страницы, если сами эти страницы не будут «затрагиваться» — в противном случае, запрос завершится ошибкой). Для редакций «ниже» Enterprise Edition, восстановление страниц проходит в режиме off-line и база данных, на время восстановления, становится недоступной.
Тип поврежденной страницы
Собственно, восстановление
Теперь, наконец, переходим от теории к практике.
В первую очередь, для тренировки, нужна испорченная база данных.
Портим БД
Для экспериментов я буду использовать базу данных AdventureWorks, которая поставляется вместе с SQL Server. Если вы не устанавливали ее, при желании, можно скачать здесь. Перевожу ее в модель восстановления full:
убеждаюсь, что ошибок в ней еще нет:
и создаю полный бэкап:

В этой базе данных я создаю таблицу crash.
Поле типа varchar мы и будем портить, для того, чтобы проверить что произойдет, если вдруг SQL Server обнаружит в нем не те данные, которые он сам туда записал.
Прежде чем что-то испортить, надо это чем-то заполнить. Я забиваю в созданную таблицу левые данные.
Теперь делаю резервную копию журнала транзакций:
Теперь немного изменим данные:
Итак, все готово. Отсоединяем БД и открываем mdf-файл FAR'ом (или чем вам удобнее), ищем в нем строку «zzzzzzz» и заменяем несколько 'z' на произвольные символы:
Теперь, когда БД испорчена, подсоединяем ее. И, да, я помню, что в предыдущей статье было четко сказано, что отсоединять/присоединять БД не стоит. Но в нашем случае это абсолютно «безопасно» — база данных в «suspect» не упадет.
Ищем ошибки
Итак, испорченная БД успешно вернулась в строй. Снова запустим проверку целостности:
В результате то, чего мы ждали (обязательно запоминайте номера поврежденных страниц!):
- Смириться с потерей данных и выполнить DBCC CHECKDB('AdventureWorks', REPAIR_ALLOW_DATA_LOSS)
- Сделать бэкап активной части журнала транзакций и восстановить БД целиком — в результате потери данных не будет, но это займет продолжительное время
- Сделать бэкап активной части журнала транзакций и восстановить только одну(!), поврежденную, страницу
Восстанавливаем поврежденную страницу
В первую очередь нам надо сделать бэкап заключительного фрагмента журнала транзакций (tail backup). При этом, если у вас Enterprise Edition, вы можете не добавлять параметр NORECOVERY, который переведет БД в состояние «restoring», поскольку эта редакция поддерживает on-line восстановление страниц. Более того, если у вас резервные копии журнала транзакций выполняются на регулярной основе, чтобы не нарушать цепочку журналов, в редакции Enterprise Edition, вы можете сделать COPY_ONLY бэкап.
Я же иду по пути off-line восстановления и выполняю:

Теперь, можно восстанавливать поврежденную страницу. В первую очередь, используем полный бэкап (aw_full_ok1.bak):

В итоге, имеем:
Обратите внимание на то, что необходимо использовать опцию NORECOVERY, поскольку нам предстоит еще накатывать на нее бэкапы журнала транзакций.
и
Вроде бы все прошло успешно, запускаем DBCC CHECKDB и…
Восстановление прошло успешно.
Обратите внимание, что время простоя сокращается за счет того, что из полного бэкапа мы восстанавливаем не всю БД, а только поврежденные страницы (если бы я восстанавливал бэкап целиком — бэкап восстановился бы за 8,5 секунд, но, чем больше размер БД — тем больше будет разница во времени). Счастливчики с SQL Server Enterprise Edition, использующие on-line восстановление, так же сэкономят время на восстановлении из бэкапов лога, а при off-line восстановлении, увы, журналы будут обрабатываться целиком.
Стоит так же добавить, что в SQL Server 2005, 2008, 2008 R2 восстановление отдельной страницы возможно только с помощью T-SQL, в Denali появилась возможность делать это через GUI.
А если все-таки DBCC CHECKDB?
На всякий случай я решил проверить что сделает SQL Server, если я запущу DBCC CHECKDB с параметром REPAIR_ALLOW_DATA_LOSS. Все та же ошибка:
Сначала переводим БД в режим SINGLE_USER:
А затем, запускаем восстановление:
В итоге:
Repair: The page (1:20455) has been deallocated from object ID 1883153754, index ID 0, partition ID 72057594054246400, alloc unit ID 72057594061651968 (type In-row data).
Ага, SQL Server удалил «испорченную» страницу. Переводим БД в режим MULTI_USER, чтобы она стала доступной для всех и проверяем что пропало:
Учитывая, что размер страницы в SQL Server 8КБ, а для пользовательских данных доступно чуть меньше — то все закономерно, таблица «похудела» на 7 записей (в начале их было 99999). Поскольку на этой таблице не было кластерного индекса, данные могли храниться в произвольном порядке, т.е. мы даже не могли узнать какие данные будут потеряны.
Так почему, все-таки, не перевод?
Итак, почему это все-таки не перевод, а пост «по мотивам». Дело в том, что, в открытом доступе статьи «Page Restore» за авторством Gail Shaw нет. Есть такой раздел в книге SQL Server MVP Deep Dives vol.2, которая продается за довольно-таки ощутимые деньги (но, естественно, легко находится в интернетах) и я не уверен, что публиковать перевод — это эм… правильно что ли.
В общем, я прочитал статью, взял на заметку основные моменты, а потом уже сам писал текст и, попутно, проводил эксперимент по восстановлению. Надеюсь, кому-нибудь этот опыт был полезен.
И, господа, я искренне надеюсь, что если вы решите повторять этот эксперимент, то будете предельно осторожны (например, не будете эксперементировать с основной БД на production-сервере). Помните, что никакой ответственности за ваши действия я не несу.
Читайте также: