
1с blob тип данных
Аннотация: В рамках данной лекции будут рассмотрены следующие вопросы: общие сведения о хранилище Windows Azure Blob, модель данных Windows Azure Blob, REST - интерфейс.
Общие сведения
Аббревиатура BLOB расшифровывается как Binary Large Object, т.е. большой бинарный объект - массив двоичных данных. В СУБД BLOB - специальный тип данных , предназначенный, в первую очередь, для хранения медиа- информации и компилированного программного кода.
Blob - хранилище в Azure может быть представлено в виде специального табличного хранилища в "облаке". Windows Azure Blob расширяет табличное хранилище и рассчитано на хранение больших объемов информации. Разница между Table и Blob хранилищами заключается в следующем:
- Табличное хранилище для управления таблицами использует ключи секций и строк. Бинарное хранилище для управления использует контейнер хранения ( storage container ) и идентификатор ( blob ID ).
- Табличное хранилище может работать со всеми основными форматами данных, как то символы, строки, целые и действительные числа, XML и т.д. Бинарное хранилище рассчитано только на, очевидно из названия, бинарный тип данных, при этом данных хранятся в виде блоков (data chunks ).
Доступ к Blob - хранилищу осуществляется через пользовательскую учетную запись. Одна учетная запись может создать несколько Blob - контейнеров. В свою очередь, Blob - контейнер может включать в себя несколько Blob - объектов. (см. рис 18.1).

Модель данных
Рассмотрим модель данных Windows Azure Blob более детально. Выделим основные термины:
- Учетная запись. Любой доступ к Windows Azure Storage и его сервисам, осуществляется посредством учетной записи. Как уже отмечалось, одна учетная запись может иметь несколько Blob - контейнеров.
- Blob - контейнер. Контейнер группирует Blob - объекты. При этом политики использования данных задаются на уровне контейнера.
- Blob (blob - объект). Хранится в контейнере. Каждый объект может быть размером до 50 Гб и имеет уникальное строковое имя в рамках контейнера. С бинарными объектами могут быть ассоциированы метаданные (рис 18.1), задающиеся в виде пары "имя - значение" размером до 8Кб.
На рис 18.2 приведена структура данных Windows Azure Blob, полученная средствами MS SQL Server 2008.
Отметим ряд особенностей работы с бинарными объектами и контейнерами:
- контейнеры хранятся распределено;
- область действия одного контейнера ограничена учетной записью пользователя;
- при удалении контейнера, возможно возникновение задержек при повторном его создании, особенно при наличии большого количества объектов, т.е. до тех пор пока система не очистит blob - объекты попытки создать контейнер с тем же именем, что и удаляемый, будут вызывать ошибку;
- подтверждение команд создания и удаления контейнера возвращаются от сервера клиенту, даже в случае если данные процессы занимают длительное время.

REST - интерфейс Blob - объектов
Более полный перечень команд можно найти по ссылке в списке материалов для самостоятельного изучения.

Здравствуйте.
Этот материал призван обобщить и показать основные техники и приемы для работы с базами данных InterBase/FireBird из программ, запускаемых на платформе 1С. Почти все, что изложено здесь, так или иначе встречается в других интернет-источниках. Однако в этой статье материал достаточно полный. Возможно, что-то из заявленной темы и упущено, но все равно, изложенного материала (в моем понимании) достаточно для решения большинства задач (кстати, кое-что не получилось – может кто-нибудь подскажет решение, и можно будет дополнить материал). Кроме того, демонстрационный пример, приложенный к статье, может быть использован желающими в качестве каркаса для разработки собственных подобных программ. Несмотря на то, что большинство задач по доступу из 1С к сторонним базам ограничиваются необходимостью загрузить какие-либо данные из смежной информационной системы, мы покажем здесь более разнообразные варианты доступа к базам, в том числе различные виды записи информации в БД.
В этой публикации будет рассказано о том:
— как подключиться к серверу (базе) и отключиться при завершении работы;
— как выполнять SQL-запросы (принимать и передавать данные, в том числе и те, которые не могут быть размещены непосредственно в тексте запроса (длинные строки, BLOB-поля));
— как выполнять преобразование данных, в т.ч. текстовых кодировок, при передаче данных в базу и из базы;
— как обращаться к серверной логике базы (вызывать хранимые процедуры);
— как защитить свою программу от автоматического разрыва TCP-соединения сервером БД;
— прочие интересные приемы, связанные с программированием вообще (как сделать все вышеперечисленные действия удобно, надежно и переносимо).
Программа проверялась на версиях FireBird 1.5 и FireBird 2.1. Скорее всего, будет работать и для любой другой версии СУБД. Данный механизм доступа к базе использует технологию ADO. Соответственно, на компьютере, где запускается клиент 1С, должен быть установлен драйвер «Firebird_ODBC», а также клиентская библиотека «gds32.dll».
Полные исходные тексты программы приводить не буду (даже исходные тексты отдельных классов будут приведены с сокращениями). Для просмотра исходных текстов лучше открыть тестовый пример непосредственно в 1С – качество просмотра будет гораздо выше, чем то, что доступно средствами HTML-публикации.
Будем в качестве примера рассматривать несложную информационную систему, условно названную «Записная книжка». Она чем-то будет подобна справочнику, который можно создать в платформе. У нас будет справочник контактной информации. В справочнике будет дерево групп (каталогов) – можно будет создавать произвольное дерево любой вложенности. В качестве элементов такого справочника будут выступать так называемые «Карточки», т.е. собственно сами записи с контактной информацией. Кроме того, в этой информационной системе будут пользователи (учетные записи) со своими правами доступа. Поиска нет (только ввод данных и навигация по дереву групп). Какой-либо привязки пользователей к тем данным, что они вводили (наподобие поля ОсновнойОтветственный в документах типовых решений 1С) тоже нет, а также нет логирования (журнализации) действий пользователей. Для демонстрации работы с базой этого функционала достаточно, а еще более усложнять реализацию пользовательского интерфейса просто не хотелось.
Далее будем считать, что:
— «Текущая группа» — это группа, выбранная в дереве групп (в левой колонке);
— «Содержимое текущей группы» — это список групп и элементов, отображаемый в правой колонке;
— «Текущий объект текущей группы» — это группа или элемент, выбранный в правой колонке;
Все команды (добавить, редактировать, удалить, переместить) относятся к содержимому правой колонки (либо к текущей группе, либо к текущему элементу текущей группы) – как и в стандартном интерфейсе работы со справочниками 1С.
Главное меню и панель инструментов содержат следующие команды:
| Изобр. | Название команды | Описание |
|---|---|---|
| «База»→«Подключение» | Выполняет подключение к базе (закрывает предыдущее подключение, если оно было) | |
 | «База»→«Выход» | Выход из программы |
 | «Действия»→«Добавить» | Создать новый элемент (карточку) в текущей группе справочника. |
 | «Действия»→«Новая группа» | Создать новую группу в текущей группе справочника. |
 | «Действия»→«Скопировать» | Создать новый объект в текущей группе справочника на основе данных текущего выделенного объекта. Что именно создается (группа или карточка) зависит от того, какой объект был выделен в текущей группе . |
 | «Действия»→«Изменить» | Открыть на редактирование текущий объект текущей группы (группу или карточку). |
 | «Действия»→«Удалить» | Удалить текущий объект текущей группы (группу или карточку). |
 | «Действия»→«Переместить в группу» | Переместить в другую группу текущий объект текущей группы (группу или карточку). |
 | «Действия»→«Обновить» | Заново перезагрузить все данные (и дерево групп и список содержимого текущей группы). |
| «Настройки»→«Смена пароля» | Смена пароля текущего пользователя | |
| «Настройки»→«Список пользователей» | Редактирование списка пользователей базы. | |
| «Настройки»→«Профили подключения» | Редактирование профилей подключения к базам |
Окно программы до подключения к базе:


Диалог выполнения подключения:
(Команда: «База»→«Подключение»)

Окно программы после подключения к базе:

Диалог настройки профилей подключения к базам:
(Команда: «Настройки»→«Профили подключения»)

Диалог смены пароля:
(Команда: «Настройки»→«Смена пароля»)

Настройки списка пользователей:
(Команда: «Настройки»→«Список пользователей»)

Редактирование группы справочника контактов:
(Команды: «Действия»→«Новая группа», «Действия»→«Скопировать», «Действия»→«Изменить»)

Редактирование элемента справочника контактов (карточки):
(Команды: «Действия»→«Добавить», «Действия»→«Скопировать», «Действия»→«Изменить»)

Диалог выбора группы в дереве групп:
Используется для указания родительской группы в диалогах редактирования группы и карточки, а также для указания группы на значения при перемещении текущего объекта текущей группы (объекта, выбранного в правом списке главного окна программы) в новую группу.
Основные сущности системы:
1. Справочник пользователей системы (учетных записей). Состоит только из элементов (учетных записей). Соответственно в базе представляется одной таблицей.
2. Собственно сам целевой справочник контактной информации. Состоит из групп (дерево справочника) и элементов (карточек). В базе справочник будет представлен отдельной таблицей групп (в ней будет храниться дерево уровней справочника) и отдельной таблицей элементов (в ней будут храниться сами карточки с контактами).
В нашей системе есть следующие информационные сущности:
— группа справочника контактов (набор групп, образующих дерево (поддерево) групп – полное или частичное представление данных таблицы GROUPS);
— элемент (карточка) справочника контактов (набор карточек – полное или частичное представление данных таблицы CARDS);
— учетная запись системы (набор учетных записей – полное или частичное представление данных таблицы USERS)
Модель представлена в коде 1С следующими классами:
— BaseObj (БазоваяСущность) – класс – абстрактный родитель для всех остальных классов из данной группы. Содержит общие поля и методы.
— ObjGroup (СущностьГруппа) – потомок от BaseObj, представляет собой реализацию сущности «группа справочника контактов».
— ObjCard (СущностьКарточка) – потомок от BaseObj, представляет собой реализацию сущности «элемент справочника контактов».
— ObjUser (СущностьПользователь) – потомок от BaseObj, представляет собой реализацию сущности «пользователь системы».
— ObjSet (НаборОбъектов) – тоже потомок от BaseObj, но является не сущностью, а универсальной коллекцией сущностей, которой можно представить набор из объектов любого типа (ObjGroup, ObjCard, ObjUser). Естественно, что нельзя смешивать в одном наборе сущности разных типов.
Эта часть является сборной солянкой всевозможных особенностей SQLite. Я собрал здесь (на мой взгляд) наиболее важные темы, без понимания которых невозможно постичь SQLite нирвану.
Поскольку, опять-таки, информации очень много, то формат статьи будет такой: небольшая вводная в интересную тему и ссылка на родной сайт, где подробности. Сайт, увы, на английском.
Использование SQLite в многопоточных приложениях
SQLite может быть собран в однопоточном варианте (параметр компиляции SQLITE_THREADSAFE = 0).
В этом варианте его нельзя одновременно использовать из нескольких потоков, поскольку полностью отсутствует код синхронизации. Зачем? Для бешеной скорости.
Проверить, есть ли многопоточность можно через вызов sqlite3_threadsafe(): если вернула 0, то это однопоточный SQLite.
По умолчанию, SQLite собран с поддержкой потоков (sqlite3.dll).
Есть два способа использования многопоточного SQLite: serialized и multi-thread.
Serialized (надо указать флаг SQLITE_OPEN_FULLMUTEX при открытии соединения). В этом режиме потоки могут как угодно дергать вызовы SQLite, никаких ограничений. Но все вызовы блокируют друг друга и обрабатываются строго последовательно.
Multi-thread (SQLITE_OPEN_NOMUTEX). В этом режиме нельзя использовать одно и то же соединение одновременно из нескольких потоков (но допускается одновременное использование разных соединений разными потоками). Обычно используется именно этот режим.
Формат данных
База данных SQLite может хранить (текстовые) данные в UTF-8 или UTF-16.
Набор вызовов API состоит из вызовов, которые получают UTF-8 (sqlite3_XXX) и вызовов, которые получают UTF-16 (sqlite3_XXX16).
Если тип данных интерфейса и соединения не совпадает, то выполняется конвертация «на лету».
Всегда используйте UTF-8.
Поддержка UNICODE
И некоторые собирают SQLite DLL уже с ним.
Типы данных и сравнение значений
Как уже говорилось, SQLIte позволяет записать в любой столбец любое значение.
Значение внутри БД может принадлежать к одному из следующих типов хранения (storage class):
NULL,
INTEGER (занимает 1,2,3,4,6 или 8 байт),
REAL (число с плавающей точкой, 8 байт в формате IEEE),
TEXT (строка в формате данных базы, обычно UTF-8),
BLOB (двоичные данные, хранятся «как есть»).
Порядок сортировки значений разных типов:
— NULL меньше всего (включая другой NULL);
— INTEGER и REAL меньше любого TEXT и BLOB, между собой сравниваются арифметически;
— TEXT меньше любого BLOB, между собой сравниваются на базе своих collation;
— BLOB-ы сравниваются между собой через memcmp().
SQLite выполняет неявные преобразования типов «на лету» в нескольких местах:
— при занесении значения в столбец (тип столбца задает рекомендацию по преобразованию);
— при сравнении значений между собой.
Столбец может иметь следующие рекомендации приведения типа: TEXT, NUMERIC, INTEGER, REAL, NONE.
Значения BLOB и NULL всегда заносятся в любой столбец «как есть».
В столбец TEXT значения TEXT заносятся «как есть», значения INTEGER и REAL становятся строками.
В столбец NUMERIC, INTEGER числа записываются «как есть», а строки становятся числами, если _могут_ (то есть допустимо обратное преобразование «без потерь»).
Для столбца REAL правила похожи на INTEGER(NUMERIC); отличие в том, что все числа представлены в формате с плавающей запятой.
В столбец NONE значения заносятся «как есть» (этот тип используется по умолчанию, если не задан другой).
При сравнении значений разного типа между собой может выполняться дополнительное преобразование типов.
При сравнении числа со строкой, если строка может быть преобразована в число «без потерь», она становится числом.
Отмечу здесь, что в SQLite в уникальном индексе может быть сколько угодно NULL значений (с этим согласен Oracle и не согласен MS SQL).
База данных в памяти
Если в вызове sqlite3_open() передать имя файла как ":memory:", то SQLite создаст соединение к новой (чистой) БД в памяти.
Это соединение абсолютно неотличимо от соединения к БД в файле по логике использования: доступен тот же набор SQL команд.
Увы, не существует возможности открыть два соединения к одной и той же БД в памяти.
UPD: Уже, оказывается, можно открыть два соединения к одной БД в памяти.
Присоединение одновременно к нескольким БД
Чтобы открыть соединение к БД используется вызов sqlite3_open().
В любой момент времени мы можем к открытому соединению присоединить еще до 10 баз данных через SQL команду ATTACH DATABASE.
Теперь все таблицы БД в файле db1.sqlite3 стали прозрачно доступны в нашем соединении.
Для разрешения конфликтов имен следует использовать имя присоединения (основная база называется «main»):
Ничего не мешает присоединить к БД новую базу в памяти и использовать ее для кэширования и пр.
Это очень полезная возможность. Присоединяемые БД должны иметь формат данных такой же, как и у основной БД, иначе — ошибка.
Временная база данных
Передайте пустую строку вместо имени файла в sqlite3_open() и будет создана временная БД в файле на диске. Причем, после закрытия соединения к БД, она будет удалена с диска.
Тонкие настройки БД через команду PRAGMA
SQL команда PRAGMA служит для задания всевозможных настроек у соединения или у самой БД:
Настройку соединения (очевидно) следует проводить сразу после открытия и до его использования.
Полное описание всех параметров находится здесь.
Остановлюсь на важнейших вещах.
Журнал и фиксация транзакций
Вот и подошли к теме, овладение которой сразу переводит вас на третий уровень магистра SQLite.
SQLite тщательно блюдет целостность данных в БД (ACID), реализуя механизм изменения данных через транзакции.
Кратко о транзакциях: транзакция либо полностью накатывается, либо полностью откатывается. Промежуточных состояний быть не может.
Если вы не используете транзакции явно (BEGIN; . ; COMMIT;), то всегда создается неявная транзакция. Она стартует перед выполнением команды и коммитится сразу после.
Отсюда, кстати, и жалобы на «медленность» SQLite. SQLite может вставлять и до 50 тыс записей в секунду, но фиксировать транзакций он не может больше, чем ~ 50 в секунду.
Именно поэтому, не получается вставлять записи быстро, используя неявную транзакцию.
При настройках по умолчанию SQLite гарантирует целостность БД даже при отключении питания в процессе работы.
Достигается подобное изумительное поведение ведением журнала (специального файла) и хитроумным механизмом синхронизации изменений на диске.
Кратенько обновление данных в БД работает так:
— до любой модификации БД SQLite сохраняет изменяемые страницы из БД в отдельном файле (журнале), то есть просто копирует их туда;
— убедившись, что копия страниц создана, SQLite начинает менять БД;
— убедившись, что все изменения в БД «дошли до диска» и БД стала целостной, SQLite стирает журнал.
Подробно атомарность механизма транзакций описана тут.
Если SQLite открывает соединение к БД и видит, что журнал уже есть, он соображает, что БД находится в незавершенном состоянии и автоматически откатывает последнюю транзакцию.
То есть механизм восстановления БД после сбоев, фактически, встроен в SQLite и работает незаметно для пользователя.
По умолчанию журнал ведется в режиме DELETE .
Это означает, что файл журнала удаляется после завершения транзакции. Сам факт наличия файла с журналом в этом режиме означает для SQLite, что транзакция не была завершена, база нуждается в восстановлении. Файл журнала имеет имя файла БД, к которому добавлено "-journal".
В режиме TRUNCATE файл журнала обрезается до нуля (на некоторых системах это работает быстрее, чем удаление файла).
В режиме PERSIST начало файла журнала забивается нулями (при этом его размер не меняется и он может занимать кучу места).
В режиме MEMORY файл журнала ведется в памяти и это работает быстро, но не гарантирует восстановление базы при сбоях (копии данных-то нету на диске).
А можно и совсем отключить журнал (PRAGMA journal_mode = OFF). В этой ситуации перестает работать откат транзакций (команда ROLLBACK) и база, скорее всего, испортится, если программа будет завершена аварийно.
Для базы данных в памяти режим журнала может быть только либо MEMORY, либо OFF.
Вернемся немного назад. Как же SQLite «убеждается», что база всегда будет целостной?
Мы знаем, что современные системы используют хитроумное кэширование для повышения производительности и могут откладывать запись на диск.
Допустим, SQLite завершил запись в БД и хочет стереть файл журнала, чтобы отметить факт фиксации транзакции.
А вдруг файл сотрется раньше, чем обновится БД?
Если в этот промежуток времени отключится питание, то журнала уже не будет, а БД еще не будет целостной — потеря данных!
Короче говоря, хитроумный механизм фиксации изменений должен полагаться на некоторые гарантии со стороны дисковой системы и ОС.
PRAGMA synchronous задает степень «паранойи» SQLite на это счет.
Режим OFF (или 0) означает: SQLite считает, что данные фиксированы на диске сразу после того как он передал их ОС (то есть сразу после вызова соот-го API ОС).
Это означает, что целостность гарантирована при аварии приложения (поскольку ОС продолжает работать), но не при аварии ОС или отключении питания.
Режим синхронизации NORMAL (или 1) гарантирует целостность при авариях ОС и почти при всех отключениях питания. Существует ненулевой шанс, что при потере питания в самый неподходящий момент база испортится. Это некий средний, компромисный режим по производительности и надежности.
Режим FULL гарантирует целостность всегда и везде и при любых авариях. Но работает, разумеется, медленнее, поскольку в определенных местах делаются паузы ожидания. И это режим по умолчанию.
Итак, осталась неохваченной только тема журнала типа WAL.
Режим журнала WAL
По умолчанию, режим журнала БД всегда «возвращается» в DELETE. Допустим, мы открыли соединение к БД и установили режим PERSIST. Изменили данные, закрыли соединение.
На диске остался файл журнала (начало которого забито нулями).
Открываем соединение к БД снова. Если не задать режим журнала в этом соединении, он опять будет работать в DELETE. Как только мы обновим данные, механизм фиксации транзакций сотрет файл журнала.
Режим журнала WAL работает иначе — он «постоянный». Как только мы перевели базу в режим WAL, она останется в этом режиме, пока ей явно не поменяют режим журнала на другой.
Итак, зачем он нужен?
Изначально SQLite проектировалась как встроенная БД. Архитектура разделения одновременного доступа к данным была устроена примитивно: одновременно несколько соединений могут читать БД, а вот записывать в данный момент времени может только одно соединение. Это, как минимум, означает, что пишущее соединение ждет «освобождения» БД от читающих. При попытке записать в «занятую» БД приложение получает ошибку SQLITE_BUSY (не путать с SQLITE_LOCKED!). Достигается этот механизм разделения доступа через API блокировки файлов (которые плохо работают на сетевых дисках, поэтому там не рекомендуется использовать SQLite; узнать больше )
Но есть и недостатки:
— требуется некоторые дополнительные ништяки от ОС (unix и Windows имеют эти ништяки);
— БД занимает несколько файлов (файлы «XXX-wal» и «XXX-shm»);
— плохо работает на больших транзакциях (условно, если транзакция больше 50 Мбайт);
— нельзя открыть такую БД в режиме «только чтение»;
— возникает дополнительная операция checkpoint.
Фактически, в режиме WAL данные БД разделяются между БД и файлом журнала. Операция checkpoint переносит данные в БД. По умолчанию, это делается автоматически, если журнал занял 1000 страниц БД.
То есть, идут быстрые COMMIT-ы и вдруг какой-то COMMIT задумался и начал делать checkpoint. Если такое поведение нежелательно, можно делать checkpoint вручную (когда все спокойно), можно это делать и в отдельном процессе.
Пределы
Несмотря на миниатюрность, SQLite в реальности не накладывает серьезных ограничений на размеры полей, таблиц или БД.
По умолчанию, BLOB или строкое значение могут занимать 1 Гбайт и это же ограничение размера одной записи (можно поднять до 2^31 — 1, параметр SQLITE_MAX_LENGTH).
Количество столбцов: 2000 (можно поднять до 32767, SQLITE_MAX_COLUMN).
Размер SQL оператора: 1 МБайт (1073741824 байт, SQLITE_MAX_SQL_LENGTH).
Одновременный join: 64 таблицы.
Присоединить баз к соединению: 10 (до 62, SQLITE_MAX_ATTACHED)
Максимальное количество страниц в БД: 1073741823 (до 2147483646, SQLITE_MAX_PAGE_COUNT).
Если задать размер страницы 65636 байт, то максимальный размер БД будет примерно 14 Терабайт.
Максимальное число записей в таблице: 2^64 — 1, но на практике, конечно, ограничение размера вступит раньше.
Существует два текстовых типа данных: CHARACTER(n) (в сокращенном варианте CHAR(n) )и CHARACTER VARYING(n) (в сокращенном варианте VAR CHAR(n) ).
n - указывает количество символов в поле . В обоих типах n может быть от 1 до 32767 символов (32 Кбайт). Если n не указать, по умолчанию будет присвоено число 1. Пример создания полей:
В первом случае будет создано поле размером 1 символ, во втором случае в поле можно сохранить текст размером до 255 символов. Между этими типами данных есть отличия. Тип CHAR предназначен для хранения текста фиксированной длины. Другими словами, если мы определим поле в 10 символов, а запишем только 5, то текст будет дополнен завершающими пробелами до полной длины. Тип VARCHAR хранит текст переменной длины, и возвращает сохраненный текст без завершающих пробелов. Тем самым, использование типа VARCHAR в большинстве случаев является предпочтительным.
Еще важными факторами при работе с текстовыми полями является кодировка символов и порядок их сортировки. Как мы знаем из прошлой лекции, при создании базы данных можно указать кодировку " по умолчанию", для кириллицы предпочтительней будет кодировка WIN1251. При этом все создаваемые текстовые поля будут иметь эту кодировку, в чем несложно убедиться, выполнив описанный выше запрос , и посмотрев вкладку Metadata созданной таблицы:
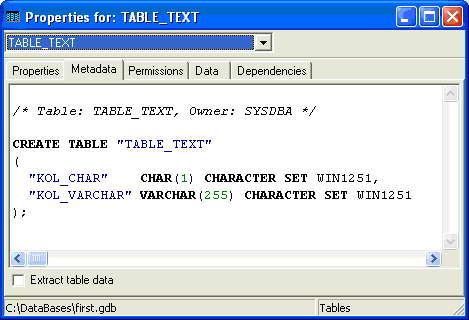
Как видно из рисунка, с помощью оператора CHARACTER SET кодировку можно указать явно при описании поля :
Если кодировка указана явно, именно она и будет использована при создании столбца таблицы.
Для символьных полей также возможно указывать порядок сортировки COLLATE . Этот порядок определяет способ, по которому будут сортироваться и сравниваться текстовые данные при выводе их оператором SELECT. Для кодировки WIN1251 это может быть сортировка WIN1251 или PXW_CYRL . В первом случае русские символы сортируются как
что не очень удобно. Сортировка PXW_CYRL предпочтительней, она выводит русские символы в таком порядке:
Тип данных BLOB
BLOB ( Binary Large Object - Большой двоичный объект ) - Поле неограниченного размера, может содержать любой тип двоичных данных, например, файл с фотографией, мелодией или цифровой книгой, или просто большой текст (аналог MEMO ). Пример определения поля:
Поля BLOB несколько отличаются по способу хранения данных от других типов данных. Все остальные поля записи хранятся на одной странице рядом, одно за другим. Поле BLOB сохраняет на этой странице только идентификатор записи, а сама запись хранится на отдельной странице (страницах). Таким образом, оказалось возможным хранить данные большого размера, не ухудшая в целом работу всей БД .
У этого типа есть возможность указывать явно подтип : целое число , определяющее тип хранимых в поле данных. По умолчанию, 0 указывает на двоичные данные и 1 указывает на ASCII - текст. Программист может указывать собственные типы, используя отрицательные значения. Подтип указывается оператором SUB_TYPE :
Однако заметим, что эта возможность InterBase практически не используется программистами.
Столбцы - массивы
В InterBase столбец любого типа, кроме BLOB , может быть объявлен, как массив . Такие столбцы, вместо единичного значения записи, содержат массив значений одинакового типа. Доступ к каждому значению возможен с помощью указания индекса. По умолчанию, нумерация элементов массива начинается с 1, однако программист может явно указать границы элементов:
В этом примере была объявлена таблица из двух столбцов-массивов. В первом случае объявлен массив целых чисел с диапазоном от 1 до 10 элементов, во втором случае объявлен двухмерный массив вещественных чисел с указанными программистом границами элементов. Это эквивалентно объявлению в Delphi двух переменных-массивов:
Однако стандарт SQL -92, поддерживаемый InterBase , не поддерживает столбцов-массивов, поэтому доступ к отдельным значениям возможен только с помощью низкоуровневых функций API InterBase . Практически же такие столбцы используют крайне редко, ведь проще объявить, например, три поля с целыми числами, чем одно целое поле - массив , имеющее три элемента. В этом курсе мы не будем рассматривать работу полей-массивов, однако знать о существовании такого типа нужно. Любителям выбирать путь посложней, рекомендуем обратиться к справочнику и технической документации InterBase .
Логический тип
Как уже говорилось выше, в InterBase не поддерживаются типы Boolean. Вместо этого предлагается использовать тип CHAR(1), который создает односимвольный столбец, и вводить значения типа T/F , Y/N , Д/Н, 1/0, +/- и т.п. Проверка логики и правильности ввода значения возлагается на клиентское приложение .
Домены
Доменом в InterBase называется заранее созданное описание столбца, которое хранится отдельно от таблиц. Зачем это нужно? Предположим, планируемая база данных будет содержать десятки таблиц. Предположим далее, что во многих из этих таблиц потребуются поля с фамилией, именем и отчеством каких то людей. Можно было бы описать эти поля обычным образом, например (следующий запрос вводить в Interactive SQL не нужно):
Но обратите внимание на то, что нам пришлось много раз повторить одно и то же описание типа поля. А если такой же тип будет содержаться и в других таблицах? Гораздо предпочтительней создать домен , который затем и указывать при описании поля . Домен создается таким образом:
Выполните последний запрос в Interactive SQL , затем в дереве серверов утилиты IBConsole выделите раздел Domains и вы увидите созданный нами домен . Теперь создание таблицы Table_Firma существенно упростится:
Этот же домен можно использовать в описании полей любой таблицы в пределах текущей базы данных .
Тип данных BLOB предназначен для хранения большого количества данных переменного размера. Тип BLOB позволяет хранить данные, которые не могут быть помещены в поля других типов, - например, картинки, музыкальные файлы, видеофрагменты и т. д.
Чтобы определить самое простое поле типа BLOB в таблице, не нужно ничего сверх того, что обычно требуется для определения поля любого элементарного типа:
CREATE TABLE testBLOB(
В результате будет создано поле myBlobField, в котором можно хранить данные большого размера. Но несмотря на то что поля BLOB по способу определения никак не отличаются от других, реализация их внутри базы данных значительно отличается. He-BLOB-поля расположены на странице данных (см. главу "Структура базы данных InterBase" (ч. 4)) рядом друг с другом, а в случае BLOB на странице данных хранится только идентификатор BLOB, а сам BLOB располагается на специальной странице. Именно такая организация данных позволяет хранить данные нефиксированного размера.
У типа BLOB имеется возможность определять набор нескольких подтипов и специальных процедур, называемых фильтрами (BLOB filters), для работы с этими подтипами. Существует несколько предопределенных подтипов BLOB, которые встроены в InterBase. Все эти подтипы имеют неотрицательные номера, например subtype 0 - это данные неопределенного типа, subtype 1 - текст, subtype 2 - BLR (Binary Language Representation, см. глоссарий и главу "Структура базы данных InterBase") и т. д. Пользователь также может определять свои подтипы BLOB, которые могут иметь отрицательные значения. Каждому типу может быть поставлен в соответствие фильтр, который преобразует поле этого подтипа в другой подтип.
Надо отметить, что использование BLOB-полей обычно служит альтернативой хранению внешних относительно базы данных файлов. Что касается фильтров BLOB, то они используются достаточно редко по причине своей ориентации на узкий класс задач.
Перемещение данных из базы данных Access 2007 на узел SharePoint
Перемещение данных из базы данных Access 2007 на узел SharePoint Потребности многих приложений Access 2007 превышают простую потребность в управлении и сборе данных. Часто такие приложения используются многими пользователями организации, а значит, имеют повышенные потребности в
Новые функции API для работы с Blob и массивами
Новые функции API для работы с Blob и массивами Были добавлены 10 новых функций InterBase API для поддержки длинных имен объектов. Ниже представлены новые вызовы
ГЛАВА 12. BLOB и массивы.
ГЛАВА 12. BLOB и массивы. Типы BLOB (Binary Large Objects, большие двоичные объекты) являются сложными структурами, используемыми для хранения дискретных объектов данных переменного размера, который может быть очень большим. Они являются "сложными" в том смысле, что Firebird сохраняет эти
Сегменты BLOB
Сегменты BLOB Данные BLOB хранятся в различных форматах в обычном столбце данных и вне столбца. Они хранятся в виде сегментов на одной или более страницах базы данных. Сегменты являются дискретными фрагментами неформатированных данных, которые обычно создаются приложением
Когда использовать типы BLOB
Когда использовать типы BLOB BLOB более предпочтительны, чем символьные типы, для хранения текстовых данных неопределенно большой длины. Поскольку он преобразуется в "бессмысленные фрагменты", к нему не относится ограничение размера строк в 32 Кбайта, пока клиентское
Фильтры BLOB
Фильтры BLOB В главе 12 мы коснулись специального типа внешних функций, которые могут быть использованы в Firebird для преобразования данных BLOB между двумя форматами, способными представлять совместимые данные. Фильтры BLOB являются определенными пользователем служебными
Написание фильтров BLOB
Написание фильтров BLOB Написание фильтров BLOB требует точно таких же усилий по управлению памятью и потоками, а также того же порядка действий, что и другие внешние функции, а именно:1. Напишите фильтры и скомпилируйте их в объектные коды.2. Создайте совместно используемую
Функции BLOB[159]
Функции BLOB[159] FBUDF STRING2BLOB(VALUE) Linux, Win32 Принимает поле строки (столбец, переменную, выражение) и возвращает текст BLOB Аргументы VALUE: столбец или выражение, результатом вычисления которого является значение типа VARCHAR 300 символов или меньше Возвращаемое значение Текст
Читайте также: